장 – 5
C 프로그래밍 소개
소개
'C'는 오늘날 컴퓨터 세계에서 가장 인기 있는 컴퓨터 언어 중 하나입니다. 'C' 프로그래밍 언어는 1972년 Bell Research Labs의 Brian Kernighan과 Dennis Ritchie가 설계 및 개발했습니다.
'C'는 레지스터, I/O 슬롯 및 절대 주소와 같은 거의 모든 기계 내부에 프로그래머가 액세스할 수 있도록 특별히 만든 언어입니다. 동시에 'C'는 매우 복잡한 다중 프로그래머 프로젝트를 조직적이고 시기적절한 방식으로 구성하는 데 필요한 만큼의 데이터 처리 및 프로그래밍된 텍스트 모듈화를 허용합니다.
이 언어는 원래 UNIX에서 실행되도록 의도되었지만 IBM PC 및 호환되는 MS-DOS 운영 체제에서 실행하는 데 큰 관심이 있었습니다. 표현의 단순성, 코드의 간결함, 광범위한 적용 가능성으로 인해 이 환경에 탁월한 언어입니다.
또한 C 컴파일러를 작성하기 쉽고 간편하기 때문에 일반적으로 마이크로컴퓨터, 미니컴퓨터, 메인프레임을 비롯한 모든 새 컴퓨터에서 사용할 수 있는 최초의 고급 언어입니다.
데이터 복구 프로그래밍에서 C를 사용하는 이유
오늘날의 컴퓨터 프로그래밍 세계에는 많은 고급 언어를 사용할 수 있습니다. 이러한 언어는 대부분의 프로그래밍 작업에 적합한 많은 기능을 갖추고 있습니다. 그러나 C가 데이터 복구, 시스템 프로그래밍, 장치 프로그래밍 또는 하드웨어 프로그래밍을 위한 프로그래밍을 기꺼이 수행하려는 프로그래머의 첫 번째 선택인 몇 가지 이유가 있습니다.
- C는 전문 프로그래머가 선호하는 인기 있는 언어입니다. 따라서 다양한 C 컴파일러와 유용한 액세서리를 사용할 수 있습니다.
- C는 이식 가능한 언어입니다. 한 컴퓨터 시스템용으로 작성된 C 프로그램은 수정이 거의 또는 전혀 없이 다른 시스템에서 컴파일 및 실행할 수 있습니다. C 컴파일러에 대한 일련의 규칙인 C에 대한 ANSI 표준에 의해 이식성이 향상되었습니다.
- C를 사용하면 프로그래밍에서 모듈을 폭넓게 사용할 수 있습니다. C 코드는 함수라는 루틴으로 작성할 수 있습니다. 이러한 함수는 다른 애플리케이션이나 프로그램에서 재사용할 수 있습니다. 이전에 다른 응용 프로그램 프로그래밍에서 개발한 것과 동일한 모듈을 만들기 위해 새 응용 프로그램 프로그래밍에 추가 노력을 기울일 필요가 없습니다.
이 기능은 변경이나 약간의 변경 없이 새 프로그램에서 사용할 수 있습니다. 데이터 복구 프로그래밍의 경우 다른 프로그램의 다른 응용 프로그램에서 동일한 기능을 여러 번 실행해야 할 때 이 품질이 매우 도움이 됩니다.
- C는 강력하고 유연한 언어입니다. 이것이 C가 운영 체제, 워드 프로세서, 그래픽, 스프레드시트, 심지어 다른 언어용 컴파일러와 같은 다양한 프로젝트에 사용되는 이유입니다.
- C는 언어 기능이 구축되는 기반 역할을 하는 키워드라고 하는 소수의 용어만 포함하는 몇 개의 단어로 구성된 언어입니다. 예약어라고도 하는 이러한 키워드는 더 강력하고 프로그래밍의 넓은 영역을 제공하며 프로그래머가 C로 모든 유형의 프로그래밍을 수행할 수 있도록 합니다.
C에 대해 아무것도 모른다고 가정하겠습니다.
나는 당신이 C 프로그래밍에 대해 아무것도 모르고 프로그래밍에 대해 전혀 모른다고 가정합니다. C의 가장 기본적인 개념부터 시작하여 포인터, 구조 및 동적 할당에 대한 일반적으로 위협적인 개념을 포함하여 높은 수준의 C 프로그래밍에 대해 설명하겠습니다.
이러한 개념을 완전히 이해하려면 특히 이해하기 쉽지 않지만 매우 강력한 도구이기 때문에 상당한 시간과 노력이 필요합니다.
C 프로그래밍은 어셈블리 언어를 사용해야 할 수도 있지만 프로그램을 작성하기 쉽고 유지 관리하기 쉽게 유지하려는 영역에서 엄청난 자산입니다. 이러한 경우 C 코딩으로 절약되는 시간은 엄청날 수 있습니다.
C 언어는 프로그램이 한 구현에서 다른 구현으로 이동할 때 좋은 기록을 남기지만 다른 컴파일러를 사용하려고 할 때마다 발견하게 될 컴파일러의 차이점이 있습니다.
대부분의 차이점은 MS-DOS를 사용할 때 DOS BIOS 호출과 같은 비표준 확장을 사용할 때 분명해 지지만 이러한 차이점도 신중하게 프로그래밍 구성을 선택하면 최소화할 수 있습니다.
C 프로그래밍 언어가 광범위한 컴퓨터에서 사용할 수 있는 매우 대중적인 언어가 되고 있다는 것이 분명해졌을 때, 관련 개인 그룹이 만나 C 프로그래밍 언어 사용에 대한 표준 규칙 세트를 제안했습니다.
이 그룹은 소프트웨어 산업의 모든 부문을 대표하며 많은 회의와 많은 예비 초안을 거쳐 마침내 C 언어에 대한 허용 가능한 표준을 작성했습니다. ANSI(American National Standards Institute)에서 승인했으며, 및 국제 표준 기구(ISO)에 의해 수행됩니다.
어떤 그룹이나 사용자에게 강요되는 것은 아니지만 널리 받아들여지기 때문에 컴파일러 작성자가 표준 준수를 거부하는 것은 경제적인 자살이 될 것입니다.
이 책에 쓰여진 프로그램은 주로 IBM-PC나 호환 가능한 컴퓨터에서 사용하기 위한 것이지만 ANSI 표준에 매우 근접하기 때문에 모든 ANSI 표준 컴파일러와 함께 사용할 수 있습니다.
시작하겠습니다
어떤 언어로든 무엇이든 하고 프로그래밍을 시작하기 전에 식별자 이름을 지정하는 방법을 알아야 합니다. 식별자는 모든 변수, 함수, 데이터 정의 등에 사용됩니다. C 프로그래밍 언어에서 식별자는 영숫자 문자의 조합으로, 첫 번째는 알파벳 또는 밑줄이고 나머지는 다음 문자의 조합입니다. 알파벳, 숫자 또는 밑줄.
식별자의 이름을 지정할 때 두 가지 규칙을 염두에 두어야 합니다.
- 알파벳 문자의 경우가 중요합니다. C는 대소문자를 구분하는 언어입니다. 즉, 복구는 복구와 다르고 복구는 앞서 언급한 두 가지와 다릅니다.
- ANSI-C 표준에 따르면 최소 31개의 중요한 문자를 사용할 수 있으며 ANSI-C를 준수하는 컴파일러에서 중요한 것으로 간주됩니다. 31개보다 많은 문자가 사용되면 31번째 이후의 모든 문자는 지정된 컴파일러에서 무시될 수 있습니다.
키워드
C에서 키워드로 정의된 32개의 단어가 있습니다. 이들은 사전 정의된 용도를 가지며 C 프로그램에서 다른 목적으로 사용할 수 없습니다. 그들은 프로그램 컴파일을 돕기 위해 컴파일러에서 사용됩니다. 항상 소문자로 작성됩니다. 전체 목록은 다음과 같습니다.
| auto |
break |
case |
char |
| const |
continue |
default |
do |
| double |
else |
enum |
extern |
| float |
for |
goto |
if |
| int |
long |
register |
return |
| short |
signed |
sizeof |
static |
| struct |
switch |
typedef |
union |
| unsigned |
void |
volatile |
while |
여기에서 C의 마법을 볼 수 있습니다. 32개 키워드의 멋진 컬렉션은 다양한 응용 프로그램에서 널리 사용됩니다. 모든 컴퓨터 프로그램에는 데이터와 프로그램이라는 두 가지 엔터티를 고려해야 합니다. 그들은 서로에 대한 의존도가 높으며 둘 모두에 대한 세심한 계획은 잘 계획되고 잘 작성된 프로그램으로 이어집니다.
간단한 C 프로그램부터 시작하겠습니다.
/* C를 배우기 위한 첫 번째 프로그램 */
#include <stdio.h>
void main()
{
printf("This is a C program\n"); // printing a message
}
프로그램은 매우 간단하지만 몇 가지 주의할 점이 있습니다. 위의 프로그램을 살펴보자. /* 및 */ 안에 있는 모든 것은 주석으로 간주되며 컴파일러에서 무시됩니다. 다른 댓글에 댓글을 포함해서는 안 되므로 다음과 같은 것은 허용되지 않습니다.
/* 이것은 /* 주석 */ 잘못된 주석 내부 */
한 줄 내에서 작동하는 문서화 방법도 있습니다. //를 사용하여 해당 줄에 작은 문서를 추가할 수 있습니다.
모든 C 프로그램에는 main이라는 함수가 포함되어 있습니다. 이것이 프로그램의 시작점입니다. 모든 함수는 값을 반환해야 합니다. 이 프로그램에서 main 함수는 반환 값을 반환하지 않으므로 void main을 작성했습니다. 이 프로그램을 다음과 같이 작성할 수도 있습니다.
/* C를 배우는 첫 번째 프로그램 */
#include <stdio.h>
main()
{
printf("This is a C program\n"); // printing a message
return 0;
}
두 프로그램은 동일하고 동일한 작업을 수행합니다. 두 프로그램의 결과는 화면에 다음 출력을 인쇄합니다.
이것은 C 프로그램입니다
#include<stdio.h> 를 사용하면 프로그램이 컴퓨터의 화면, 키보드 및 파일 시스템과 상호 작용할 수 있습니다. 거의 모든 C 프로그램의 시작 부분에서 찾을 수 있습니다.
main()은 함수의 시작을 선언하고 두 개의 중괄호는 함수의 시작과 끝을 표시합니다. C에서 중괄호는 함수나 루프 본문에서와 같이 문을 그룹화하는 데 사용됩니다. 이러한 그룹화를 복합 문 또는 블록이라고 합니다.
printf("This is a C program\n"); 화면에 단어를 출력합니다. 인쇄할 텍스트는 큰따옴표로 묶습니다. 텍스트 끝에 있는 \n은 출력의 일부로 새 줄을 인쇄하도록 프로그램에 지시합니다. printf() 함수는 출력의 모니터 표시에 사용됩니다.
대부분의 C 프로그램은 소문자입니다. 일반적으로 나중에 설명할 전처리기 정의에 사용되는 대문자나 문자열의 일부로 따옴표 안에 사용되는 대문자를 찾을 수 있습니다.
프로그램 컴파일
프로그램 이름을 CPROG.C로 지정합니다. C 프로그램을 입력하고 컴파일하려면 다음 단계를 따르십시오.
- C 프로그램의 활성 디렉토리를 만들고 편집기를 시작하십시오. 이를 위해 모든 텍스트 편집기를 사용할 수 있지만 Borland의 Turbo C++와 같은 대부분의 C 컴파일러에는 하나의 편리한 설정에서 프로그램을 입력, 컴파일 및 연결할 수 있는 통합 개발 환경(IDE)이 있습니다.
- 소스 코드를 작성하고 저장합니다. 파일 이름을 CPROG.C. 로 지정해야 합니다.
- CPROG.C를 컴파일하고 링크합니다. 컴파일러 설명서에 지정된 적절한 명령을 실행하십시오. 오류나 경고가 없다는 메시지가 표시됩니다.
- 컴파일러 메시지를 확인합니다. 오류나 경고가 수신되지 않으면 모든 것이 정상입니다. 프로그램 입력에 오류가 있으면 컴파일러는 이를 잡아내고 오류 메시지를 표시합니다. 오류 메시지에 표시된 오류를 수정하십시오.
- 이제 첫 번째 C 프로그램이 컴파일되어 실행할 준비가 되었습니다. CPROG라는 모든 파일의 디렉토리 목록을 표시하면 다음과 같이 확장자가 다른 4개의 파일이 표시됩니다.
- CPROG.C, 소스 코드 파일
- CPROG.BAK, 에디터로 생성한 소스 파일의 백업 파일
- CPROG.OBJ, CPROG.C에 대한 개체 코드 포함
- CPROG.EXE, CPROG.C를 컴파일 및 링크할 때 생성되는 실행 프로그램
- CPROG.EXE를 실행하거나 실행하려면 cprog를 입력하기만 하면 됩니다. 이것은 C 프로그램입니다.라는 메시지가 화면에 표시됩니다.
이제 다음 프로그램을 살펴보겠습니다.
/* C를 배우기 위한 첫 번째 프로그램 */ // 1
// 2
#include <stdio.h> // 3
// 4
main() // 5
{
// 6
printf("This is a C program\n"); // 7
// 8
return 0; // 9
} // 10
이 프로그램을 컴파일하면 컴파일러는 다음과 유사한 메시지를 표시합니다.
cprog.c(8) : 오류: `;' 예상
이 오류 메시지를 부분적으로 나누겠습니다. cprog.c는 오류가 발견된 파일의 이름입니다. (8)은 오류가 발견된 줄 번호입니다. 오류: `;' 예상은 오류에 대한 설명입니다.
이 메시지는 매우 유익하며 CPROG.C의 8행에서 컴파일러가 세미콜론을 찾을 것으로 예상했지만 찾지 못했다는 것을 알려줍니다. 그러나 실제로 7행에서 세미콜론이 생략되어 불일치가 있음을 알고 있습니다.
컴파일러가 7행에서 세미콜론을 생략했는데도 8행에서 오류를 보고하는 이유는 C가 행 사이의 줄바꿈 같은 것을 신경 쓰지 않는다는 사실에 있습니다. printf() 문 뒤에 속하는 세미콜론은 실제로는 좋지 않은 프로그래밍이 될 수 있지만 다음 줄에 위치할 수 있습니다.
8행에서 다음 명령(반환)을 만난 후에야 컴파일러에서 세미콜론이 누락되었음을 확인합니다. 따라서 컴파일러는 오류가 8행에 있다고 보고합니다.
다양한 유형의 오류가 발생할 수 있습니다. 연결 오류 메시지에 대해 논의해 보겠습니다. 링커 오류는 비교적 드물며 일반적으로 C 라이브러리 함수의 이름을 잘못 입력하여 발생합니다. 이 경우 오류: 정의되지 않은 기호: 오류 메시지와 철자가 잘못된 이름이 표시됩니다. 맞춤법을 수정하면 문제가 사라집니다.
숫자 인쇄
다음 예를 살펴보겠습니다.
// 숫자를 출력하는 방법 //
#include<stdio.h>
void main()
{
int num = 10;
printf(“ The Number Is %d”, num);
}
프로그램의 출력은 다음과 같이 화면에 표시됩니다.
The Number Is 10
% 기호는 다양한 유형의 변수의 출력을 나타내는 데 사용됩니다. % 기호 다음에 오는 문자는 d이며, 이는 출력 루틴에 10진수 값을 가져와 출력하도록 신호를 보냅니다.
변수 사용
C에서 변수는 사용하기 전에 선언되어야 합니다. 변수는 코드 블록의 시작 부분에 선언할 수 있지만 대부분은 각 함수의 시작 부분에 있습니다. 대부분의 지역 변수는 함수가 호출될 때 생성되고 해당 함수에서 반환될 때 소멸됩니다.
C 프로그램에서 변수를 사용하려면 C에서 변수에 이름을 지정할 때 다음 규칙을 알아야 합니다.
- 이름에는 문자, 숫자, 밑줄(_)이 포함될 수 있습니다.
- 이름의 첫 번째 문자는 문자여야 합니다. 밑줄도 유효한 첫 문자이지만 사용하지 않는 것이 좋습니다.
- C는 대소문자를 구분하므로 변수 이름 num은 Num과 다릅니다.
- C 키워드는 변수 이름으로 사용할 수 없습니다. 키워드는 C 언어의 일부인 단어입니다.
다음 목록에는 합법 및 불법 C 변수 이름의 몇 가지 예가 포함되어 있습니다.
| Variable Name |
Legal or Not |
| Num |
Legal |
| Ttpt2_t2p |
Legal |
| Tt pt |
Illegal: Space is not allowed |
| _1990_tax |
Legal but not advised |
| Jack_phone# |
Illegal: Contains the illegal character # |
| Case |
Illegal: Is a C keyword |
| 1book |
Illegal: First character is a digit |
가장 먼저 눈에 띄는 것은 main() 본문의 첫 번째 줄입니다.
int num = 10;
이 줄은 int 유형의 'num'이라는 변수를 정의하고 값 10으로 초기화합니다. 이것은 다음과 같이 작성되었을 수도 있습니다.
int num; /* define uninitialized variable 'num' */
/* and after all variable definitions: */
num = 10; /* assigns value 10 to variable 'num' */
변수는 블록의 시작 부분(중괄호 {and} 사이)에 정의될 수 있습니다. 일반적으로 이것은 함수 본문의 시작 부분에 있지만 다른 유형의 블록 시작 부분에 있을 수도 있습니다.
블록의 시작 부분에 정의된 변수는 기본적으로 '자동' 상태로 설정됩니다. 이것은 블록이 실행되는 동안에만 존재한다는 것을 의미합니다. 함수 실행이 시작되면 변수가 생성되지만 그 내용은 정의되지 않습니다. 함수가 반환되면 변수가 소멸됩니다. 정의는 다음과 같이 작성할 수도 있습니다.
auto int num = 10;
auto 키워드가 있거나 없는 정의는 완전히 동일하므로 auto 키워드는 분명히 중복됩니다.
그러나 때로는 이것이 원하는 것이 아닙니다. 함수가 호출된 횟수를 세는 기능을 원한다고 가정합니다. 함수가 반환될 때마다 변수가 소멸된다면 불가능할 것입니다.
따라서 변수에 정적 지속 시간을 줄 수 있습니다. 즉, 프로그램이 실행되는 동안 그대로 유지됩니다. 예를 들어:
static int num = 10;
이것은 프로그램 실행이 시작될 때 변수 num을 10으로 초기화합니다. 그때부터 값은 그대로 유지됩니다. 함수를 여러 번 호출하면 변수가 다시 초기화되지 않습니다.
때로는 한 함수에서만 변수에 액세스할 수 있다는 것만으로는 충분하지 않거나 매개변수를 통해 값을 필요로 하는 다른 모든 함수에 전달하는 것이 편리하지 않을 수 있습니다.
그러나 전체 소스 파일의 모든 함수에서 변수에 액세스해야 하는 경우 static 키워드로도 수행할 수 있지만 정의를 모든 함수 외부에 배치하면 됩니다. 예를 들어:
#include <stdio.h>
static int num = 10; /* will be accessible from entire source file */
int main(void)
{
printf("The Number Is: %d\n", num);
return 0;
}
또한 여러 소스 파일로 구성될 수 있는 전체 프로그램에서 변수에 액세스해야 하는 경우도 있습니다. 이것을 전역 변수라고 하며 필요하지 않을 때는 피해야 합니다.
이 작업은 정의를 모든 함수 외부에 배치하지만 static 키워드를 사용하지 않음으로써 수행됩니다.
#include <stdio.h>
int num = 10; /* will be accessible from entire program! */
int main(void)
{
printf("The Number Is: %d\n", num);
return 0;
}
다른 모듈의 전역 변수에 액세스하는 데 사용되는 extern 키워드도 있습니다. 변수 정의에 추가할 수 있는 몇 가지 한정자가 있습니다. 그 중 가장 중요한 것은 const입니다. const로 정의된 변수는 수정할 수 없습니다.
덜 일반적으로 사용되는 두 가지 수정자가 더 있습니다. 휘발성 및 레지스터 수정자. volatile 수정자는 읽을 때마다 컴파일러가 실제로 변수에 액세스해야 합니다. 레지스터 등에 넣어 변수를 최적화하지 않을 수 있습니다. 이것은 주로 멀티스레딩 및 인터럽트 처리 목적 등에 사용됩니다.
레지스터 수정자는 변수를 레지스터로 최적화하도록 컴파일러에 요청합니다. 이것은 자동 변수에서만 가능하며 많은 경우 컴파일러가 레지스터로 최적화할 변수를 더 잘 선택할 수 있으므로 이 키워드는 더 이상 사용되지 않습니다. 변수 레지스터를 만드는 직접적인 결과는 주소를 가져올 수 없다는 것입니다.
다음 페이지에 제공된 변수 테이블은 5가지 유형의 스토리지 클래스의 스토리지 클래스를 설명합니다.
표에서 키워드 extern이 두 행에 배치된 것을 볼 수 있습니다. extern 키워드는 함수에서 다른 곳에 정의된 정적 외부 변수를 선언하는 데 사용됩니다.
숫자 변수 유형
C는 숫자 값에 따라 메모리 저장 요구 사항이 다르기 때문에 여러 유형의 숫자 변수를 제공합니다. 이러한 숫자 유형은 특정 수학 연산을 쉽게 수행할 수 있다는 점에서 다릅니다.
작은 정수는 저장하는 데 더 적은 메모리가 필요하며 컴퓨터는 이러한 숫자로 수학 연산을 매우 빠르게 수행할 수 있습니다. 큰 정수와 부동 소수점 값은 더 많은 저장 공간과 수학 연산에 더 많은 시간을 필요로 합니다. 적절한 변수 유형을 사용하면 프로그램이 최대한 효율적으로 실행되도록 할 수 있습니다.
C의 숫자 변수는 다음 두 가지 주요 범주로 나뉩니다.
이러한 각 범주 내에는 둘 이상의 특정 변수 유형이 있습니다. 다음에 주어진 표는 각 유형의 단일 변수를 보유하는 데 필요한 메모리 양(바이트)을 보여줍니다.
char 유형은 signed char 또는 unsigned char와 동일할 수 있지만 항상 이들 중 하나와 별개의 유형입니다.
C에서는 문자 또는 해당 숫자 값을 변수에 저장하는 데 차이가 없으므로 문자와 숫자 값을 변환하거나 그 반대로 변환하는 함수도 필요하지 않습니다. 다른 정수 유형의 경우 signed 또는 unsigned를 생략하면 기본값이 서명됩니다. int와 signed int는 동일합니다.
int 유형은 short 유형보다 크거나 같아야 하고 long 유형보다 작거나 같아야 합니다. 엄청나게 크지 않은 값을 단순히 저장해야 하는 경우 int 유형을 사용하는 것이 좋습니다. 일반적으로 프로세서가 가장 쉽게 처리할 수 있는 크기이므로 가장 빠릅니다.
여러 컴파일러에서 double과 long double은 동일합니다. 대부분의 표준 수학 함수가 double 유형과 함께 작동한다는 사실과 결합하여 분수로 작업해야 하는 경우 항상 double 유형을 사용하는 좋은 이유입니다.
다음 표는 변수 유형을 더 잘 설명하기 위한 것입니다.

일반적으로 사용되는 특수 목적 유형:
| Variable Type |
Description |
| size_t |
unsigned type used for storing the sizes of objects in bytes |
| time_t |
used to store results of the time() function |
| clock_t |
used to store results of the clock() function |
| FILE |
used for accessing a stream (usually a file or device) |
| ptrdiff_t |
signed type of the difference between 2 pointers |
| div_t |
used to store results of the div() function |
| ldiv_t |
used to store results of ldiv() function |
| fpos_t |
used to hold file position information |
| va_list |
used in variable argument handling |
| wchar_t |
wide character type (used for extended character sets) |
| sig_atomic_t |
used in signal handlers |
| Jmp_buf |
used for non-local jumps |
이러한 변수를 더 잘 이해하기 위해 예를 들어보겠습니다.
/* C 변수의 범위와 크기를 바이트 단위로 알려주는 프로그램 */
#include <stdio.h>
int main()
{
int a; /* simple integer type */
long int b; /* long integer type */
short int c; /* short integer type */
unsigned int d; /* unsigned integer type */
char e; /* character type */
float f; /* floating point type */
double g; /* double precision floating point */
a = 1023;
b = 2222;
c = 123;
d = 1234;
e = 'X';
f = 3.14159;
g = 3.1415926535898;
printf( "\nA char is %d bytes", sizeof( char ));
printf( "\nAn int is %d bytes", sizeof( int ));
printf( "\nA short is %d bytes", sizeof( short ));
printf( "\nA long is %d bytes", sizeof( long ));
printf( "\nAn unsigned char is %d bytes",
sizeof( unsigned char ));
printf( "\nAn unsigned int is %d bytes",
sizeof( unsigned int ));
printf( "\nAn unsigned short is %d bytes",
sizeof( unsigned short ));
printf( "\nAn unsigned long is %d bytes",
sizeof( unsigned long ));
printf( "\nA float is %d bytes", sizeof( float ));
printf( "\nA double is %d bytes\n", sizeof( double ));
printf("a = %d\n", a); /* decimal output */
printf("a = %o\n", a); /* octal output */
printf("a = %x\n", a); /* hexadecimal output */
printf("b = %ld\n", b); /* decimal long output */
printf("c = %d\n", c); /* decimal short output */
printf("d = %u\n", d); /* unsigned output */
printf("e = %c\n", e); /* character output */
printf("f = %f\n", f); /* floating output */
printf("g = %f\n", g); /* double float output */
printf("\n");
printf("a = %d\n", a); /* simple int output */
printf("a = %7d\n", a); /* use a field width of 7 */
printf("a = %-7d\n", a); /* left justify in
field of 7 */
c = 5;
d = 8;
printf("a = %*d\n", c, a); /* use a field width of 5*/
printf("a = %*d\n", d, a); /* use a field width of 8 */
printf("\n");
printf("f = %f\n", f); /* simple float output */
printf("f = %12f\n", f); /* use field width of 12 */
printf("f = %12.3f\n", f); /* use 3 decimal places */
printf("f = %12.5f\n", f); /* use 5 decimal places */
printf("f = %-12.5f\n", f); /* left justify in field */
return 0;
}
실행 후 프로그램의 결과는 다음과 같이 표시됩니다.
A char is 1 bytes
An int is 2 bytes
A short is 2 bytes
A long is 4 bytes
An unsigned char is 1 bytes
An unsigned int is 2 bytes
An unsigned short is 2 bytes
An unsigned long is 4 bytes
A float is 4 bytes
A double is 8 bytes
a = 1023
a = 1777
a = 3ff
b = 2222
c = 123
d = 1234
e = X
f = 3.141590
g = 3.141593
a = 1023
a = 1023
a = 1023
a = 1023
a = 1023
f = 3.141590
f = 3.141590
f = 3.142
f = 3.14159
f = 3.14159 |
사용하기 전에 C 프로그램에서 변수를 선언해야 합니다. 변수 선언은 컴파일러에게 변수의 이름과 유형을 알려주고 선택적으로 변수를 특정 값으로 초기화합니다.
프로그램이 선언되지 않은 변수를 사용하려고 하면 컴파일러에서 오류 메시지를 생성합니다. 변수 선언의 형식은 다음과 같습니다.
유형 이름 변수 이름;
typename은 변수 유형을 지정하며 키워드 중 하나여야 합니다. varname은 변수 이름입니다. 변수 이름을 쉼표로 구분하여 한 줄에 같은 유형의 여러 변수를 선언할 수 있습니다.
int count, number, start; /* three integer variables */
float percent, total; /* two float variables */
typedef 키워드
typedef 키워드는 기존 데이터 유형에 대한 새 이름을 만드는 데 사용됩니다. 실제로 typedef는 동의어를 만듭니다. 예를 들어,
typedef 정수;
여기서 typedef는 int의 동의어로 정수를 생성하는 것을 볼 수 있습니다. 그런 다음 정수를 사용하여 다음 예와 같이 int 유형의 변수를 정의할 수 있습니다.
정수 개수;
따라서 typedef는 새 데이터 유형을 생성하지 않으며 사전 정의된 데이터 유형에 대해 다른 이름만 사용할 수 있습니다.
숫자 변수 초기화
변수가 선언되면 컴파일러는 변수에 대한 저장 공간을 따로 확보하라는 지시를 받습니다. 그러나 그 공간에 저장된 값, 즉 변수의 값은 정의되어 있지 않다. 0일 수도 있고 임의의 "쓰레기"일 수도 있습니다. 값. 변수를 사용하기 전에 항상 알려진 값으로 초기화해야 합니다. 이 예를 들어보겠습니다.
int count; /* Set aside storage space for count */
count = 0; /* Store 0 in count */
이 문은 C의 할당 연산자인 등호(=)를 사용합니다. 변수가 선언될 때 변수를 초기화할 수도 있습니다. 이렇게 하려면 선언문의 변수 이름 뒤에 등호와 원하는 초기 값을 사용하십시오.
int count = 0;
double rate = 0.01, complexity = 28.5;
허용 범위를 벗어난 값으로 변수를 초기화하지 않도록 주의하십시오. 다음은 범위를 벗어난 초기화의 두 가지 예입니다.
int amount = 100000;
unsigned int length = -2500;
C 컴파일러는 그러한 오류를 포착하지 않습니다. 프로그램이 컴파일 및 링크될 수 있지만 프로그램이 실행될 때 예기치 않은 결과를 얻을 수 있습니다.
디스크의 총 섹터 수를 계산하기 위해 다음 예를 살펴보겠습니다.
// 디스크의 섹터를 계산하는 모델 프로그램 //
#include<stdio.h>
#define SECTOR_PER_SIDE 63
#define SIDE_PER_CYLINDER 254
void main()
{
int cylinder=0;
clrscr();
printf("Enter The No. of Cylinders in the Disk \n\n\t");
scanf("%d",&cylinder); // Get the value from the user //
printf("\n\n\t Total Number of Sectors in the disk = %ld", (long)SECTOR_PER_SIDE*SIDE_PER_CYLINDER* cylinder);
getch();
}
프로그램의 출력은 다음과 같습니다.
Enter The No. of Cylinders in the Disk
1024
Total Number of Sectors in the disk = 16386048
이 예에서 우리는 세 가지 새로운 것을 배울 수 있습니다. #define은 프로그램에서 기호 상수를 사용하거나 경우에 따라 작은 기호로 긴 단어를 정의하여 시간을 절약하는 데 사용됩니다.
여기에서는 프로그램을 이해하기 쉽도록 SECTOR_PER_SIDE로 63개의 측면당 섹터 수를 정의했습니다. #define SIDE_PER_CYLINDER 254의 경우에도 마찬가지입니다. scanf()는 사용자로부터 입력을 받는 데 사용됩니다.
여기서 사용자의 입력으로 실린더 수를 사용합니다. *는 예제와 같이 둘 이상의 값을 곱하는 데 사용됩니다.
getch() 함수는 기본적으로 키보드에서 단일 문자 입력을 받습니다. getch()를 입력하여; 여기서 우리는 키보드에서 아무 키나 칠 때까지 화면을 멈춥니다.
연산자
연산자는 C가 하나 이상의 피연산자에 대해 일부 작업 또는 작업을 수행하도록 지시하는 기호입니다. 피연산자는 연산자가 작동하는 것입니다. C에서 모든 피연산자는 표현식입니다. C 연산자는 다음 네 가지 범주로 나뉩니다.
- 할당 연산자
- 수학 연산자
- 관계 연산자
- 논리 연산자
할당 연산자
할당 연산자는 등호(=)입니다. 프로그래밍에서 등호를 사용하는 것은 일반 수학 대수 관계에서 사용하는 것과 다릅니다. 당신이 쓰는 경우
x = y;
C 프로그램에서 "x는 y와 같다"는 의미가 아니다. 대신 "y의 값을 x에 할당"을 의미합니다. C 대입문에서 오른쪽은 모든 표현식이 될 수 있고 왼쪽은 변수 이름이어야 합니다. 따라서 형식은 다음과 같습니다.
변수 = 표현식;
실행 중에 표현식이 평가되고 결과 값이 변수에 할당됩니다.
수학 연산자
C의 수학 연산자는 더하기 및 빼기와 같은 수학적 연산을 수행합니다. C에는 2개의 단항 수학 연산자와 5개의 이진 수학 연산자가 있습니다. 단항 수학 연산자는 단일 피연산자를 사용하기 때문에 그렇게 명명되었습니다. C에는 두 개의 단항 수학 연산자가 있습니다.
증가 및 감소 연산자는 상수가 아닌 변수에만 사용할 수 있습니다. 수행되는 연산은 피연산자에 1을 더하거나 1을 빼는 것입니다. 즉, ++x; 및 --y; 다음 명령문과 동일합니다.
x = x + 1;
y = y - 1;
이항 수학 연산자는 두 개의 피연산자를 사용합니다. 계산기에서 볼 수 있는 일반적인 수학 연산(+, -, *, /)을 포함하는 처음 4개의 이진 연산자는 익숙합니다. 다섯 번째 연산자 Modulus는 첫 번째 피연산자를 두 번째 피연산자로 나눈 나머지를 반환합니다. 예를 들어, 11 모듈러스 4는 3과 같습니다(11을 4로 나누면 2배가 되고 3이 남음).
관계 연산자
C의 관계 연산자는 표현식을 비교하는 데 사용됩니다. 관계 연산자를 포함하는 식은 참(1) 또는 거짓(0)으로 평가됩니다. C에는 6개의 관계 연산자가 있습니다.
논리 연산자
C의 논리 연산자를 사용하면 둘 이상의 관계식을 true 또는 false로 평가되는 단일 표현식으로 결합할 수 있습니다. 논리 연산자는 피연산자의 참 또는 거짓 값에 따라 참 또는 거짓으로 평가됩니다.
x가 정수 변수인 경우 논리 연산자를 사용하는 표현식은 다음과 같이 작성할 수 있습니다.
(x > 1) && (x < 5)
(x >= 2) && (x <= 4)
| Operator |
Symbol |
Description |
Example |
| Assignment operators |
| equal |
= |
assign the value of y to x |
x = y |
| Mathematical operators |
| Increment |
++ |
Increments the operand by one |
++x, x++ |
| Decrement |
-- |
Decrements the operand by one |
--x, x-- |
| Addition |
+ |
Adds two operands |
x + y |
| Subtraction |
- |
Subtracts the second operand from the first |
x - y |
| Multiplication |
* |
Multiplies two operands |
x * y |
| Division |
/ |
Divides the first operand by the second operand |
x / y |
| Modulus |
% |
Gives the remainder when the first operand is divided by the second operand |
x % y |
| Relational operators |
| Equal |
= = |
Equality |
x = = y |
| Greater than |
> |
Greater than |
x > y |
| Less than |
< |
Less than |
x < y |
| Greater than or equal to |
>= |
Greater than or equal to |
x >= y |
| Less than or equal to |
<= |
Less than or equal to |
x <= y |
| Not equal |
!= |
Not equal to |
x != y |
| Logical operators |
| AND |
&& |
True (1) only if both exp1 and exp2 are true; false (0) otherwise |
exp1 && exp2 |
| OR |
|| |
True (1) if either exp1 or exp2 is true; false (0) only if both are false |
exp1 || exp2 |
| NOT |
! |
False (0) if exp1 is true; true (1) if exp1 is false |
!exp1 |
논리적 표현에 대해 기억해야 할 사항
| x * = y |
is same as |
x = x * y |
| y - = z + 1 |
is same as |
y = y - z + 1 |
| a / = b |
is same as |
a = a / b |
| x + = y / 8 |
is same as |
x = x + y / 8 |
| y % = 3 |
is same as |
y = y % 3 |
쉼표 연산자
쉼표는 C에서 변수 선언, 함수 인수 등을 구분하기 위해 간단한 구두점으로 자주 사용됩니다. 특정 상황에서 쉼표는 연산자 역할을 합니다.
두 개의 하위 표현식을 쉼표로 구분하여 표현식을 구성할 수 있습니다. 결과는 다음과 같습니다.
- 두 식이 모두 평가되고 왼쪽 식이 먼저 평가됩니다.
- 전체 표현식은 올바른 표현식의 값으로 평가됩니다.
예를 들어 다음 명령문은 b 값을 x에 할당한 다음 a를 증가시킨 다음 b를 증가시킵니다.
x = (a++, b++);
C operator precedence (Summary of C operators)
| Rank and Associativity |
Operators |
| 1(left to right) |
() [] -> . |
| 2(right to left) |
! ~ ++ -- * (indirection) & (address-of) (type)
sizeof + (unary) - (unary) |
| 3(left to right) |
* (multiplication) / % |
| 4(left to right) |
+ - |
| 5(left to right) |
<< >> |
| 6(left to right) |
< <= > >= |
| 7(left to right) |
= = != |
| 8(left to right) |
& (bitwise AND) |
| 9(left to right) |
^ |
| 10(left to right) |
| |
| 11(left to right) |
&& |
| 12(left to right) |
|| |
| 13(right to left) |
?: |
| 14(right to left) |
= += -= *= /= %= &= ^= |= <<= >>= |
| 15(left to right) |
, |
| () is the function operator; [] is the array operator. |
|
연산자 사용의 예를 살펴보겠습니다.
/* 연산자 사용 */
int main()
{
int x = 0, y = 2, z = 1025;
float a = 0.0, b = 3.14159, c = -37.234;
/* incrementing */
x = x + 1; /* This increments x */
x++; /* This increments x */
++x; /* This increments x */
z = y++; /* z = 2, y = 3 */
z = ++y; /* z = 4, y = 4 */
/* decrementing */
y = y - 1; /* This decrements y */
y--; /* This decrements y */
--y; /* This decrements y */
y = 3;
z = y--; /* z = 3, y = 2 */
z = --y; /* z = 1, y = 1 */
/* arithmetic op */
a = a + 12; /* This adds 12 to a */
a += 12; /* This adds 12 more to a */
a *= 3.2; /* This multiplies a by 3.2 */
a -= b; /* This subtracts b from a */
a /= 10.0; /* This divides a by 10.0 */
/* conditional expression */
a = (b >= 3.0 ? 2.0 : 10.5 ); /* This expression */
if (b >= 3.0) /* And this expression */
a = 2.0; /* are identical, both */
else /* will cause the same */
a = 10.5; /* result. */
c = (a > b ? a : b); /* c will have the max of a or b */
c = (a > b ? b : a); /* c will have the min of a or b */
printf("x=%d, y=%d, z= %d\n", x, y, z);
printf("a=%f, b=%f, c= %f", a, b, c);
return 0;
}
이 프로그램의 결과는 다음과 같이 화면에 표시됩니다.
x=3, y=1, z=1
a=2.000000, b=3.141590, c=2.000000
printf() 및 Scanf()에 대한 추가 정보
다음 두 가지 printf 문을 고려하십시오.
printf(“\t %d\n”, num);
printf(“%5.2f”, fract);
첫 번째 printf 문 \t 요청에서 화면의 탭 변위를 요청하면 인수 %d는 num 값이 십진 정수로 인쇄되어야 한다고 컴파일러에 알려줍니다. \n 새 출력이 새 줄에서 시작되도록 합니다.
두 번째 printf 문에서 %5.2f는 출력이 부동 소수점이어야 하며, 모두 다섯 자리, 소수점 오른쪽 두 자리가 있어야 함을 컴파일러에 알립니다. 백슬래시 문자에 대한 자세한 내용은 다음 표에 나와 있습니다.
| Constant |
Meaning |
| ‘\a’ |
Audible alert (bell) |
| ‘\b’ |
Backspace |
| ‘\f’ |
Form feed |
| ‘\n’ |
New line |
| ‘\r’ |
Carriage return |
| ‘\t’ |
Horizontal tab |
| ‘\v’ |
Vertical tab |
| ‘\’’ |
Single quote |
| ‘\”’ |
Double quote |
| ‘\?’ |
Question mark |
| ‘\\’ |
Backslash |
| ‘\0’ |
Null |
다음 scanf 문을 살펴보겠습니다.
scanf(“%d”, &num);
키보드의 데이터는 scanf 함수에 의해 수신됩니다. 위의 형식에서 & 각 변수 이름 앞의 (앰퍼샌드) 기호는 변수 이름의 주소를 지정하는 연산자입니다.
이렇게 하면 실행이 중지되고 변수 num의 값이 입력될 때까지 기다립니다. 정수 값을 입력하고 리턴 키를 누르면 컴퓨터는 다음 문장으로 진행합니다. scanf 및 printf 형식 코드는 다음 표에 나열되어 있습니다.
| Code |
Reads... |
| %c |
Single character |
| %d |
Decimal integer |
| %e |
Floating point value |
| %f |
Floating point value |
| %g |
Floating point value |
| %h |
Short integer |
| %i |
Decimal, hexadecimal or octal integer |
| %o |
Octal integer |
| %s |
String |
| %u |
Unsigned decimal integer |
| %x |
Hexadecimal integer |
제어문
프로그램은 일반적으로 순서대로 실행되는 다수의 명령문으로 구성됩니다. 명령문이 실행되는 순서를 제어할 수 있다면 프로그램은 훨씬 더 강력해질 수 있습니다.
문은 세 가지 일반적인 유형으로 나뉩니다.
- 값, 일반적으로 계산 결과가 변수에 저장되는 할당입니다.
- 입/출력, 데이터를 읽거나 출력합니다.
- 제어, 프로그램이 다음에 무엇을 할지 결정합니다.
이 섹션에서는 C에서 제어 문의 사용에 대해 설명합니다. 다음과 같이 강력한 프로그램을 작성하는 데 사용되는 방법을 보여줍니다.
- 프로그램의 중요한 부분을 반복합니다.
- 프로그램의 선택적 섹션 중에서 선택.
if else 문
이것은 특별한 시점에서 무엇을 할지 결정하거나 두 가지 행동 중 하나를 결정할 때 사용합니다.
다음 테스트는 학생이 45점 만점의 시험을 통과했는지 여부를 결정합니다.
if (result >= 45)
printf("Pass\n");
else
printf("Fail\n");
It is possible to use the if part without the else.
if (temperature < 0)
print("Frozen\n");
각 버전은 if 다음에 오는 괄호 안에 있는 테스트로 구성됩니다. 테스트가 참이면 다음 명령문이 준수됩니다. 거짓이면 else 뒤에 오는 문이 존재하는 경우 준수됩니다. 그 후에 나머지 프로그램은 정상적으로 계속됩니다.
if 또는 else 뒤에 하나 이상의 명령문이 포함되도록 하려면 중괄호 사이에 함께 그룹화해야 합니다. 이러한 그룹화를 복합 명령문 또는 블록이라고 합니다.
if (result >= 45)
{ printf("Passed\n");
printf("Congratulations\n");
}
else
{ printf("Failed\n");
printf("Better Luck Next Time\n");
}
때때로 우리는 여러 조건을 기반으로 다자간 결정을 내리기를 원합니다. 이를 수행하는 가장 일반적인 방법은 if 문에 else if 변형을 사용하는 것입니다.
이것은 여러 비교를 계단식으로 수행하여 작동합니다. 이들 중 하나가 참 결과를 제공하는 즉시 다음 명령문 또는 블록이 실행되고 더 이상의 비교는 수행되지 않습니다. 다음 예에서는 시험 결과에 따라 등급을 부여합니다.
if (result <=100 && result >= 75)
printf("Passed: Grade A\n");
else if (result >= 60)
printf("Passed: Grade B\n");
else if (result >= 45)
printf("Passed: Grade C\n");
else
printf("Failed\n");
이 예에서 모든 비교는 result라는 단일 변수를 테스트합니다. 다른 경우에는 각 테스트에 다른 변수 또는 테스트 조합이 포함될 수 있습니다. 더 많거나 더 적은 수의 else if와 동일한 패턴을 사용할 수 있으며 마지막 else만 생략할 수 있습니다.
각 프로그래밍 문제에 대한 올바른 구조를 고안하는 것은 프로그래머에게 달려 있습니다. if else의 사용을 더 잘 이해하기 위해 예제를 살펴보겠습니다.
#include <stdio.h>
int main()
{
int num;
for(num = 0 ; num < 10 ; num = num + 1)
{
if (num == 2)
printf("num is now equal to %d\n", num);
if (num < 5)
printf("num is now %d, which is less than 5\n", num);
else
printf("num is now %d, which is greater than 4\n", num);
} /* end of for loop */
return 0;
}
프로그램 결과
num is now 0, which is less than 5
num is now 1, which is less than 5
num is now equal to 2
num is now 2, which is less than 5
num is now 3, which is less than 5
num is now 4, which is less than 5
num is now 5, which is greater than 4
num is now 6, which is greater than 4
num is now 7, which is greater than 4
num is now 8, which is greater than 4
num is now 9, which is greater than 4
switch 문
이것은 다자 결정의 또 다른 형태입니다. 잘 구성되어 있지만 다음과 같은 특정 경우에만 사용할 수 있습니다.
- 하나의 변수만 테스트하고 모든 분기는 해당 변수의 값에 의존해야 합니다. 변수는 정수 형식이어야 합니다. (int, long, short 또는 char).
- 변수의 각 가능한 값은 단일 분기를 제어할 수 있습니다. 지정되지 않은 모든 경우를 트래핑하는 데 선택적으로 최종 기본 분기를 사용할 수 있습니다.
아래에 주어진 예는 상황을 명확히 할 것입니다. 정수를 모호한 설명으로 변환하는 함수입니다. 양이 아주 적을 때만 측정할 때 유용합니다.
estimate(number)
int number;
/* Estimate a number as none, one, two, several, many */
{ switch(number) {
case 0 :
printf("None\n");
break;
case 1 :
printf("One\n");
break;
case 2 :
printf("Two\n");
break;
case 3 :
case 4 :
case 5 :
printf("Several\n");
break;
default :
printf("Many\n");
break;
}
}
각 흥미로운 사례는 해당 작업과 함께 나열됩니다. break 문은 스위치를 떠나서 더 이상의 문이 실행되는 것을 방지합니다. 사례 3과 사례 4에는 다음 중단이 없으므로 계속해서 여러 숫자 값에 대해 동일한 작업을 허용합니다.
if 및 switch 구문 모두 프로그래머가 가능한 여러 작업 중에서 선택할 수 있도록 합니다. 예를 들어 보겠습니다.
#include <stdio.h>
int main()
{
int num;
for (num = 3 ; num < 13 ; num = num + 1)
{
switch (num)
{
case 3 :
printf("The value is three\n");
break;
case 4 :
printf("The value is four\n");
break;
case 5 :
case 6 :
case 7 :
case 8 :
printf("The value is between 5 and 8\n");
break;
case 11 :
printf("The value is eleven\n");
break;
default :
printf("It is one of the undefined values\n");
break;
} /* end of switch */
} /* end of for loop */
return 0;
}
프로그램의 출력은
The value is three
The value is four
The value is between 5 and 8
The value is between 5 and 8
The value is between 5 and 8
The value is between 5 and 8
It is one of the undefined values
It is one of the undefined values
The value is eleven
It is one of the undefined values
break 문
우리는 이미 switch 문에 대한 논의에서 break를 만났습니다. 루프나 스위치에서 빠져나오거나 루프나 스위치 너머의 첫 번째 명령문으로 제어를 전달하는 데 사용됩니다.
루프를 사용하면 break를 사용하여 루프에서 조기 종료를 강제하거나 루프 본문의 중간에서 종료하는 테스트를 사용하여 루프를 구현할 수 있습니다. 루프 내의 중단은 종료 조건을 제어하기 위한 테스트를 제공하는 if 문 내에서 항상 보호되어야 합니다.
계속 설명
break와 비슷하지만 덜 자주 발생합니다. 루프 제어 문으로 즉시 점프하는 효과가 있는 루프 내에서만 작동합니다.
- while 루프에서 테스트 문으로 이동합니다.
- do while 루프에서 테스트 문으로 이동합니다.
- for 루프에서 테스트로 이동하고 반복을 수행합니다.
쉼표와 마찬가지로 계속은 if 문으로 보호되어야 합니다. 당신은 그것을 자주 사용하지 않을 것입니다. break and continue의 사용을 더 잘 이해하기 위해 다음 프로그램을 살펴보겠습니다.
#include <stdio.h>
int main()
{
int value;
for(value = 5 ; value < 15 ; value = value + 1)
{
if (value == 8)
break;
printf("In the break loop, value is now %d\n", value);
}
for(value = 5 ; value < 15 ; value = value + 1)
{
if (value == 8)
continue;
printf("In the continue loop, value is now %d\n", value);
}
return 0;
}
프로그램의 출력은 다음과 같습니다.
In the break loop, value is now 5
In the break loop, value is now 6
In the break loop, value is now 7
In the continue loop, value is now 5
In the continue loop, value is now 6
In the continue loop, value is now 7
In the continue loop, value is now 9
In the continue loop, value is now 10
In the continue loop, value is now 11
In the continue loop, value is now 12
In the continue loop, value is now 13
In the continue loop, value is now 14
루프
제어문의 다른 주요 유형은 루프입니다. 루프를 사용하면 명령문 또는 명령문 블록을 반복할 수 있습니다. 컴퓨터는 간단한 작업을 여러 번 반복하는 데 매우 능숙합니다. 루프는 이것을 달성하는 C의 방법입니다.
C에서는 while, do-while 및 for의 세 가지 유형의 루프를 선택할 수 있습니다.
- while 루프는 연결된 테스트가 false를 반환할 때까지 작업을 계속 반복합니다. 이것은 루프가 몇 번이나 통과할지 프로그래머가 미리 알지 못하는 경우에 유용합니다.
- do while 루프는 비슷하지만 테스트는 루프 본문이 실행된 후에 발생합니다. 이렇게 하면 루프 본문이 한 번 이상 실행됩니다.
- for 루프는 일반적으로 고정된 횟수만큼 루프를 순회하는 곳에서 자주 사용됩니다. 그것은 매우 유연하며, 초보 프로그래머는 그것이 제공하는 능력을 남용하지 않도록 주의해야 합니다.
while 루프
while 루프는 맨 위의 테스트가 거짓으로 판명될 때까지 명령문을 반복합니다. 예를 들어 다음은 문자열의 길이를 반환하는 함수입니다. 문자열은 null 문자 '\0'으로 끝나는 문자 배열로 표현된다는 것을 기억하십시오.
int string_length(char string[])
{ int i = 0;
while (string[i] != '\0')
i++;
return(i);
}
문자열은 인수로 함수에 전달됩니다. 배열의 크기가 지정되지 않은 경우 함수는 모든 크기의 문자열에 대해 작동합니다.
while 루프는 null 문자를 찾을 때까지 한 번에 하나씩 문자열의 문자를 보는 데 사용됩니다. 그런 다음 루프가 종료되고 null 인덱스가 반환됩니다.
문자가 null이 아닌 동안 인덱스가 증가하고 테스트가 반복됩니다. 배열에 대해서는 나중에 자세히 살펴보겠습니다. while 루프의 예를 살펴보겠습니다.
#include <stdio.h>
int main()
{
int count;
count = 0;
while (count < 6)
{
printf("The value of count is %d\n", count);
count = count + 1;
}
return 0;
}
결과는 다음과 같이 표시됩니다.
The value of count is 0
The value of count is 1
The value of count is 2
The value of count is 3
The value of count is 4
The value of count is 5
do while 루프
이것은 테스트가 루프 본문의 끝에서 발생한다는 점을 제외하고는 while 루프와 매우 유사합니다. 이렇게 하면 계속하기 전에 루프가 한 번 이상 실행됩니다.
이러한 설정은 데이터를 읽어야 하는 경우에 자주 사용됩니다. 그런 다음 테스트는 데이터를 확인하고 허용되지 않는 경우 다시 읽기 위해 루프백합니다.
do
{
printf("Enter 1 for yes, 0 for no :");
scanf("%d", &input_value);
} while (input_value != 1 && input_value != 0)
do while 루프를 더 잘 이해하기 위해 다음 예를 살펴보겠습니다.
#include <stdio.h>
int main()
{
int i;
i = 0;
do
{
printf("The value of i is now %d\n", i);
i = i + 1;
} while (i < 5);
return 0;
}
프로그램 결과는 다음과 같이 표시됩니다.
The value of i is now 0
The value of i is now 1
The value of i is now 2
The value of i is now 3
The value of i is now 4
for 루프
for 루프는 루프에 들어가기 전에 루프의 반복 횟수를 알고 있는 곳에서 잘 작동합니다. 루프의 헤드는 세미콜론으로 구분된 세 부분으로 구성됩니다.
- 첫 번째는 루프가 시작되기 전에 실행됩니다. 이것은 일반적으로 루프 변수의 초기화입니다.
- 두 번째는 테스트이며 false를 반환하면 루프가 종료됩니다.
- 세 번째는 루프 본문이 완료될 때마다 실행되는 문입니다. 이것은 일반적으로 루프 카운터의 증분입니다.
예제는 배열에 저장된 숫자의 평균을 계산하는 함수입니다. 이 함수는 배열과 요소 수를 인수로 사용합니다.
float average(float array[], int count)
{
float total = 0.0;
int i;
for(i = 0; i < count; i++)
total += array[i];
return(total / count);
}
for 루프는 평균을 계산하기 전에 정확한 수의 배열 요소가 합산되도록 합니다.
for 루프의 맨 앞에 있는 세 개의 명령문은 일반적으로 각각 한 가지 작업만 수행하지만 그 중 아무 것도 비워둘 수 있습니다. 비어 있는 첫 번째 또는 마지막 문은 초기화 또는 실행 중인 증분을 의미하지 않습니다. 빈 비교 문은 항상 true로 처리됩니다. 이것은 다른 수단에 의해 중단되지 않는 한 루프가 무한정 실행되도록 합니다. 이것은 return 또는 break 문일 수 있습니다.
여러 문장을 쉼표로 구분하여 첫 번째 또는 세 번째 위치에 넣는 것도 가능합니다. 이것은 하나 이상의 제어 변수가 있는 루프를 허용합니다. 아래 예는 변수 hi와 lo가 각각 100과 0에서 시작하여 수렴하는 루프의 정의를 보여줍니다.
for 루프는 사용할 수 있는 다양한 속기를 제공합니다. 다음 표현식을 주의하세요. 이 표현식에서 단일 루프에는 두 개의 for 루프가 포함되어 있습니다. 여기서 hi--는 hi = hi - 1과 동일하고 lo++는 lo = lo + 1과 동일합니다,
for(hi = 100, lo = 0; hi >= lo; hi--, lo++)
for 루프는 매우 유연하며 많은 유형의 프로그램 동작을 간단하고 빠르게 지정할 수 있습니다. for 루프의 예를 보자
#include <stdio.h>
int main()
{
int index;
for(index = 0 ; index < 6 ; index = index + 1)
printf("The value of the index is %d\n", index);
return 0;
}
프로그램 결과는 다음과 같이 표시됩니다.
The value of the index is 0
The value of the index is 1
The value of the index is 2
The value of the index is 3
The value of the index is 4
The value of the index is 5
goto 문
C에는 구조화되지 않은 점프를 허용하는 goto 문이 있습니다. goto 문을 사용하려면 예약어 goto 다음에 점프하려는 기호 이름을 사용하기만 하면 됩니다. 그런 다음 이름은 콜론 다음에 오는 프로그램의 아무 곳에나 배치됩니다. 함수 내에서 거의 모든 곳으로 이동할 수 있지만 루프 밖으로 점프하는 것은 허용되지만 루프로 점프하는 것은 허용되지 않습니다.
이 특정 프로그램은 정말 엉망이지만 소프트웨어 작성자가 가능한 한 goto 문을 사용하지 않으려고 노력하는 좋은 예입니다. 이 프로그램에서 goto를 사용하는 것이 합당한 유일한 위치는 프로그램이 한 번의 점프로 세 개의 중첩 루프에서 점프하는 곳입니다. 이 경우 변수를 설정하고 세 개의 중첩 루프 각각에서 연속적으로 점프하는 것은 다소 지저분할 것이지만 하나의 goto 문은 매우 간결한 방식으로 세 개 모두에서 여러분을 얻을 수 있습니다.
어떤 사람들은 goto 문을 어떤 상황에서도 절대 사용해서는 안 된다고 말하지만 이는 편협한 생각입니다. goto가 다른 구성보다 명확하게 깔끔한 제어 흐름을 수행하는 곳이 있으면 모니터의 나머지 프로그램에서와 같이 자유롭게 사용하십시오. 예를 살펴보겠습니다.
#include <stdio.h>
int main()
{
int dog, cat, pig;
goto real_start;
some_where:
printf("This is another line of the mess.\n");
goto stop_it;
/* the following section is the only section with a useable goto */
real_start:
for(dog = 1 ; dog < 6 ; dog = dog + 1)
{
for(cat = 1 ; cat < 6 ; cat = cat + 1)
{
for(pig = 1 ; pig < 4 ; pig = pig + 1)
{
printf("Dog = %d Cat = %d Pig = %d\n", dog, cat, pig);
if ((dog + cat + pig) > 8 ) goto enough;
}
}
}
enough: printf("Those are enough animals for now.\n");
/* this is the end of the section with a useable goto statement */
printf("\nThis is the first line of the code.\n");
goto there;
where:
printf("This is the third line of the code.\n");
goto some_where;
there:
printf("This is the second line of the code.\n");
goto where;
stop_it:
printf("This is the last line of this mess.\n");
return 0;
}
표시된 결과를 보자
Dog = 1 Cat = 1 Pig = 1
Dog = 1 Cat = 1 Pig = 2
Dog = 1 Cat = 1 Pig = 3
Dog = 1 Cat = 2 Pig = 1
Dog = 1 Cat = 2 Pig = 2
Dog = 1 Cat = 2 Pig = 3
Dog = 1 Cat = 3 Pig = 1
Dog = 1 Cat = 3 Pig = 2
Dog = 1 Cat = 3 Pig = 3
Dog = 1 Cat = 4 Pig = 1
Dog = 1 Cat = 4 Pig = 2
Dog = 1 Cat = 4 Pig = 3
Dog = 1 Cat = 5 Pig = 1
Dog = 1 Cat = 5 Pig = 2
Dog = 1 Cat = 5 Pig = 3
Those are enough animals for now.
This is the first line of the code.
This is the second line of the code.
This is the third line of the code.
This is another line of the mess.
This is the last line of this mess.
포인터
때때로 우리는 메모리에서 변수가 어디에 있는지 알고 싶어합니다. 포인터에는 특정 값을 가진 변수의 주소가 포함됩니다. 포인터를 선언할 때 포인터 이름 바로 앞에 별표가 표시됩니다. .
변수가 저장된 메모리 위치의 주소는 변수 이름 앞에 앰퍼샌드를 배치하여 찾을 수 있습니다.
int num; /* Normal integer variable */
int *numPtr; /* Pointer to an integer variable */
다음 예에서는 변수 값과 해당 변수의 메모리에 있는 주소를 인쇄합니다.
printf("The value %d is stored at address %X\n", num, &num);
포인터 numPtr에 변수 num의 주소를 할당하려면 다음 예제와 같이 변수의 주소 num을 할당합니다.
numPtr = #
numPtr이 가리키는 주소에 무엇이 저장되어 있는지 알아내려면 변수를 역참조해야 합니다. 역참조는 포인터가 선언된 별표와 함께 수행됩니다.
printf("The value %d is stored at address %X\n", *numPtr, numPtr);
프로그램의 모든 변수는 메모리에 있습니다. 아래 주어진 명령문은 컴파일러가 부동 소수점 변수 x에 대해 32비트 컴퓨터에서 4바이트 메모리를 예약한 다음 값 6.5를 입력하도록 요청합니다.
float x;
x = 6.5;
어떤 변수의 메모리에 있는 주소 위치는 연산자 & 따라서 이름 앞에 &x는 x의 주소입니다. C를 사용하면 한 단계 더 나아가 다른 변수의 주소를 포함하는 포인터라고 하는 변수를 정의할 수 있습니다. 오히려 포인터가 다른 변수를 가리킨다고 말할 수 있습니다. 예를 들어:
float x;
float* px;
x = 6.5;
px = &x;
px를 float 유형의 객체에 대한 포인터로 정의하고 x의 주소와 동일하게 설정합니다. 따라서 *px는 x의 값을 나타냅니다.
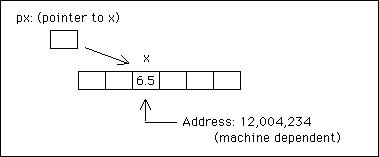
다음 진술을 검토해 보겠습니다.
int var_x;
int* ptrX;
var_x = 6;
ptrX = &var_x;
*ptrX = 12;
printf("value of x : %d", var_x);
첫 번째 줄은 컴파일러가 정수용 메모리 공간을 예약하도록 합니다. 두 번째 줄은 포인터를 저장할 공간을 예약하도록 컴파일러에 지시합니다.
포인터는 주소의 저장 위치입니다. 세 번째 줄은 scanf 문을 상기시켜야 합니다. 주소 &" 연산자는 컴파일러에게 var_x를 저장한 위치로 이동한 다음 저장 위치의 주소를 ptrX에 제공하도록 지시합니다.
변수 앞의 별표 *는 컴파일러에게 포인터를 역참조하고 메모리로 이동하도록 지시합니다. 그런 다음 해당 위치에 저장된 변수에 할당할 수 있습니다. 포인터를 통해 변수를 참조하고 해당 데이터에 액세스할 수 있습니다. 포인터의 예를 살펴보겠습니다.
/* 포인터 사용 예시 */
#include <stdio.h>
int main()
{
int index, *pt1, *pt2;
index = 39; /* any numerical value */
pt1 = &index; /* the address of index */
pt2 = pt1;
printf("The value is %d %d %d\n", index, *pt1, *pt2);
*pt1 = 13; /* this changes the value of index */
printf("The value is %d %d %d\n", index, *pt1, *pt2);
return 0;
}
프로그램의 출력은 다음과 같이 표시됩니다.
The value is 39 39 39
The value is 13 13 13
포인터 사용을 더 잘 이해하기 위해 다른 예를 살펴보겠습니다.
#include <stdio.h>
#include <string.h>
int main()
{
char strg[40], *there, one, two;
int *pt, list[100], index;
strcpy(strg, "This is a character string.");
/* the function strcpy() is to copy one string to another. we’ll read about strcpy() function in String Section later */
one = strg[0]; /* one and two are identical */
two = *strg;
printf("The first output is %c %c\n", one, two);
one = strg[8]; /* one and two are identical */
two = *(strg+8);
printf("The second output is %c %c\n", one, two);
there = strg+10; /* strg+10 is identical to &strg[10] */
printf("The third output is %c\n", strg[10]);
printf("The fourth output is %c\n", *there);
for (index = 0 ; index < 100 ; index++)
list[index] = index + 100;
pt = list + 27;
printf("The fifth output is %d\n", list[27]);
printf("The sixth output is %d\n", *pt);
return 0;
}
프로그램의 출력은 다음과 같습니다.
The first output is T T
The second output is a a
The third output is c
The fourth output is c
The fifth output is 127
The sixth output is 127
배열
배열은 동일한 유형의 변수 모음입니다. 개별 배열 요소는 정수 인덱스로 식별됩니다. C에서 인덱스는 0에서 시작하고 항상 대괄호 안에 기록됩니다.
이미 다음과 같이 선언된 1차원 배열을 만났습니다.
int results[20];
배열은 더 많은 차원을 가질 수 있으며, 이 경우 다음과 같이 선언될 수 있습니다.
int results_2d[20][5];
int results_3d[20][5][3];
각 인덱스에는 고유한 대괄호 세트가 있습니다. 배열은 기본 함수에서 선언되며 일반적으로 차원에 대한 세부 정보가 포함됩니다. 배열 대신 포인터라는 다른 유형을 사용할 수 있습니다. 즉, 치수가 즉시 고정되지는 않지만 필요에 따라 공간을 할당할 수 있습니다. 이것은 특정 전문 프로그램에서만 필요한 고급 기술입니다.
예를 들어, 단일 차원 배열의 모든 정수를 더하는 간단한 함수가 있습니다.
int add_array(int array[], int size)
{
int i;
int total = 0;
for(i = 0; i < size; i++)
total += array[i];
return(total);
}
다음에 주어진 프로그램은 문자열을 만들고 그 안의 일부 데이터에 액세스하여 인쇄합니다. 포인터를 사용하여 다시 액세스한 다음 문자열을 인쇄합니다. "Hi!"가 인쇄되어야 합니다. 다른 줄에 "012345678"이 있습니다. 프로그램의 코딩을 보자:
#include <stdio.h>
#define STR_LENGTH 10
void main()
{
char Str[STR_LENGTH];
char* pStr;
int i;
Str[0] = 'H';
Str[1] = 'i';
Str[2] = '!';
Str[3] = '\0'; // special end string character NULL
printf("The string in Str is : %s\n", Str);
pStr = &Str[0];
for (i = 0; i < STR_LENGTH; i++)
{
*pStr = '0'+i;
pStr++;
}
Str[STR_LENGTH-1] = '\0';
printf("The string in Str is : %s\n", Str);
}
[](대괄호)는 배열을 선언하는 데 사용됩니다. 프로그램 라인 char Str[STR_LENGTH]; 10개의 문자로 구성된 배열을 선언합니다. 이들은 10개의 개별 캐릭터로, 모두 같은 장소에 메모리에 결합됩니다. 그것들은 모두 [n]과 함께 변수 이름 Str을 통해 액세스할 수 있습니다. 여기서 n은 요소 번호입니다.
배열에 대해 이야기할 때 C가 10개의 배열을 선언할 때 액세스할 수 있는 요소의 번호는 0에서 9까지라는 점을 항상 염두에 두어야 합니다. 첫 번째 요소에 액세스하는 것은 0번째 요소에 액세스하는 것과 같습니다. 따라서 배열의 경우 항상 0부터 배열 크기 - 1까지 셉니다.
다음으로 "Hi!" 배열에 넣지 만 '\0'을 입력하면 이것이 무엇인지 궁금해 할 것입니다. "\0" NULL을 나타내며 문자열의 끝을 나타냅니다. 모든 문자열은 이 특수 문자 '\0'으로 끝나야 합니다. 그렇지 않은 경우 누군가가 문자열에서 printf를 호출하면 printf는 문자열의 메모리 위치에서 시작하고 인쇄를 계속하면 '\0'이 발생한다고 알리므로 끝에 많은 쓰레기가 생깁니다. 당신의 문자열의. 따라서 문자열을 올바르게 종료해야 합니다.
문자 배열
다음과 같은 문자열 상수 ,
"나는 문자열입니다"
는 문자 배열입니다. C에서 내부적으로는 "I", 공백, "a", "m" 또는 위의 문자열과 같은 문자열의 ASCII 문자로 표시되며 특수 널 문자 "\0"으로 종료되므로 프로그램은 다음을 수행할 수 있습니다. 문자열의 끝을 찾습니다.
문자열 상수는 종종 printf를 사용하여 코드 출력을 이해하기 쉽게 만드는 데 사용됩니다.
printf("Hello, world\n");
printf("The value of a is: %f\n", a);
문자열 상수는 변수와 연관될 수 있습니다. C는 한 번에 하나의 문자(1바이트)를 포함할 수 있는 문자 유형 변수를 제공합니다. 문자열은 위치당 하나의 ASCII 문자로 문자 유형의 배열에 저장됩니다.
문자열은 일반적으로 null 문자 "\0"으로 끝나므로 배열에 하나의 추가 저장 위치가 필요하다는 것을 잊지 마십시오.
C는 한 번에 전체 문자열을 조작하는 연산자를 제공하지 않습니다. 문자열은 포인터나 표준 문자열 라이브러리 string.h에서 사용할 수 있는 특수 루틴을 통해 조작됩니다.
문자 포인터를 사용하는 것은 배열의 이름이 첫 번째 요소에 대한 포인터일 뿐이기 때문에 상대적으로 쉽습니다. 다음에 주어진 프로그램을 고려하십시오.
#include<stdio.h>
void main()
{
char text_1[100], text_2[100], text_3[100];
char *ta, *tb;
int i;
/* set message to be an arrray */
/* of characters; initialize it */
/* to the constant string "..." */
/* let the compiler decide on */
/* its size by using [] */
char message[] = "Hello, I am a string; what are
you?";
printf("Original message: %s\n", message);
/* copy the message to text_1 */
i=0;
while ( (text_1[i] = message[i]) != '\0' )
i++;
printf("Text_1: %s\n", text_1);
/* use explicit pointer arithmetic */
ta=message;
tb=text_2;
while ( ( *tb++ = *ta++ ) != '\0' )
;
printf("Text_2: %s\n", text_2);
}
프로그램의 출력은 다음과 같습니다.
Original message: Hello, I am a string; what are you?
Text_1: Hello, I am a string; what are you?
Text_2: Hello, I am a string; what are you?
표준 "문자열" 라이브러리에는 문자열을 조작하는 데 유용한 많은 함수가 포함되어 있습니다. 이에 대해서는 나중에 문자열 섹션에서 배울 것입니다.
요소 액세스
배열의 개별 요소에 액세스하려면 인덱스 번호가 대괄호로 묶인 변수 이름 뒤에 옵니다. 그러면 변수는 C의 다른 변수처럼 취급될 수 있습니다. 다음 예제에서는 배열의 첫 번째 요소에 값을 할당합니다.
x[0] = 16;
다음 예제에서는 배열의 세 번째 요소 값을 인쇄합니다.
printf("%d\n", x[2]);
다음 예제에서는 scanf 함수를 사용하여 키보드에서 10개 요소가 있는 배열의 마지막 요소로 값을 읽습니다.
scanf("%d", &x[9]);
배열 요소 초기화
배열은 할당에 의해 다른 변수처럼 초기화될 수 있습니다. 배열에 둘 이상의 값이 포함되어 있으므로 개별 값은 중괄호 안에 배치되고 쉼표로 구분됩니다. 다음 예에서는 3배 테이블의 처음 10개 값으로 10차원 배열을 초기화합니다.
int x[10] = {3, 6, 9, 12, 15, 18, 21, 24, 27, 30};
이렇게 하면 다음 예와 같이 값을 개별적으로 할당하는 것을 절약할 수 있습니다.
int x[10];
x[0] = 3;
x[1] = 6;
x[2] = 9;
x[3] = 12;
x[4] = 15;
x[5] = 18;
x[6] = 21;
x[7] = 24;
x[8] = 27;
x[9] = 30;
배열을 통한 루프
배열이 순차적으로 인덱싱되므로 for 루프를 사용하여 배열의 모든 값을 표시할 수 있습니다. 다음 예에서는 배열의 모든 값을 표시합니다.
#include <stdio.h>
int main()
{
int x[10];
int counter;
/* Randomise the random number generator */
srand((unsigned)time(NULL));
/* Assign random values to the variable */
for (counter=0; counter<10; counter++)
x[counter] = rand();
/* Display the contents of the array */
for (counter=0; counter<10; counter++)
printf("element %d has the value %d\n", counter, x[counter]);
return 0;
}
출력은 매번 다른 값을 인쇄하지만 결과는 다음과 같이 표시됩니다.
element 0 has the value 17132
element 1 has the value 24904
element 2 has the value 13466
element 3 has the value 3147
element 4 has the value 22006
element 5 has the value 10397
element 6 has the value 28114
element 7 has the value 19817
element 8 has the value 27430
element 9 has the value 22136
다차원 배열
배열은 둘 이상의 차원을 가질 수 있습니다. 어레이가 둘 이상의 차원을 갖도록 함으로써 더 큰 유연성을 제공합니다. 예를 들어, 스프레드시트는 2차원 배열을 기반으로 합니다. 행의 배열과 열의 배열입니다.
다음 예에서는 각각 5개의 열을 포함하는 2개의 행이 있는 2차원 배열을 사용합니다.
#include <stdio.h>
int main()
{
/* Declare a 2 x 5 multidimensional array */
int x[2][5] = { {1, 2, 3, 4, 5},
{2, 4, 6, 8, 10} };
int row, column;
/* Display the rows */
for (row=0; row<2; row++)
{
/* Display the columns */
for (column=0; column<5; column++)
printf("%d\t", x[row][column]);
putchar('\n');
}
return 0;
}
이 프로그램의 출력은 다음과 같이 표시됩니다.
1 2 3 4 5
2 4 6 8 10
문자열
문자열은 일반적으로 알파벳 문자로 된 문자 그룹입니다. 보기에 좋고 의미 있는 이름과 제목을 가지며 사용자와 사용자가 미적으로 보기 좋은 방식으로 인쇄 디스플레이 형식을 지정하기 위해 프로그램의 출력.
사실, 이전 주제의 예에서 이미 문자열을 사용하고 있습니다. 그러나 문자열의 완전한 도입은 아닙니다. 프로그래밍에는 형식이 지정된 문자열을 사용하면 프로그래머가 프로그램의 너무 많은 복잡성과 너무 많은 버그를 피하는 데 도움이 되는 경우가 많이 있습니다.
문자열의 완전한 정의는 널 문자('\0')로 끝나는 일련의 문자 유형 데이터입니다.
C가 데이터 문자열을 다른 문자열과 비교하거나, 출력하거나, 다른 문자열에 복사하는 등 어떤 식으로든 데이터 문자열을 사용하려고 할 때 함수는 호출된 작업을 수행하도록 설정됩니다. null이 감지될 때까지
C에는 문자열에 대한 기본 데이터 유형이 없습니다. C의 문자열은 문자 배열로 구현됩니다. 예를 들어, 이름을 저장하려면 이름을 저장할 만큼 충분히 큰 문자 배열을 선언한 다음 적절한 라이브러리 함수를 사용하여 이름을 조작할 수 있습니다.
다음 예는 사용자가 입력한 문자열을 화면에 표시합니다.
#include <stdio.h>
int main()
{
char name[80]; /* Create a character array
called name */
printf("Enter your name: ");
gets(name);
printf("The name you entered was %s\n", name);
return 0;
}
프로그램 실행은 다음과 같습니다.
Enter your name: Tarun Tyagi
The name you entered was Tarun Tyagi
몇 가지 일반적인 문자열 함수
표준 string.h 라이브러리에는 문자열을 조작하는 데 유용한 많은 기능이 포함되어 있습니다. 가장 유용한 기능 중 일부가 여기에 예시되어 있습니다.
strlen 함수
strlen 함수는 문자열의 길이를 결정하는 데 사용됩니다. 예를 들어 strlen의 사용법을 배워봅시다:
#include <stdio.h>
#include <string.h>
int main()
{
char name[80];
int length;
printf("Enter your name: ");
gets(name);
length = strlen(name);
printf("Your name has %d characters\n", length);
return 0;
}
그리고 프로그램 실행은 다음과 같습니다.
Enter your name: Tarun Subhash Tyagi
Your name has 19 characters
Enter your name: Preeti Tarun
Your name has 12 characters
strcpy 함수
strcpy 함수는 한 문자열을 다른 문자열로 복사하는 데 사용됩니다. 예를 들어 이 함수의 사용법을 알아보겠습니다.
#include <stdio.h>
#include <string.h>
int main()
{
char first[80];
char second[80];
printf("Enter first string: ");
gets(first);
printf("Enter second string: ");
gets(second);
printf("first: %s, and second: %s Before strcpy()\n "
, first, second);
strcpy(second, first);
printf("first: %s, and second: %s After strcpy()\n",
first, second);
return 0;
}
프로그램의 출력은 다음과 같습니다.
Enter first string: Tarun
Enter second string: Tyagi
first: Tarun, and second: Tyagi Before strcpy()
first: Tarun, and second: Tarun After strcpy()
strcmp 함수
strcmp 함수는 두 문자열을 함께 비교하는 데 사용됩니다. 배열의 변수 이름은 해당 배열의 기본 주소를 가리킵니다. 따라서 다음을 사용하여 두 개의 문자열을 비교하려고 하면 두 개의 주소를 비교하게 되며 동일한 위치에 두 개의 값을 저장할 수 없기 때문에 절대 같지 않을 것입니다.
if (first == second) /* 문자열을 비교하는 것은 절대 할 수 없습니다. */
다음 예제에서는 strcmp 함수를 사용하여 두 문자열을 비교합니다.
#include <string.h>
int main()
{
char first[80], second[80];
int t;
for(t=1;t<=2;t++)
{
printf("\nEnter a string: ");
gets(first);
printf("Enter another string: ");
gets(second);
if (strcmp(first, second) == 0)
puts("The two strings are equal");
else
puts("The two strings are not equal");
}
return 0;
}
그리고 프로그램 실행은 다음과 같습니다.
Enter a string: Tarun
Enter another string: tarun
The two strings are not equal
Enter a string: Tarun
Enter another string: Tarun
The two strings are equal
strcat 함수
strcat 함수는 한 문자열을 다른 문자열에 결합하는 데 사용됩니다. 방법을 볼까요? 예의 도움으로:
#include <string.h>
int main()
{
char first[80], second[80];
printf("Enter a string: ");
gets(first);
printf("Enter another string: ");
gets(second);
strcat(first, second);
printf("The two strings joined together: %s\n",
first);
return 0;
}
그리고 프로그램 실행은 다음과 같습니다.
Enter a string: Data
Enter another string: Recovery
The two strings joined together: DataRecovery
strtok 함수
strtok 함수는 문자열에서 다음 토큰을 찾는 데 사용됩니다. 토큰은 가능한 구분 기호 목록으로 지정됩니다.
다음 예는 파일에서 한 줄의 텍스트를 읽고 구분 기호, 공백, 탭 및 새 줄을 사용하여 단어를 결정합니다. 그러면 각 단어가 별도의 줄에 표시됩니다.
#include <stdio.h>
#include <string.h>
int main()
{
FILE *in;
char line[80];
char *delimiters = " \t\n";
char *token;
if ((in = fopen("C:\\text.txt", "r")) == NULL)
{
puts("Unable to open the input file");
return 0;
}
/* Read each line one at a time */
while(!feof(in))
{
/* Get one line */
fgets(line, 80, in);
if (!feof(in))
{
/* Break the line up into words */
token = strtok(line, delimiters);
while (token != NULL)
{
puts(token);
/* Get the next word */
token = strtok(NULL, delimiters);
}
}
}
fclose(in);
return 0;
}
그것은 프로그램 위에, in = fopen("C:\\text.txt", "r"), opens and existing file C:\\text.txt. 지정된 경로에 존재하지 않거나 어떤 이유로든 파일을 열 수 없는 경우 화면에 오류 메시지가 표시됩니다.
이러한 기능 중 일부를 사용하는 다음 예를 고려하십시오.
#include <stdio.h>
#include <string.h>
void main()
{
char line[100], *sub_text;
/* initialize string */
strcpy(line,"hello, I am a string;");
printf("Line: %s\n", line);
/* add to end of string */
strcat(line," what are you?");
printf("Line: %s\n", line);
/* find length of string */
/* strlen brings back */
/* length as type size_t */
printf("Length of line: %d\n", (int)strlen(line));
/* find occurence of substrings */
if ( (sub_text = strchr ( line, 'W' ) )!= NULL )
printf("String starting with \"W\" ->%s\n",
sub_text);
if ( ( sub_text = strchr ( line, 'w' ) )!= NULL )
printf("String starting with \"w\" ->%s\n",
sub_text);
if ( ( sub_text = strchr ( sub_text, 'u' ) )!= NULL )
printf("String starting with \"w\" ->%s\n",
sub_text);
}
프로그램의 출력은 다음과 같이 표시됩니다.
Line: hello, I am a string;
Line: hello, I am a string; what are you?
Length of line: 35
String starting with "w" ->what are you?
String starting with "w" ->u?
기능
대규모 프로그램을 개발하고 유지 관리하는 가장 좋은 방법은 관리하기 쉬운 작은 조각으로 구성하는 것입니다(때때로 분할 정복이라고도 하는 기술). 함수를 통해 프로그래머는 프로그램을 모듈화할 수 있습니다.
함수를 사용하면 복잡한 프로그램을 작은 블록으로 나눌 수 있으며 각 블록은 쓰기, 읽기 및 유지 관리가 더 쉽습니다. 우리는 이미 main 함수를 접했고 표준 라이브러리에서 printf를 사용했습니다. 물론 우리는 우리 자신의 함수와 헤더 파일을 만들 수 있습니다. 함수의 레이아웃은 다음과 같습니다.
return-type function-name ( argument list if necessary )
{
local-declarations;
statements ;
return return-value;
}
return-type이 생략되면 C는 기본적으로 int로 설정됩니다. 반환 값은 선언된 유형이어야 합니다. 함수 내에서 선언된 모든 변수는 자신이 정의된 함수에서만 알려져 있다는 점에서 지역 변수라고 합니다.
일부 함수에는 함수와 함수를 호출한 모듈 간의 통신 방법을 제공하는 매개변수 목록이 있습니다. 매개변수는 함수 외부에서 사용할 수 없다는 점에서 지역 변수이기도 합니다. 지금까지 다룬 프로그램에는 모두 함수인 main이 있습니다.
함수는 값을 반환하지 않고 단순히 작업을 수행할 수 있으며, 이 경우 다음과 같은 레이아웃을 갖습니다.
void function-name ( argument list if necessary )
{
local-declarations ;
statements;
}
인수는 C 함수 호출에서 항상 값으로 전달됩니다. 이는 인수 값의 로컬 사본이 루틴으로 전달됨을 의미합니다. 함수 내부의 인수에 대한 변경 사항은 인수의 로컬 복사본에만 적용됩니다.
인수 목록에서 인수를 변경하거나 정의하려면 이 인수를 주소로 전달해야 합니다. 함수가 해당 인수의 값을 변경하지 않는 경우 일반 변수를 사용합니다. 함수가 해당 인수의 값을 변경하는 경우 포인터를 사용해야 합니다.
예를 들어 알아보겠습니다.
#include <stdio.h>
void exchange ( int *a, int *b )
{
int temp;
temp = *a;
*a = *b;
*b = temp;
printf(" From function exchange: ");
printf("a = %d, b = %d\n", *a, *b);
}
void main()
{
int a, b;
a = 5;
b = 7;
printf("From main: a = %d, b = %d\n", a, b);
exchange(&a, &b);
printf("Back in main: ");
printf("a = %d, b = %d\n", a, b);
}
그리고 이 프로그램의 출력은 다음과 같이 표시됩니다.
From main: a = 5, b = 7
From function exchange: a = 7, b = 5
Back in main: a = 7, b = 5
다른 예를 보겠습니다. 다음 예제에서는 1과 10 사이의 숫자의 제곱을 쓰는 square라는 함수를 사용합니다.
#include <stdio.h>
int square(int x); /* Function prototype */
int main()
{
int counter;
for (counter=1; counter<=10; counter++)
printf("Square of %d is %d\n", counter, square(counter));
return 0;
}
/* Define the function 'square' */
int square(int x)
{
return x * x;
}
이 프로그램의 출력은 다음과 같이 표시됩니다.
Square of 1 is 1
Square of 2 is 4
Square of 3 is 9
Square of 4 is 16
Square of 5 is 25
Square of 6 is 36
Square of 7 is 49
Square of 8 is 64
Square of 9 is 81
Square of 10 is 100
함수 원형 square는 정수 매개변수를 사용하고 정수를 반환하는 함수를 선언합니다. 컴파일러는 메인 프로그램에서 함수 호출에 도달하면 함수의 정의에 대해 함수 호출을 확인할 수 있습니다.
프로그램이 함수 square를 호출하는 라인에 도달하면 프로그램은 메인 프로그램을 통해 경로를 재개하기 전에 해당 함수로 점프하여 해당 함수를 실행합니다. 반환 형식이 없는 프로그램은 void를 사용하여 선언해야 합니다. 따라서 함수에 대한 매개변수는 값에 의한 전달 또는 참조에 의한 전달일 수 있습니다.
재귀 함수는 자신을 호출하는 함수입니다. 그리고 이 과정을 재귀라고 합니다.
값 함수로 전달
이전 예에서 square 함수의 매개변수는 값으로 전달됩니다. 이것은 변수의 복사본만 함수에 전달되었음을 의미합니다. 값에 대한 변경 사항은 호출 함수에 다시 반영되지 않습니다.
다음 예는 값에 의한 전달을 사용하고 전달된 매개변수의 값을 변경하며, 이는 호출하는 함수에 영향을 주지 않습니다. count_down 함수는 반환 유형이 없으므로 void로 선언되었습니다.
#include <stdio.h>
void count_down(int x);
int main()
{
int counter;
for (counter=1; counter<=10; counter++)
count_down(counter);
return 0;
}
void count_down(int x)
{
int counter;
for (counter = x; counter > 0; counter--)
{
printf("%d ", x);
x--;
}
putchar('\n');
}
프로그램의 출력은 다음과 같이 표시됩니다.
1
2 1
3 2 1
4 3 2 1
5 4 3 2 1
6 5 4 3 2 1
7 6 5 4 3 2 1
8 7 6 5 4 3 2 1
9 8 7 6 5 4 3 2 1
10 9 8 7 6 5 4 3 2 1
더 잘 이해하기 위해 다른 C Pass By Value 예제를 살펴보겠습니다. 다음 예제에서는 사용자가 입력한 1에서 30,000 사이의 숫자를 단어로 변환합니다.
#include <stdio.h>
void do_units(int num);
void do_tens(int num);
void do_teens(int num);
int main()
{
int num, residue;
do
{
printf("Enter a number between 1 and 30,000: ");
scanf("%d", &num);
} while (num < 1 || num > 30000);
residue = num;
printf("%d in words = ", num);
do_tens(residue/1000);
if (num >= 1000)
printf("thousand ");
residue %= 1000;
do_units(residue/100);
if (residue >= 100)
{
printf("hundred ");
}
if (num > 100 && num%100 > 0)
printf("and ");
residue %=100;
do_tens(residue);
putchar('\n');
return 0;
}
void do_units(int num)
{
switch(num)
{
case 1:
printf("one ");
break;
case 2:
printf("two ");
break;
case 3:
printf("three ");
break;
case 4:
printf("four ");
break;
case 5:
printf("five ");
break;
case 6:
printf("six ");
break;
case 7:
printf("seven ");
break;
case 8:
printf("eight ");
break;
case 9:
printf("nine ");
}
}
void do_tens(int num)
{
switch(num/10)
{
case 1:
do_teens(num);
break;
case 2:
printf("twenty ");
break;
case 3:
printf("thirty ");
break;
case 4:
printf("forty ");
break;
case 5:
printf("fifty ");
break;
case 6:
printf("sixty ");
break;
case 7:
printf("seventy ");
break;
case 8:
printf("eighty ");
break;
case 9:
printf("ninety ");
}
if (num/10 != 1)
do_units(num%10);
}
void do_teens(int num)
{
switch(num)
{
case 10:
printf("ten ");
break;
case 11:
printf("eleven ");
break;
case 12:
printf("twelve ");
break;
case 13:
printf("thirteen ");
break;
case 14:
printf("fourteen ");
break;
case 15:
printf("fifteen ");
break;
case 16:
printf("sixteen ");
break;
case 17:
printf("seventeen ");
break;
case 18:
printf("eighteen ");
break;
case 19:
printf("nineteen ");
}
}
프로그램의 출력은 다음과 같습니다.
Enter a number between 1 and 30,000: 12345
12345 in words = twelve thousand three hundred and forty five
참조에 의한 호출
함수를 참조로 호출하려면 변수 자체를 전달하는 대신 변수의 주소를 전달하십시오. 변수의 주소는 & 운영자. 다음은 실제 값 대신 변수의 주소를 전달하는 스왑 함수를 호출합니다.
swap(&x, &y);
역참조
지금 우리가 가진 문제는 함수 스왑이 변수가 아닌 주소로 전달되었기 때문에 스왑을 위해 변수의 주소가 아닌 실제 값을 보도록 변수를 역참조해야 한다는 것입니다. 그들.
역참조는 C에서 포인터(*) 표기법을 사용하여 수행됩니다. 간단히 말해서, 이것은 주소가 아닌 변수의 값을 참조하기 위해 사용하기 전에 각 변수 앞에 *를 두는 것을 의미합니다. 다음 프로그램은 두 값을 교환하기 위한 참조에 의한 전달을 보여줍니다.
#include <stdio.h>
void swap(int *x, int *y);
int main()
{
int x=6, y=10;
printf("Before the function swap, x = %d and y =
%d\n\n", x, y);
swap(&x, &y);
printf("After the function swap, x = %d and y =
%d\n\n", x, y);
return 0;
}
void swap(int *x, int *y)
{
int temp = *x;
*x = *y;
*y = temp;
}
프로그램의 출력을 보자:
Before the function swap, x = 6 and y = 10
After the function swap, x = 10 and y = 6
함수는 자신을 호출할 수 있는 재귀적일 수 있습니다. 자신을 호출할 때마다 함수의 현재 상태가 스택에 푸시되어야 합니다. 스택 오버플로를 생성하기 쉽기 때문에 이 사실을 기억하는 것이 중요합니다. 즉, 스택에 더 이상 데이터를 배치할 공간이 부족합니다.
다음 예는 재귀를 사용하여 숫자의 계승을 계산합니다. 계승은 1까지 아래의 모든 정수를 곱한 숫자입니다. 예를 들어 숫자 6의 계승은 다음과 같습니다.
Factorial 6 = 6 * 5 * 4 * 3 * 2 * 1
따라서 6의 계승은 720입니다. 위의 예에서 계승 6 = 6 * 계승 5임을 알 수 있습니다. 마찬가지로 계승 5 = 5 * 계승 4 등입니다.
다음은 계승 계산의 일반적인 규칙입니다.
factorial(n) = n * factorial(n-1)
위의 규칙은 1의 계승이 1이므로 n = 1일 때 종료됩니다. 예를 들어 더 잘 이해하도록 합시다.
#include <stdio.h>
long int factorial(int num);
int main()
{
int num;
long int f;
printf("Enter a number: ");
scanf("%d", &num);
f = factorial(num);
printf("factorial of %d is %ld\n", num, f);
return 0;
}
long int factorial(int num)
{
if (num == 1)
return 1;
else
return num * factorial(num-1);
}
이 프로그램의 실행 결과를 보자:
Enter a number: 7
factorial of 7 is 5040
C에서 메모리 할당
C 컴파일러에는 malloc.h에 정의된 메모리 할당 라이브러리가 있습니다. 메모리는 malloc 함수를 사용하여 예약되고 주소에 대한 포인터를 반환합니다. 하나의 매개변수, 필요한 메모리 크기(바이트)를 사용합니다.
다음 예는 "hello world" 문자열을 위한 공간을 할당합니다.
ptr = (char *)malloc(strlen("Hello world") + 1);
문자열 종료 문자 '\0'을 고려하려면 추가 1바이트가 필요합니다. (char *)를 캐스트라고 하며 반환 유형이 char *가 되도록 강제합니다.
데이터 유형의 크기가 다르고 malloc이 공간을 바이트 단위로 반환하므로 이식성 측면에서 할당할 크기를 지정할 때 sizeof 연산자를 사용하는 것이 좋습니다.
다음 예는 문자열을 문자 배열 버퍼로 읽은 다음 필요한 메모리의 정확한 양을 할당하고 "ptr"이라는 변수에 복사합니다.
#include <string.h>
#include <malloc.h>
int main()
{
char *ptr, buffer[80];
printf("Enter a string: ");
gets(buffer);
ptr = (char *)malloc((strlen(buffer) + 1) *
sizeof(char));
strcpy(ptr, buffer);
printf("You entered: %s\n", ptr);
return 0;
}
프로그램의 출력은 다음과 같습니다.
Enter a string: India is the best
You entered: India is the best
메모리 재할당
프로그래밍하는 동안 메모리를 재할당하려는 경우가 여러 번 있습니다. 이것은 realloc 함수로 수행됩니다. realloc 함수는 크기를 조정하려는 메모리의 기본 주소와 예약하려는 공간의 양이라는 두 개의 매개변수를 사용하여 기본 주소에 대한 포인터를 반환합니다.
msg라는 포인터를 위한 공간을 예약했고 이미 차지하고 있는 공간에 다른 문자열의 길이를 더한 만큼 공간을 재할당하고 싶다면 다음을 사용할 수 있습니다.
msg = (char *)realloc(msg, (strlen(msg) + strlen(버퍼) + 1)*sizeof(char));
다음 프로그램은 malloc, realloc 및 free의 사용을 보여줍니다. 사용자는 함께 결합된 일련의 문자열을 입력합니다. 프로그램은 빈 문자열이 입력되면 문자열 읽기를 중지합니다.
#include <string.h>
#include <malloc.h>
int main()
{
char buffer[80], *msg;
int firstTime=0;
do
{
printf("\nEnter a sentence: ");
gets(buffer);
if (!firstTime)
{
msg = (char *)malloc((strlen(buffer) + 1) *
sizeof(char));
strcpy(msg, buffer);
firstTime = 1;
}
else
{
msg = (char *)realloc(msg, (strlen(msg) +
strlen(buffer) + 1) * sizeof(char));
strcat(msg, buffer);
}
puts(msg);
} while(strcmp(buffer, ""));
free(msg);
return 0;
}
프로그램의 출력은 다음과 같습니다.
Enter a sentence: Once upon a time
Once upon a time
Enter a sentence: there was a king
Once upon a timethere was a king
Enter a sentence: the king was
Once upon a timethere was a kingthe king was
Enter a sentence:
Once upon a timethere was a kingthe king was
메모리 해제
할당된 메모리로 작업을 마치면 리소스를 확보하고 속도를 향상시키므로 메모리를 해제하는 것을 잊지 말아야 합니다. 할당된 메모리를 해제하려면 free 함수를 사용하십시오.
free(ptr);
구조
C에는 기본 데이터 유형과 함께 공통 이름으로 서로 관련된 데이터 항목을 그룹화할 수 있는 구조 메커니즘이 있습니다. 이를 일반적으로 사용자 정의 유형이라고 합니다.
키워드 struct는 구조 정의를 시작하고 태그는 구조에 고유한 이름을 제공합니다. 구조에 추가된 데이터 유형 및 변수 이름은 구조의 구성원입니다. 결과는 유형 지정자로 사용할 수 있는 구조 템플릿입니다. 다음은 월 태그가 있는 구조입니다.
struct month
{
char name[10];
char abbrev[4];
int days;
};
구조 유형은 일반적으로 typedef 문을 사용하여 파일 시작 부분 근처에 정의됩니다. typedef는 프로그램 전체에서 사용할 수 있도록 새 유형을 정의하고 이름을 지정합니다. typedef는 일반적으로 파일의 #define 및 #include 문 바로 뒤에 발생합니다.
typedef 키워드는 구조체 이름으로 struct 키워드를 지정하는 대신 구조체를 참조하는 단어를 정의하는 데 사용할 수 있습니다. typedef의 이름은 대문자로 지정하는 것이 일반적입니다. 다음은 구조 정의의 예입니다.
typedef struct {
char name[64];
char course[128];
int age;
int year;
} student; 이것은 새로운 유형의 학생을 정의합니다. 학생 유형의 변수는 다음과 같이 선언할 수 있습니다.
student st_rec;
이것이 int 또는 float를 선언하는 것과 얼마나 유사한지 주목하십시오. 변수 이름은 st_rec이며 이름, 과정, 연령 및 연도라는 멤버가 있습니다. 비슷하게,
typedef struct element
{
char data;
struct element *next;
} STACKELEMENT;
A variable of the user defined type struct element may now be declared as follows.
STACKELEMENT *stack;
다음 구조를 고려하십시오.
struct student
{
char *name;
int grade;
};
struct student에 대한 포인터는 다음과 같이 정의할 수 있습니다.
struct student *hnc;
When accessing a pointer to a structure, the member pointer operator, -> is used instead of the dot operator. To add a grade to a structure,
s.grade = 50;
다음과 같이 구조에 등급을 지정할 수 있습니다.
s->grade = 50;
기본 데이터 유형과 마찬가지로 전달된 매개변수에 대한 함수의 변경 사항을 유지하려면 참조로 전달(주소 전달)해야 합니다. 메커니즘은 기본 데이터 유형과 정확히 동일합니다. 주소를 전달하고 포인터 표기법을 사용하여 변수를 참조하십시오.
구조를 정의했으면 해당 인스턴스를 선언하고 점 표기법을 사용하여 멤버에 값을 할당할 수 있습니다. 다음 예는 월 구조의 사용을 보여줍니다.
#include <stdio.h>
#include <string.h>
struct month
{
char name[10];
char abbreviation[4];
int days;
};
int main()
{
struct month m;
strcpy(m.name, "January");
strcpy(m.abbreviation, "Jan");
m.days = 31;
printf("%s is abbreviated as %s and has %d days\n", m.name, m.abbreviation, m.days);
return 0;
}
프로그램의 출력은 다음과 같습니다.
January is abbreviated as Jan and has 31 days
모든 ANSI C 컴파일러를 사용하면 멤버 단위 복사를 수행하여 한 구조를 다른 구조에 할당할 수 있습니다. m1 및 m2라는 월 구조가 있는 경우 다음을 사용하여 m1에서 m2까지 값을 할당할 수 있습니다.
- 포인터 멤버가 있는 구조
- 구조가 초기화됩니다.
- 함수에 구조 전달.
- 포인터와 구조.
C에서 포인터 멤버가 있는 구조
고정 크기 배열에 문자열을 보관하는 것은 메모리를 비효율적으로 사용하는 것입니다. 더 효율적인 접근 방식은 포인터를 사용하는 것입니다. 포인터는 일반 포인터 정의에서 사용되는 것과 똑같은 방식으로 구조에서 사용됩니다. 예를 들어 보겠습니다.
#include <string.h>
#include <malloc.h>
struct month
{
char *name;
char *abbreviation;
int days;
};
int main()
{
struct month m;
m.name = (char *)malloc((strlen("January")+1) *
sizeof(char));
strcpy(m.name, "January");
m.abbreviation = (char *)malloc((strlen("Jan")+1) *
sizeof(char));
strcpy(m.abbreviation, "Jan");
m.days = 31;
printf("%s is abbreviated as %s and has %d days\n",
m.name, m.abbreviation, m.days);
return 0;
}
프로그램의 출력은 다음과 같습니다.
January는 Jan으로 약칭되며 31일이 있습니다.
C의 구조 이니셜라이저
구조에 대한 초기 값 세트를 제공하기 위해 선언문에 이니셜라이저를 추가할 수 있습니다. 월은 1에서 시작하지만 배열은 C에서 0에서 시작하므로 다음 예제에서는 정크라고 하는 위치 0의 추가 요소가 사용되었습니다.
#include <stdio.h>
#include <string.h>
struct month
{
char *name;
char *abbreviation;
int days;
} month_details[] =
{
"Junk", "Junk", 0,
"January", "Jan", 31,
"February", "Feb", 28,
"March", "Mar", 31,
"April", "Apr", 30,
"May", "May", 31,
"June", "Jun", 30,
"July", "Jul", 31,
"August", "Aug", 31,
"September", "Sep", 30,
"October", "Oct", 31,
"November", "Nov", 30,
"December", "Dec", 31
};
int main()
{
int counter;
for (counter=1; counter<=12; counter++)
printf("%s is abbreviated as %s and has %d days\n",
month_details[counter].name,
month_details[counter].abbreviation,
month_details[counter].days);
return 0;
}
그리고 출력은 다음과 같이 표시됩니다.
January is abbreviated as Jan and has 31 days
February is abbreviated as Feb and has 28 days
March is abbreviated as Mar and has 31 days
April is abbreviated as Apr and has 30 days
May is abbreviated as May and has 31 days
June is abbreviated as Jun and has 30 days
July is abbreviated as Jul and has 31 days
August is abbreviated as Aug and has 31 days
September is abbreviated as Sep and has 30 days
October is abbreviated as Oct and has 31 days
November is abbreviated as Nov and has 30 days
December is abbreviated as Dec and has 31 days
C의 함수에 구조 전달
구조는 기본 데이터 유형과 마찬가지로 함수에 매개변수로 전달될 수 있습니다. 다음 예제에서는 isLeapYear 함수에 전달된 date라는 구조를 사용하여 연도가 윤년인지 확인합니다.
일반적으로 day 값만 전달하지만 구조를 함수에 전달하는 방법을 설명하기 위해 전체 구조가 전달됩니다.
#include <stdio.h>
#include <string.h>
struct month
{
char *name;
char *abbreviation;
int days;
} month_details[] =
{
"Junk", "Junk", 0,
"January", "Jan", 31,
"February", "Feb", 28,
"March", "Mar", 31,
"April", "Apr", 30,
"May", "May", 31,
"June", "Jun", 30,
"July", "Jul", 31,
"August", "Aug", 31,
"September", "Sep", 30,
"October", "Oct", 31,
"November", "Nov", 30,
"December", "Dec", 31
};
struct date
{
int day;
int month;
int year;
};
int isLeapYear(struct date d);
int main()
{
struct date d;
printf("Enter the date (eg: 11/11/1980): ");
scanf("%d/%d/%d", &d.day, &d.month, &d.year);
printf("The date %d %s %d is ", d.day,
month_details[d.month].name, d.year);
if (isLeapYear(d) == 0)
printf("not ");
puts("a leap year");
return 0;
}
int isLeapYear(struct date d)
{
if ((d.year % 4 == 0 && d.year % 100 != 0) ||
d.year % 400 == 0)
return 1;
return 0;
}
그리고 프로그램 실행은 다음과 같습니다.
Enter the date (eg: 11/11/1980): 9/12/1980
The date 9 December 1980 is a leap year
다음 예제에서는 학생 이름과 학년을 저장하기 위해 구조체 배열을 동적으로 할당합니다. 그런 다음 등급은 오름차순으로 사용자에게 다시 표시됩니다.
#include <string.h>
#include <malloc.h>
struct student
{
char *name;
int grade;
};
void swap(struct student *x, struct student *y);
int main()
{
struct student *group;
char buffer[80];
int spurious;
int inner, outer;
int counter, numStudents;
printf("How many students are there in the group: ");
scanf("%d", &numStudents);
group = (struct student *)malloc(numStudents *
sizeof(struct student));
for (counter=0; counter<numStudents; counter++)
{
spurious = getchar();
printf("Enter the name of the student: ");
gets(buffer);
group[counter].name = (char *)malloc((strlen(buffer)+1) * sizeof(char));
strcpy(group[counter].name, buffer);
printf("Enter grade: ");
scanf("%d", &group[counter].grade);
}
for (outer=0; outer<numStudents; outer++)
for (inner=0; inner<outer; inner++)
if (group[outer].grade <
group[inner].grade)
swap(&group[outer], &group[inner]);
puts("The group in ascending order of grades ...");
for (counter=0; counter<numStudents; counter++)
printf("%s achieved Grade %d \n”,
group[counter].name,
group[counter].grade);
return 0;
}
void swap(struct student *x, struct student *y)
{
struct student temp;
temp.name = (char *)malloc((strlen(x->name)+1) *
sizeof(char));
strcpy(temp.name, x->name);
temp.grade = x->grade;
x->grade = y->grade;
x->name = (char *)malloc((strlen(y->name)+1) *
sizeof(char));
strcpy(x->name, y->name);
y->grade = temp.grade;
y->name = (char *)malloc((strlen(temp.name)+1) *
sizeof(char));
strcpy(y->name, temp.name);
}
출력 실행은 다음과 같습니다.
How many students are there in the group: 4
Enter the name of the student: Anuraaj
Enter grade: 7
Enter the name of the student: Honey
Enter grade: 2
Enter the name of the student: Meetushi
Enter grade: 1
Enter the name of the student: Deepti
Enter grade: 4
The group in ascending order of grades ...
Meetushi achieved Grade 1
Honey achieved Grade 2
Deepti achieved Grade 4
Anuraaj achieved Grade 7
연합
공용체를 사용하면 유형이 다른 동일한 데이터를 보거나 동일한 데이터를 다른 이름으로 사용할 수 있습니다. 조합은 구조와 유사합니다. 구조체와 동일한 방식으로 공용체를 선언하고 사용합니다.
공용체는 한 번에 구성원 중 하나만 사용할 수 있다는 점에서 구조와 다릅니다. 그 이유는 간단합니다. Union의 모든 구성원은 동일한 메모리 영역을 차지합니다. 그것들은 서로의 위에 놓여 있습니다.
Union은 구조체와 같은 방식으로 정의되고 선언됩니다. 선언의 유일한 차이점은 구조체 대신 키워드 union이 사용된다는 것입니다. char 변수와 정수 변수의 단순 합집합을 정의하려면 다음과 같이 작성합니다.
union shared {
char c;
int i;
};
공유된 이 공용체는 문자 값 c 또는 정수 값 i를 보유할 수 있는 공용체의 인스턴스를 만드는 데 사용할 수 있습니다. 이것은 OR 조건입니다. 두 값을 모두 보유하는 구조와 달리 공용체는 한 번에 하나의 값만 보유할 수 있습니다.
공용체는 선언 시 초기화될 수 있습니다. 한 번에 하나의 멤버만 사용할 수 있고 하나만 초기화할 수 있기 때문입니다. 혼동을 피하기 위해 공용체의 첫 번째 구성원만 초기화할 수 있습니다. 다음 코드는 선언되고 초기화되는 공유 공용체의 인스턴스를 보여줍니다.
union shared generic_variable = {`@'};
구조의 첫 번째 멤버가 초기화될 때와 마찬가지로 generic_variable 공용체가 초기화되었음을 주목하세요.
구조체 멤버와 마찬가지로 멤버 연산자(.)를 사용하여 개별 공용 구조체 멤버를 사용할 수 있습니다. 그러나 조합원에 접근하는 데에는 중요한 차이점이 있습니다.
한 번에 하나의 조합 구성원만 액세스해야 합니다. Union은 구성원을 서로 겹쳐서 저장하므로 한 번에 한 구성원에게만 액세스하는 것이 중요합니다.
통합 키워드
union tag {
union_member(s);
/* additional statements may go here */
}instance;
Union 키워드는 Union 선언에 사용됩니다. 공용체는 단일 이름으로 그룹화된 하나 이상의 변수(union_members)의 모음입니다. 또한, 이러한 각 조합원은 동일한 메모리 영역을 차지합니다.
키워드 union은 공용체 정의의 시작을 식별합니다. 그 뒤에는 Union에 부여된 이름인 태그가 옵니다. 태그 다음은 중괄호로 묶인 공용체 구성원입니다.
실제 공용체 선언인 인스턴스도 정의할 수 있습니다. 인스턴스 없이 구조를 정의하면 나중에 프로그램에서 구조를 선언하는 데 사용할 수 있는 템플릿일 뿐입니다. 다음은 템플릿 형식입니다.
union tag {
union_member(s);
/* additional statements may go here */
};
템플릿을 사용하려면 다음 형식을 사용합니다.
유니온 태그 인스턴스;
이 형식을 사용하려면 이전에 주어진 태그로 공용체를 선언했어야 합니다.
/* 태그라는 유니온 템플릿 선언 */
union tag {
int num;
char alps;
}
/* Use the union template */
union tag mixed_variable;
/* Declare a union and instance together */
union generic_type_tag {
char c;
int i;
float f;
double d;
} generic;
/* Initialize a union. */
union date_tag {
char full_date[9];
struct part_date_tag {
char month[2];
char break_value1;
char day[2];
char break_value2;
char year[2];
} part_date;
}date = {"09/12/80"};
예제를 통해 더 잘 이해합시다.
#include <stdio.h>
int main()
{
union
{
int value; /* This is the first part of the union */
struct
{
char first; /* These two values are the second part of it */
char second;
} half;
} number;
long index;
for (index = 12 ; index < 300000L ; index += 35231L)
{
number.value = index;
printf("%8x %6x %6x\n", number.value,
number.half.first,
number.half.second);
}
return 0;
}
그리고 프로그램의 출력은 다음과 같이 표시됩니다.
c c 0
89ab ffab ff89
134a 4a 13
9ce9 ffe9 ff9c
2688 ff88 26
b027 27 ffb0
39c6 ffc6 39
c365 65 ffc3
4d04 4 4d
데이터 복구에서 통합의 실제 사용
이제 유니온의 실제 사용이 데이터 복구 프로그래밍임을 봅시다. 약간의 예를 들어 보겠습니다. 다음 프로그램은 플로피 디스크 드라이브(a: )용 불량 섹터 검사 프로그램의 작은 모델이지만 불량 섹터 검사 소프트웨어의 완전한 모델은 아닙니다.
프로그램을 살펴보겠습니다.
#include<dos.h>
#include<conio.h>
int main()
{
int rp, head, track, sector, status;
char *buf;
union REGS in, out;
struct SREGS s;
clrscr();
/* Reset the disk system to initialize to disk */
printf("\n Resetting the disk system....");
for(rp=0;rp<=2;rp++)
{
in.h.ah = 0;
in.h.dl = 0x00;
int86(0x13,&in,&out);
}
printf("\n\n\n Now Testing the Disk for Bad Sectors....");
/* scan for bad sectors */
for(track=0;track<=79;track++)
{
for(head=0;head<=1;head++)
{
for(sector=1;sector<=18;sector++)
{
in.h.ah = 0x04;
in.h.al = 1;
in.h.dl = 0x00;
in.h.ch = track;
in.h.dh = head;
in.h.cl = sector;
in.x.bx = FP_OFF(buf);
s.es = FP_SEG(buf);
int86x(0x13,&in,&out,&s);
if(out.x.cflag)
{
status=out.h.ah;
printf("\n track:%d Head:%d Sector:%d Status ==0x%X",track,head,sector,status);
}
}
}
}
printf("\n\n\nDone");
return 0;
}
이제 플로피 디스크에 불량 섹터가 있는 경우 출력이 어떻게 보이는지 살펴보겠습니다.
디스크 시스템 재설정 중....
지금 디스크에 불량 섹터가 있는지 테스트 중입니다....
track:0 Head:0 Sector:4 Status ==0xA
track:0 Head:0 Sector:5 Status ==0xA
track:1 Head:0 Sector:4 Status ==0xA
track:1 Head:0 Sector:5 Status ==0xA
track:1 Head:0 Sector:6 Status ==0xA
track:1 Head:0 Sector:7 Status ==0xA
track:1 Head:0 Sector:8 Status ==0xA
track:1 Head:0 Sector:11 Status ==0xA
track:1 Head:0 Sector:12 Status ==0xA
track:1 Head:0 Sector:13 Status ==0xA
track:1 Head:0 Sector:14 Status ==0xA
track:1 Head:0 Sector:15 Status ==0xA
track:1 Head:0 Sector:16 Status ==0xA
track:1 Head:0 Sector:17 Status ==0xA
track:1 Head:0 Sector:18 Status ==0xA
track:1 Head:1 Sector:5 Status ==0xA
track:1 Head:1 Sector:6 Status ==0xA
track:1 Head:1 Sector:7 Status ==0xA
track:1 Head:1 Sector:8 Status ==0xA
track:1 Head:1 Sector:9 Status ==0xA
track:1 Head:1 Sector:10 Status ==0xA
track:1 Head:1 Sector:11 Status ==0xA
track:1 Head:1 Sector:12 Status ==0xA
track:1 Head:1 Sector:13 Status ==0xA
track:1 Head:1 Sector:14 Status ==0xA
track:1 Head:1 Sector:15 Status ==0xA
track:1 Head:1 Sector:16 Status ==0xA
track:1 Head:1 Sector:17 Status ==0xA
track:1 Head:1 Sector:18 Status ==0xA
track:2 Head:0 Sector:4 Status ==0xA
track:2 Head:0 Sector:5 Status ==0xA
track:14 Head:0 Sector:6 Status ==0xA
Done
이 프로그램에서 디스크의 불량 섹터를 확인하고 디스크 시스템을 재설정하는 데 사용되는 기능과 인터럽트를 이해하는 것이 약간 어려울 수 있습니다. 그러나 걱정할 필요는 없습니다. BIOS와 인터럽트 프로그래밍에서 이 모든 것을 배울 것입니다. 섹션은 다음 장 뒷부분에 있습니다.
C에서 파일 처리
C에서 파일 액세스는 스트림을 파일과 연결하여 달성됩니다. C는 파일 포인터라는 새로운 데이터 유형을 사용하여 파일과 통신합니다. 이 유형은 stdio.h 내에 정의되며 FILE *으로 작성됩니다. output_file이라는 파일 포인터는 다음과 같은 문에서 선언됩니다.
FILE *output_file;
fopen 함수의 파일 모드
프로그램이 파일에 액세스하려면 먼저 파일을 열어야 합니다. 이것은 필요한 파일 포인터를 반환하는 fopen 함수를 사용하여 수행됩니다. 어떤 이유로든 파일을 열 수 없으면 NULL 값이 반환됩니다. 일반적으로 다음과 같이 fopen을 사용합니다.
if ((output_file = fopen("output_file", "w")) == NULL)
fprintf(stderr, "Cannot open %s\n",
"output_file");
fopen은 두 개의 인수를 취합니다. 둘 다 문자열입니다. 첫 번째는 열려는 파일의 이름이고, 두 번째는 일반적으로 r, a 또는 w 중 하나인 액세스 문자입니다. 파일은 여러 모드로 열릴 수 있습니다. 다음 표와 같이.
| File Modes |
| r |
Open a text file for reading. |
| w |
Create a text file for writing. If the file exists, it is overwritten. |
| a |
Open a text file in append mode. Text is added to the end of the file. |
| rb |
Open a binary file for reading. |
| wb |
Create a binary file for writing. If the file exists, it is overwritten. |
| ab |
Open a binary file in append mode. Data is added to the end of the file. |
| r+ |
Open a text file for reading and writing. |
| w+ |
Create a text file for reading and writing. If the file exists, it is overwritten. |
| a+ |
Open a text file for reading and writing at the end. |
| r+b or rb+ |
Open binary file for reading and writing. |
| w+b or wb+ |
Create a binary file for reading and writing. If the file exists, it is overwritten. |
| a+b or ab+ |
Open a text file for reading and writing at the end. |
업데이트 모드는 fseek, fsetpos 및 되감기 기능과 함께 사용됩니다. fopen 함수는 파일 포인터를 반환하거나 오류가 발생하면 NULL을 반환합니다.
다음 예는 tarun.txt 파일을 읽기 전용 모드로 엽니다. 파일이 존재하는지 테스트하는 것은 좋은 프로그래밍 방법입니다.
if ((in = fopen("tarun.txt", "r")) == NULL)
{
puts("Unable to open the file");
return 0;
}
파일 닫기
파일은 fclose 함수를 사용하여 닫힙니다. 구문은 다음과 같습니다.
fclose(in);
파일 읽기
feof 함수는 파일의 끝을 테스트하는 데 사용됩니다. fgetc, fscanf 및 fgets 함수는 파일에서 데이터를 읽는 데 사용됩니다.
다음 예는 fgetc를 사용하여 한 번에 한 문자씩 파일을 읽는 화면에 파일의 내용을 나열합니다.
#include <stdio.h>
int main()
{
FILE *in;
int key;
if ((in = fopen("tarun.txt", "r")) == NULL)
{
puts("Unable to open the file");
return 0;
}
while (!feof(in))
{
key = fgetc(in);
/* The last character read is the end of file marker so don't print it */
if (!feof(in))
putchar(key);
}
fclose(in);
return 0;
}
파일의 데이터가 fscanf와 함께 사용되는 형식 문자열 형식인 경우 fscanf 함수를 사용하여 다음 예와 같이 파일에서 다양한 데이터 유형을 읽을 수 있습니다.
fscanf(in, "%d/%d/%d", &day, &month, &year);
fgets 함수는 파일에서 여러 문자를 읽는 데 사용됩니다. stdin은 표준 입력 파일 스트림이고 fgets 함수는 입력을 제어하는 데 사용할 수 있습니다.
파일에 쓰기
데이터는 fputc 및 fprintf를 사용하여 파일에 쓸 수 있습니다. 다음 예제에서는 fgetc 및 fputc 함수를 사용하여 텍스트 파일의 복사본을 만듭니다.
#include <stdio.h>
int main()
{
FILE *in, *out;
int key;
if ((in = fopen("tarun.txt", "r")) == NULL)
{
puts("Unable to open the file");
return 0;
}
out = fopen("copy.txt", "w");
while (!feof(in))
{
key = fgetc(in);
if (!feof(in))
fputc(key, out);
}
fclose(in);
fclose(out);
return 0;
}
fprintf 함수는 형식이 지정된 데이터를 파일에 쓰는 데 사용할 수 있습니다.
fprintf(out, "Date: %02d/%02d/%02d\n",
day, month, year);
C를 사용한 명령줄 인수
main() 함수를 선언하기 위한 ANSI C 정의는 다음 중 하나입니다.
int main() or int main(int argc, char **argv)
두 번째 버전에서는 명령줄에서 인수를 전달할 수 있습니다. 매개변수 argc는 인수 카운터이며 명령줄에서 전달된 매개변수 수를 포함합니다. 매개변수 argv는 전달된 실제 매개변수를 나타내는 문자열에 대한 포인터 배열인 인수 벡터입니다.
다음 예는 명령줄에서 전달되는 인수의 수에 제한 없이 허용하고 출력합니다. argv[0]은 실제 프로그램입니다. 프로그램은 명령 프롬프트에서 실행해야 합니다.
#include <stdio.h>
int main(int argc, char **argv)
{
int counter;
puts("The arguments to the program are:");
for (counter=0; counter<argc; counter++)
puts(argv[counter]);
return 0;
}
If the program name was count.c, it could be called as follows from the command line.
count 3
or
count 7
or
count 192 etc.
다음 예제에서는 파일 처리 루틴을 사용하여 텍스트 파일을 새 파일로 복사합니다. 예를 들어 명령줄 인수는 다음과 같이 호출할 수 있습니다.
txtcpy one.txt two.txt
#include <stdio.h>
int main(int argc, char **argv)
{
FILE *in, *out;
int key;
if (argc < 3)
{
puts("Usage: txtcpy source destination\n");
puts("The source must be an existing file");
puts("If the destination file exists, it will be
overwritten");
return 0;
}
if ((in = fopen(argv[1], "r")) == NULL)
{
puts("Unable to open the file to be copied");
return 0;
}
if ((out = fopen(argv[2], "w")) == NULL)
{
puts("Unable to open the output file");
return 0;
}
while (!feof(in))
{
key = fgetc(in);
if (!feof(in))
fputc(key, out);
}
fclose(in);
fclose(out);
return 0;
}
비트 조작기
하드웨어 수준에서 데이터는 이진수로 표시됩니다. 숫자 59의 이진 표현은 111011입니다. 비트 0은 최하위 비트이고 이 경우 비트 5는 최상위 비트입니다.
각 비트 세트는 비트 세트의 2승으로 계산됩니다. 비트 연산자를 사용하면 비트 수준에서 정수 변수를 조작할 수 있습니다. 다음은 숫자 59의 이진 표현을 보여줍니다.
| binary representation of the number 59 |
| bit 5 4 3 2 1 0 |
| 2 power n 32 16 8 4 2 1 |
| set 1 1 1 0 1 1 |
3비트로 0부터 7까지의 숫자를 표현할 수 있습니다. 다음 표는 0부터 7까지의 숫자를 2진법으로 나타낸 것입니다.
| Binary Digits |
| 000 |
0 |
| 001 |
1 |
| 010 |
2 |
| 011 |
3 |
| 100 |
4 |
| 101 |
5 |
| 110 |
6 |
| 111 |
7 |
다음 표는 이진수를 조작하는 데 사용할 수 있는 비트 연산자를 나열합니다.
| Binary Digits |
| & |
Bitwise AND |
| | |
Bitwise OR |
| ^ |
Bitwise Exclusive OR |
| ~ |
Bitwise Complement |
| << |
Bitwise Shift Left |
| >> |
Bitwise Shift Right |
비트 AND
비트 AND는 두 비트가 모두 설정된 경우에만 True입니다. 다음 예는 숫자 23과 12에 대한 비트 AND 결과를 보여줍니다.
| 10111 (23)
01100 (12) AND
____________________
00100 (result = 4) |
마스크 값을 사용하여 특정 비트가 설정되었는지 확인할 수 있습니다. 비트 1과 3이 설정되었는지 확인하려면 숫자를 10으로 마스킹하고(비트 1과 3인 경우 값) 마스크에 대해 결과를 테스트할 수 있습니다.
#include <stdio.h>
int main()
{
int num, mask = 10;
printf("Enter a number: ");
scanf("%d", &num);
if ((num & mask) == mask)
puts("Bits 1 and 3 are set");
else
puts("Bits 1 and 3 are not set");
return 0;
}
비트 OR
비트 OR은 두 비트 중 하나가 설정되어 있으면 참입니다. 다음은 숫자 23과 12에 대한 비트 OR의 결과를 보여줍니다.
| 10111 (23)
01100 (12) OR
______________________
11111 (result = 31) |
마스크를 사용하여 비트가 설정되었는지 확인할 수 있습니다. 다음 예에서는 비트 2가 설정되었는지 확인합니다.
#include <stdio.h>
int main()
{
int num, mask = 4;
printf("Enter a number: ");
scanf("%d", &num);
num |= mask;
printf("After ensuring bit 2 is set: %d\n", num);
return 0;
}
비트 배타적 OR
비트 배타적 OR은 비트 중 하나가 설정되고 둘 다 설정되지 않은 경우 True입니다. 다음은 숫자 23과 12에 대한 비트별 배타적 OR의 결과를 보여줍니다.
| 10111 (23)
01100 (12) Exclusive OR (XOR)
_____________________________
11011 (result = 27) |
배타적 OR에는 몇 가지 흥미로운 속성이 있습니다. 숫자 단독으로 배타적 OR을 수행하는 경우 0은 0으로 유지되고 1은 둘 다 설정할 수 없으므로 0으로 설정되므로 자체적으로 0으로 설정됩니다.
결과적으로 숫자를 다른 숫자와 배타적 논리합(Exclusive OR)한 다음 다른 숫자와 다시 배타적 OR(Exclusive OR)을 하면 결과는 원래 숫자가 된다. 위의 예에서 사용된 숫자로 이것을 시도할 수 있습니다.
23 XOR 12 = 27
27 XOR 12 = 23
27 XOR 23 = 12
이 기능은 암호화에 사용할 수 있습니다. 다음 프로그램은 23이라는 암호화 키를 사용하여 사용자가 입력한 숫자의 속성을 보여줍니다.
#include <stdio.h>
int main()
{
int num, key = 23;
printf("Enter a number: ");
scanf("%d", &num);
num ^= key;
printf("Exclusive OR with %d gives %d\n", key, num);
num ^= key;
printf("Exclusive OR with %d gives %d\n", key, num);
return 0;
}
비트 칭찬
비트별 칭찬은 비트를 켜거나 끄는 1의 칭찬 연산자입니다. 1이면 0으로, 0이면 1로 설정합니다.
#include <stdio.h>
int main()
{
int num = 0xFFFF;
printf("The compliment of %X is %X\n", num, ~num);
return 0;
}
왼쪽으로 비트 시프트
Bitwise Shift Left 연산자는 숫자를 왼쪽으로 이동합니다. 숫자가 왼쪽으로 이동함에 따라 최상위 비트가 손실되고 비워진 최하위 비트는 0입니다. 다음은 43의 이진 표현을 보여줍니다.
0101011 (decimal 43)
비트를 왼쪽으로 이동하면 최상위 비트(이 경우 0)가 손실되고 최하위 비트에서 숫자가 0으로 채워집니다. 다음은 결과 번호입니다.
1010110 (decimal 86)
오른쪽으로 비트 시프트
Bitwise Shift Right 연산자는 숫자를 오른쪽으로 이동합니다. 비워진 최상위 비트에 0이 도입되고 비워진 최하위 비트가 손실됩니다. 다음은 숫자 43의 이진 표현을 보여줍니다.
0101011(십진수 43)
비트를 오른쪽으로 이동하면 최하위 비트(이 경우 1)가 손실되고 최상위 비트에서 숫자가 0으로 채워집니다. 다음은 결과 번호입니다.
0010101(십진수 21)
다음 프로그램은 Bitwise Shift Right와 Bitwise AND를 사용하여 숫자를 16비트 이진수로 표시합니다. 숫자는 16에서 0으로 차례로 오른쪽으로 이동하고 비트가 설정되었는지 확인하기 위해 1과 비트 AND 연산을 수행합니다. 다른 방법은 Bitwise OR 연산자와 함께 연속 마스크를 사용하는 것입니다.
#include <stdio.h>
int main()
{
int counter, num;
printf("Enter a number: ");
scanf("%d", &num);
printf("%d is binary: ", num);
for (counter=15; counter>=0; counter--)
printf("%d", (num >> counter) & 1);
putchar('\n');
return 0;
}
이진법을 위한 함수 – 십진법 변환
다음에 주어진 두 함수는 바이너리에서 10진수로 및 10진수에서 바이너리로 변환을 위한 것입니다. 다음에 주어진 10진수를 해당 2진수로 변환하는 기능은 최대 32 – Bit 2진수를 지원합니다. 요구 사항에 따라 변환을 위해 이 프로그램 또는 이전에 제공된 프로그램을 사용할 수 있습니다.
10진수에서 2진수로의 변환 기능:
void Decimal_to_Binary(void)
{
int input =0;
int i;
int count = 0;
int binary [32]; /* 32 Bit, MAXIMUM 32 elements */
printf ("Enter Decimal number to convert into
Binary :");
scanf ("%d", &input);
do
{
i = input%2; /* MOD 2 to get 1 or a 0*/
binary[count] = i; /* Load Elements into the Binary Array */
input = input/2; /* Divide input by 2 to decrement via binary */
count++; /* Count how many elements are needed*/
}while (input > 0);
/* Reverse and output binary digits */
printf ("Binary representation is: ");
do
{
printf ("%d", binary[count - 1]);
count--;
} while (count > 0);
printf ("\n");
}
2진법을 10진법으로 변환하는 함수:
다음 함수는 이진수를 해당 10진수로 변환하는 것입니다.
void Binary_to_Decimal(void)
{
char binaryhold[512];
char *binary;
int i=0;
int dec = 0;
int z;
printf ("Please enter the Binary Digits.\n");
printf ("Binary digits are either 0 or 1 Only ");
printf ("Binary Entry : ");
binary = gets(binaryhold);
i=strlen(binary);
for (z=0; z<i; ++z)
{
dec=dec*2+(binary[z]=='1'? 1:0); /* if Binary[z] is
equal to 1,
then 1 else 0 */
}
printf ("\n");
printf ("Decimal value of %s is %d",
binary, dec);
printf ("\n");
}
디버깅 및 테스트
구문 오류
구문은 문장에서 요소의 문법, 구조 및 순서를 나타냅니다. 구문 오류는 세미콜론으로 문장을 끝내는 것을 잊는 것과 같이 규칙을 어길 때 발생합니다. 프로그램을 컴파일할 때 컴파일러는 발생할 수 있는 구문 오류 목록을 생성합니다.
좋은 컴파일러는 오류에 대한 설명과 함께 목록을 출력하고 가능한 솔루션을 제공할 수 있습니다. 오류를 수정하면 다시 컴파일할 때 추가 오류가 표시될 수 있습니다. 그 이유는 이전 오류로 인해 프로그램의 구조가 변경되어 원래 컴파일 중에 추가 오류가 억제되었음을 의미하기 때문입니다.
마찬가지로, 한 번의 실수로 여러 개의 오류가 발생할 수 있습니다. 올바르게 컴파일되고 실행되는 프로그램의 주요 기능 끝에 세미콜론을 넣어보십시오. 다시 컴파일하면 엄청난 오류 목록이 표시되지만 세미콜론의 위치가 잘못되었을 뿐입니다.
구문 오류뿐 아니라 컴파일러도 경고를 발행할 수 있습니다. 경고는 오류가 아니지만 프로그램 실행 중에 문제를 일으킬 수 있습니다. 예를 들어 배정밀도 부동 소수점 숫자를 단정밀도 부동 소수점 숫자에 할당하면 정밀도가 손실될 수 있습니다. 구문 오류는 아니지만 문제가 발생할 수 있습니다. 이 특정 예에서는 변수를 적절한 데이터 유형으로 캐스팅하여 의도를 보여줄 수 있습니다.
x가 단정밀도 부동 소수점 숫자이고 y가 배정밀도 부동 소수점 숫자인 다음 예를 고려하십시오. y는 할당 중에 float로 명시적으로 캐스팅되어 컴파일러 경고를 제거합니다.
x = (float)y;
논리 오류
로직 오류는 로직에 오류가 있을 때 발생합니다. 예를 들어, 숫자가 4보다 작고 8보다 큰지 테스트할 수 있습니다. 그럴 수는 없지만 구문상 올바르면 프로그램이 성공적으로 컴파일됩니다. 다음 예를 고려하십시오.
if (x < 4 && x > 8)
puts("Will never happen!");
구문이 정확하므로 프로그램이 컴파일되지만 x 값이 동시에 4보다 작거나 8보다 클 수 없기 때문에 puts 문은 인쇄되지 않습니다.
대부분의 논리 오류는 프로그램의 초기 테스트를 통해 발견됩니다. 예상대로 작동하지 않으면 논리적 문장을 더 자세히 검사하고 수정합니다. 이것은 명백한 논리적 오류에만 해당됩니다. 프로그램이 클수록 프로그램을 통과하는 경로가 많을수록 프로그램이 예상대로 작동하는지 확인하기가 더 어려워집니다.
테스트
소프트웨어 개발 과정에서 오류는 개발 중 어느 단계에서나 주입될 수 있습니다. 이는 소프트웨어 개발 초기 단계의 검증 방법이 수동이기 때문입니다. 따라서 코딩 활동 중에 개발된 코드에는 코딩 활동 중에 도입된 오류 외에도 일부 요구 사항 오류 및 설계 오류가 있을 수 있습니다. 테스트하는 동안 테스트할 프로그램은 테스트 케이스 세트로 실행되고 테스트 케이스에 대한 프로그램의 출력은 프로그래밍이 예상대로 수행되는지 판단하기 위해 평가됩니다.
따라서 테스트는 소프트웨어 항목을 분석하여 기존 조건과 필수 조건(즉, 버그)의 차이를 감지하고 소프트웨어 항목의 기능을 평가하는 프로세스입니다. 따라서 테스팅은 오류를 찾을 목적으로 프로그램을 분석하는 과정입니다.
몇 가지 테스트 원칙
- 테스트는 결함의 부재를 보여줄 수 없고 존재만 보여줄 수 있습니다.
- 오류가 일찍 발생할수록 비용이 더 많이 듭니다.
- 오류가 늦게 감지될수록 비용이 더 많이 듭니다.
이제 몇 가지 테스트 기술에 대해 논의해 보겠습니다.
화이트 박스 테스트
화이트 박스 테스트는 프로그램을 통한 모든 경로가 가능한 모든 값으로 테스트되는 기술입니다. 이 접근 방식을 사용하려면 프로그램이 어떻게 작동해야 하는지에 대한 약간의 지식이 필요합니다. 예를 들어, 프로그램이 1에서 50 사이의 정수 값을 수락했다면 화이트 박스 테스트는 50개 값 모두로 프로그램을 테스트하여 각각이 올바른지 확인한 다음 정수가 취할 수 있는 다른 모든 가능한 값을 테스트하고 그 값을 테스트합니다. 그것은 예상대로 행동했습니다. 일반적인 프로그램이 가질 수 있는 데이터 항목의 수를 고려할 때 가능한 순열로 인해 대규모 프로그램의 경우 화이트 박스 테스트가 매우 어렵습니다.
화이트 박스 테스트는 대규모 프로그램의 안전에 중요한 기능에 적용될 수 있으며 나머지 대부분은 아래에서 설명하는 블랙박스 테스트를 사용하여 테스트됩니다. 순열의 수로 인해 화이트 박스 테스트는 일반적으로 테스트 장치를 사용하여 수행됩니다. 여기서 특정 프로그램을 통해 값 범위가 신속하게 프로그램에 공급되어 예상 동작에 대한 예외를 기록합니다. 화이트 박스 테스팅은 때때로 구조적, 투명 또는 공개 상자 테스팅이라고도 합니다.
블랙박스 테스트
블랙박스 테스트는 가능한 모든 값을 테스트하는 대신 선택한 값을 테스트한다는 점을 제외하고는 화이트박스 테스트와 유사합니다. 이 유형의 테스트에서 테스터는 입력과 예상 결과가 무엇인지 알고 있지만 반드시 프로그램이 입력에 도달한 방법은 아닙니다. 블랙박스 테스트를 기능 테스트라고도 합니다.
블랙박스 테스트를 위한 테스트 케이스는 일반적으로 프로그램 사양이 완성되는 즉시 고안됩니다. 테스트 케이스는 등가 클래스를 기반으로 합니다.
등가 클래스
각 입력에 대해 등가 클래스는 유효한 상태와 잘못된 상태를 식별합니다. 동등 클래스를 정의할 때 일반적으로 세 가지 시나리오를 계획해야 합니다.
입력이 범위 또는 특정 값을 지정하는 경우 하나의 유효한 상태와 두 개의 잘못된 상태가 정의됩니다. 예를 들어 숫자가 1에서 20 사이여야 하고 유효한 상태는 1에서 20 사이이며 1보다 작으면 잘못된 상태가 있고 20보다 큰 경우에는 잘못된 상태가 있습니다.
입력이 범위나 특정 값을 제외하면 두 개의 유효한 상태가 있고 하나의 잘못된 상태가 정의됩니다. 예를 들어 숫자가 1과 20 사이가 아니어야 하는 경우 유효한 상태는 1보다 작고 20보다 크며 잘못된 상태는 1과 20 사이입니다.
입력이 부울 값을 지정하는 경우 유효한 상태와 유효하지 않은 상태의 두 가지 상태만 있습니다.
경계 값 분석
경계 값 분석은 입력 경계의 값만 고려합니다. 예를 들어, 숫자가 1과 20 사이인 경우 테스트 케이스는 1, 20, 0, 21일 수 있습니다. 프로그램이 이러한 값으로 예상대로 작동하면 다른 값도 마찬가지입니다. 예상대로 작동합니다.
다음 표는 식별할 수 있는 일반적인 경계에 대한 개요를 제공합니다.
| Testing Ranges |
| Input type |
Test Values |
| Range |
- x[lower_bound]-1
- x[lower_bound]
- x[upper_bound]
- x[upper_bound]+1
|
| Boolean |
|
테스트 계획 수립
등가 등급을 식별하고 각 등급에 대해 경계를 식별합니다. 클래스의 경계를 식별했으면 경계에 유효한 값과 유효하지 않은 값 목록과 예상되는 동작을 작성하십시오. 그런 다음 테스터는 경계 값으로 프로그램을 실행하고 경계 값이 필요한 결과에 대해 테스트되었을 때 무슨 일이 일어났는지 나타낼 수 있습니다.
다음은 허용되는 값이 10에서 110 사이인 경우 입력되는 연령을 확인하는 데 사용되는 일반적인 테스트 계획일 수 있습니다.
| Equivalence Class |
| Valid |
Invalid |
| Between 10 and 110 |
> 110 |
|
< 10 |
등가 클래스를 정의했으므로 이제 연령에 대한 테스트 계획을 고안할 수 있습니다.
| Test Plan |
| Value |
State |
Expected Result |
Actual Result |
| 10 |
Valid |
Continue execution to get name |
|
| 110 |
Valid |
Continue execution to get name |
|
| 9 |
Invalid |
Ask for age again |
|
| 111 |
Invalid |
Ask for age again |
|
"실제 결과" 열은 테스트할 때 완료되므로 공백으로 둡니다. 결과가 예상대로이면 열이 선택됩니다. 그렇지 않은 경우 발생한 일을 나타내는 주석을 입력해야 합니다.

 Home
Home