章 – 5
Cプログラミングの紹介
序章
「C」は、今日のコンピュータの世界で最も人気のあるコンピュータ言語の1つです。 「C」プログラミング言語は、1972年にThe Bell ResearchLabsのBrianKernighanとDennisRitchieによって設計および開発されました。
「C」は、プログラマーがマシンのほとんどすべての内部(レジスタ、I / Oスロット、絶対アドレス)にアクセスできるようにするために特別に作成された言語です。同時に、「C」は、非常に複雑なマルチプログラマープロジェクトを組織化されたタイムリーな方法で構築できるようにするために必要なだけのデータ処理とプログラムされたテキストのモジュール化を可能にします。
この言語は元々UNIXでの実行を目的としていましたが、IBMPCおよび互換機のMS-DOSオペレーティングシステムで実行することに大きな関心が寄せられています。表現が単純で、コードがコンパクトで、適用範囲が広いため、この環境に最適な言語です。
また、Cコンパイラの記述は単純で簡単なため、通常、マイクロコンピュータ、ミニコンピュータ、メインフレームなど、新しいコンピュータで利用できる最初の高級言語です。
データ回復プログラミングでCを使用する理由
今日のコンピュータプログラミングの世界では、多くの高級言語が利用可能です。これらの言語は、ほとんどのプログラミングタスクに適した多くの機能を備えています。それでも、Cがデータ回復、システムプログラミング、デバイスプログラミング、またはハードウェアプログラミングのプログラミングを喜んで行うプログラマーの最初の選択肢である理由はいくつかあります。
- Cは、プロのプログラマーが好む人気のある言語です。その結果、さまざまなCコンパイラと便利なアクセサリを利用できます。
- Cは移植可能な言語です. あるコンピュータシステム用に作成されたCプログラムは、ほとんどまたはまったく変更を加えることなく、コンパイルして別のシステムで実行できます。移植性は、Cコンパイラの一連のルールであるCのANSI規格によって強化されています。
- Cを使用すると、プログラミングでモジュールを幅広く使用できます。 Cコードは、関数と呼ばれるルーチンで記述できます。これらの関数は、他のアプリケーションやプログラムで再利用できます。以前に別のアプリケーションプログラミングで開発したものと同じモジュールを作成するために、新しいアプリケーションのプログラミングで余分な努力をする必要はありません。
この機能は、新しいプログラムで変更や小さな変更を加えることなく使用できます。データ回復プログラミングの場合、異なるプログラムの異なるアプリケーションで同じ機能を数回実行する必要があるときに、この品質が非常に役立ちます。
- Cは強力で柔軟な言語です。 これが、オペレーティングシステム、ワードプロセッサ、グラフィックス、スプレッドシート、さらには他の言語のコンパイラなど、さまざまなプロジェクトでCが使用される理由です。
- Cは数語の言語であり、キーワードと呼ばれるほんの一握りの用語しか含まれていません。これらの用語は、言語の機能を構築するための基礎として機能します。これらのキーワードは予約語とも呼ばれ、より強力になり、プログラミングの広い領域を提供し、プログラマーにCであらゆるタイプのプログラミングを行うように感じさせます。
あなたがCで何も知らないと仮定させてください
あなたはCプログラミングについて何も知らず、プログラミングについても何も知らないと思います。 Cの最も基本的な概念から始めて、ポインター、構造、動的割り当ての通常は威圧的な概念を含む、高レベルのCプログラミングに進みます。
これらの概念を完全に理解するには、理解するのが特に簡単ではないため、かなりの時間と作業が必要になりますが、非常に強力なツールです。
Cでのプログラミングは、アセンブリ言語を使用する必要があるかもしれないが、プログラムの作成と保守が簡単であるようにしたい分野では、非常に大きな資産です。このような場合、Cのコーディングで節約できる時間は膨大なものになる可能性があります。
プログラムをある実装から別の実装に転送する場合、C言語は優れた記録を持っていますが、別のコンパイラを使おうとすると、コンパイラに違いがあります。
MS-DOSを使用するときにDOSBIOSの呼び出しなどの非標準の拡張機能を使用すると、ほとんどの違いが明らかになりますが、プログラミング構造を慎重に選択することで、これらの違いを最小限に抑えることができます。
Cプログラミング言語が幅広いコンピューターで利用できる非常に人気のある言語になりつつあることが明らかになったとき、関係者のグループが集まり、Cプログラミング言語の使用に関する一連の標準的なルールを提案しました。
このグループは、ソフトウェア業界のすべてのセクターを代表し、多くの会議と多くの予備草案を経て、最終的にC言語の許容可能な標準を作成しました。 これは、米国規格協会(ANSI)および国際標準化機構(ISO)によって承認されています。.
グループやユーザーに強制されることはありませんが、広く受け入れられているため、プログラマーの作成者が標準への準拠を拒否することは経済的な自殺になります。
この本で書かれているプログラムは、主にIBM-PCまたは互換性のあるコンピューターで使用するためのものですが、ANSI規格に非常に厳密に準拠しているため、どのANSI規格コンパイラーでも使用できます。
始めましょう
任意の言語で何かを実行してプログラミングを開始する前に、識別子に名前を付ける方法を知っている必要があります。識別子は、変数、関数、データ定義などに使用されます。Cプログラミング言語では、識別子は英数字の組み合わせであり、最初は英数字または下線で、残りは英数字の任意の文字です。アルファベット、任意の数字、または下線。
識別子に名前を付けるときは、2つのルールに留意する必要があります。
- 英字の場合は重要です。 Cは大文字と小文字を区別する言語です。つまり、リカバリはリカバリとは異なり、rEcOveRYは前述の両方とは異なります。
- ANSI-C規格によれば、少なくとも31文字の重要な文字を使用でき、準拠するANSI-Cコンパイラによって重要であると見なされます。 31を超える文字が使用されている場合、31を超えるすべての文字は、特定のコンパイラーによって無視される可能性があります。
キーワード
Cではキーワードとして32語が定義されています。これらには事前定義された用途があり、Cプログラムで他の目的に使用することはできません。これらは、プログラムをコンパイルするための補助としてコンパイラーによって使用されます。それらは常に小文字で書かれています。完全なリストは次のとおりです。
| auto |
break |
case |
char |
| const |
continue |
default |
do |
| double |
else |
enum |
extern |
| float |
for |
goto |
if |
| int |
long |
register |
return |
| short |
signed |
sizeof |
static |
| struct |
switch |
typedef |
union |
| unsigned |
void |
volatile |
while |
ここにCの魔法が見えます。 32 キーワード さまざまなアプリケーションで幅広く使用できます。すべてのコンピュータプログラムには、考慮すべき2つのエンティティ、データとプログラムがあります。それらは互いに非常に依存しており、両方を注意深く計画することで、よく計画され、よく書かれたプログラムにつながります。
簡単なCプログラムから始めましょう。
/* First Program to learn C */
#include <stdio.h>
void main()
{
printf("This is a C program\n"); // printing a message
}
プログラムは非常にシンプルですが、いくつかの点に注意する必要があります。上記のプログラムを調べてみましょう。 / *および* /内にあるものはすべてコメントと見なされ、コンパイラーによって無視されます。他のコメント内にコメントを含めないでください。そのため、次のようなことは許可されていません。
/ *これは/ *コメントです* /コメント内ですが間違っています* /
行内で機能するドキュメントの方法もあります。 //を使用すると、その行に小さなドキュメントを追加できます。
すべてのCプログラムには、mainと呼ばれる関数が含まれています。これがプログラムの開始点です。すべての関数は値を返す必要があります。このプログラムでは、関数mainは戻り値を返さないため、voidmainと記述しました。このプログラムは次のように書くこともできます。
/ * Cを学ぶ最初のプログラム* /
#include <stdio.h>
main()
{
printf("This is a C program\n"); // printing a message
return 0;
}
両方のプログラムは同じであり、同じタスクを実行します。両方のプログラムの結果は、画面に次の出力を出力します。
これはCプログラムです
#include<stdio.h> プログラムがコンピュータの画面、キーボード、ファイルシステムと対話できるようにします。ほとんどすべてのCプログラムの最初にあります。
主要() 関数の開始を宣言し、2つの中括弧は関数の開始と終了を示します。 Cの中括弧は、関数またはループの本体のようにステートメントをグループ化するために使用されます。このようなグループ化は、複合ステートメントまたはブロックとして知られています。
printf(&quot;これはCプログラムです\ n&quot;); 画面に単語を印刷します。印刷するテキストは二重引用符で囲みます。テキストの最後にある\ nは、出力の一部として改行を出力するようにプログラムに指示します。 printf()関数は、出力のモニター表示に使用されます。
ほとんどのCプログラムは小文字です。通常、後で説明するプリプロセッサ定義で使用される大文字、または文字列の一部として引用符で囲まれています。
プログラムのコンパイル
プログラムの名前をCPROG.Cとします。 Cプログラムを入力してコンパイルするには、次の手順に従います。
- Cプログラムのアクティブディレクトリを作成し、エディタを起動します。これには任意のテキストエディタを使用できますが、BorlandのTurbo C ++などのほとんどのCコンパイラには、プログラムを1つの便利な設定で入力、コンパイル、およびリンクできる統合開発環境(IDE)があります。
- ソースコードを記述して保存します。ファイルにCPROG.Cという名前を付ける必要があります。
- CPROG.Cをコンパイルしてリンクします。コンパイラのマニュアルで指定されている適切なコマンドを実行します。エラーや警告がなかったことを示すメッセージが表示されます。
- コンパイラメッセージを確認してください。エラーや警告が表示されない場合は、すべて問題ないはずです。プログラムの入力中にエラーが発生した場合、コンパイラはそれをキャッチしてエラーメッセージを表示します。エラーメッセージに表示されているエラーを修正します。
- これで、最初のCプログラムがコンパイルされ、実行できるようになります。 CPROGという名前のすべてのファイルのディレクトリリストを表示すると、次のように説明されている異なる拡張子を持つ4つのファイルが表示されます。
- CPROG.C、ソースコードファイル
- CPROG.BAK、エディターで作成したソースファイルのバックアップファイル
- CPROG.OBJには、CPROG.Cのオブジェクトコードが含まれています
- CPROG.C、CPROG.Cをコンパイルおよびリンクしたときに作成された実行可能プログラム
- CPROG.EXEを実行または実行するには、cprogと入力するだけです。 「これはCプログラムです」というメッセージが画面に表示されます。
次に、次のプログラムを調べてみましょう。
/* First Program to learn C */ // 1
// 2
#include <stdio.h> // 3
// 4
main() // 5
{
// 6
printf("This is a C program\n"); // 7
// 8
return 0; // 9
} // 10
このプログラムをコンパイルすると、コンパイラは次のようなメッセージを表示します。
cprog.c(8):エラー: `; '期待される
このエラーメッセージを部分的に分割しましょう。 cprog.cは、エラーが見つかったファイルの名前です。 (8)は、エラーが検出された行番号です。エラー: `; '予想されるのはエラーの説明です。
このメッセージは非常に有益であり、CPROG.Cの8行目で、コンパイラーがセミコロンを検出することを期待していましたが、検出しなかったことを示しています。ただし、実際には7行目からセミコロンが省略されているため、不一致があります。
実際、7行目からセミコロンが省略されているのに、コンパイラーが8行目でエラーを報告する理由。答えは、Cが行間の区切りなどを気にしないという事実にあります。 printf()ステートメントの後にあるセミコロンは次の行に配置されている可能性がありますが、そうすることは実際には悪いプログラミングになります。
8行目で次のコマンド(return)に遭遇した後でのみ、コンパイラーはセミコロンが欠落していることを確認します。したがって、コンパイラはエラーが8行目にあることを報告します。
さまざまなタイプのエラーの可能性がいくつかあります。エラーメッセージのリンクについて説明しましょう。リンカーエラーは比較的まれであり、通常、Cライブラリ関数の名前のつづりを間違えたことが原因です。この場合、エラー:未定義の記号:エラーメッセージが表示され、その後に名前のつづりが間違っています。スペルを修正すると、問題は解決するはずです。
番号の印刷
次の例を見てみましょう。
//数字を印刷する方法//
#include<stdio.h>
void main()
{
int num = 10;
printf(“ The Number Is %d”, num);
}
プログラムの出力は、次のように画面に表示されます。
数は10です
%記号は、さまざまなタイプの変数の出力を示すために使用されます。 %記号に続く文字はdであり、10進値を取得して出力するように出力ルーチンに通知します。
変数の使用
Cでは、変数を使用する前に宣言する必要があります。変数はコードの任意のブロックの先頭で宣言できますが、ほとんどは各関数の先頭で見つかります。ほとんどのローカル変数は、関数が呼び出されたときに作成され、その関数から戻ったときに破棄されます。
Cプログラムで変数を使用するには、Cで変数に名前を付けるときに、次の規則を知っている必要があります。
- 名前には、文字、数字、および下線文字(_)を含めることができます。
- 名前の最初の文字は文字でなければなりません。アンダースコアも合法的な最初の文字ですが、その使用はお勧めしません。
- Cでは大文字と小文字が区別されるため、変数名numはNumとは異なります。
- Cキーワードを変数名として使用することはできません。キーワードは、C言語の一部である単語です。
次のリストには、有効なC変数名と不正なC変数名の例がいくつか含まれています。
| Variable Name |
Legal or Not |
| Num |
Legal |
| Ttpt2_t2p |
Legal |
| Tt pt |
Illegal: Space is not allowed |
| _1990_tax |
Legal but not advised |
| Jack_phone# |
Illegal: Contains the illegal character # |
| Case |
Illegal: Is a C keyword |
| 1book |
Illegal: First character is a digit |
目立つ最初の新しいものは、main()の本体の最初の行です。
あなたは眠る= 10;
この行は、int型の 'num'という名前の変数を定義し、値10で初期化します。これは次のように記述されている場合もあります。
int num; /* define uninitialized variable 'num' */
/* and after all variable definitions: */
num = 10; /* assigns value 10 to variable 'num' */
変数は、ブロックの先頭(中括弧{と}の間)で定義できます。通常、これは関数本体の先頭にありますが、別のタイプのブロックの先頭にある場合もあります。
ブロックの先頭で定義される変数は、デフォルトで「auto」ステータスになります。これは、それらがブロックの実行中にのみ存在することを意味します。関数の実行が開始されると、変数は作成されますが、その内容は未定義になります。関数が戻ると、変数は破棄されます。定義は次のように書くこともできます。
self int num = 10;
autoキーワードがある場合とない場合の定義は完全に同等であるため、autoキーワードは明らかにかなり冗長です。
ただし、これが希望どおりでない場合もあります。関数が呼び出された回数をカウントし続ける必要があるとします。関数が戻るたびに変数が破棄される場合、これは不可能です。
したがって、静的期間と呼ばれる変数を指定することができます。これは、プログラムの実行全体を通じてそのままの状態を維持することを意味します。例えば:
static int num = 10;
これにより、プログラム実行の開始時に変数numが10に初期化されます。それ以降、値は変更されません。関数が複数回呼び出された場合、変数は再初期化されません。
変数に1つの関数からのみアクセスできるだけでは不十分な場合や、パラメーターを介して値を必要とする他のすべての関数に値を渡すのが不便な場合があります。
ただし、ソースファイル全体のすべての関数から変数にアクセスする必要がある場合は、staticキーワードを使用してこれを行うこともできますが、定義をすべての関数の外に配置します。例えば:
#include <stdio.h>
static int num = 10; /* will be accessible from entire source file */
int main(void)
{
printf("The Number Is: %d\n", num);
return 0;
}
また、複数のソースファイルで構成されるプログラム全体から変数にアクセスできる必要がある場合もあります。これはグローバル変数と呼ばれ、不要な場合は避ける必要があります。
これは、静的キーワードを使用せずに、すべての関数の外に定義を配置することによっても行われます。
#include <stdio.h>
int num = 10; /* will be accessible from entire program! */
int main(void)
{
printf("The Number Is: %d\n", num);
return 0;
}
他のモジュールのグローバル変数にアクセスするために使用されるexternキーワードもあります。変数定義に追加できる修飾子もいくつかあります。それらの中で最も重要なのはconstです。 constとして定義されている変数は変更できません。
あまり一般的に使用されない修飾子がさらに2つあります。 volatileおよびregister修飾子。 volatile修飾子では、コンパイラーが変数を読み取るたびに実際に変数にアクセスする必要があります。レジスタなどに入れても変数が最適化されない場合があります。これは主にマルチスレッドや割り込み処理などに使用されます。
レジスタ修飾子は、コンパイラに変数をレジスタに最適化するように要求します。これは自動変数でのみ可能であり、多くの場合、コンパイラーはレジスターに最適化する変数をより適切に選択できるため、このキーワードは廃止されています。可変レジスタを作成することの唯一の直接的な結果は、そのアドレスを取得できないことです。
次のページに示す変数の表では、5種類のストレージクラスのストレージクラスについて説明しています。
この表では、キーワードexternが2行に配置されていることがわかります。 externキーワードは、他の場所で定義されている静的外部変数を宣言する関数で使用されます。
数値変数タイプ
数値が異なればメモリストレージ要件も異なるため、Cはいくつかの異なるタイプの数値変数を提供します。これらの数値タイプは、特定の数学演算を簡単に実行できる点で異なります。
整数が小さいと、保存に必要なメモリが少なくなり、コンピュータはそのような数値を使用して数学演算を非常に高速に実行できます。大きな整数と浮動小数点値は、数学演算のためにより多くのストレージスペースとより多くの時間を必要とします。適切な変数タイプを使用することにより、プログラムが可能な限り効率的に実行されるようにします。
Cの数値変数は、次の2つの主要なカテゴリに分類されます。
これらの各カテゴリには、2つ以上の特定の変数タイプがあります。次に示す表は、各タイプの単一の変数を保持するために必要なメモリの量をバイト単位で示しています。
タイプcharは、signedcharまたはunsignedcharと同等ですが、常にこれらのいずれかとは別のタイプです。
Cでは、文字またはそれに対応する数値を変数に格納することに違いはないため、文字とその数値の間、またはその逆に変換する関数も必要ありません。他の整数型の場合、signedまたはunsignedを省略すると、デフォルトが符号付きになります。たとえば、 intとsignedintは同等です。
タイプintは、タイプshort以上であり、タイプlong以下である必要があります。それほど大きくない値を格納する必要があるだけの場合は、int型を使用することをお勧めします。これは通常、プロセッサが最も簡単に処理できるサイズであり、したがって最も高速です。
いくつかのコンパイラでは、doubleとlongdoubleは同等です。これは、ほとんどの標準的な数学関数がdouble型で機能するという事実と相まって、小数を処理する必要がある場合は常にdouble型を使用するのに十分な理由です。
次の表は、変数の型をわかりやすく説明するためのものです。

一般的に使用される特殊用途のタイプ:
| Variable Type |
Description |
| size_t |
unsigned type used for storing the sizes of objects in bytes |
| time_t |
used to store results of the time() function |
| clock_t |
used to store results of the clock() function |
| FILE |
used for accessing a stream (usually a file or device) |
| ptrdiff_t |
signed type of the difference between 2 pointers |
| div_t |
used to store results of the div() function |
| ldiv_t |
used to store results of ldiv() function |
| fpos_t |
used to hold file position information |
| va_list |
used in variable argument handling |
| wchar_t |
wide character type (used for extended character sets) |
| sig_atomic_t |
used in signal handlers |
| Jmp_buf |
used for non-local jumps |
これらの変数をよりよく理解するために、例を見てみましょう。
/ * C変数の範囲とサイズをバイト単位で通知するプログラム* /
#include <stdio.h>
int main()
{
int a; /* simple integer type */
long int b; /* long integer type */
short int c; /* short integer type */
unsigned int d; /* unsigned integer type */
char e; /* character type */
float f; /* floating point type */
double g; /* double precision floating point */
a = 1023;
b = 2222;
c = 123;
d = 1234;
e = 'X';
f = 3.14159;
g = 3.1415926535898;
printf( "\nA char is %d bytes", sizeof( char ));
printf( "\nAn int is %d bytes", sizeof( int ));
printf( "\nA short is %d bytes", sizeof( short ));
printf( "\nA long is %d bytes", sizeof( long ));
printf( "\nAn unsigned char is %d bytes",
sizeof( unsigned char ));
printf( "\nAn unsigned int is %d bytes",
sizeof( unsigned int ));
printf( "\nAn unsigned short is %d bytes",
sizeof( unsigned short ));
printf( "\nAn unsigned long is %d bytes",
sizeof( unsigned long ));
printf( "\nA float is %d bytes", sizeof( float ));
printf( "\nA double is %d bytes\n", sizeof( double ));
printf("a = %d\n", a); /* decimal output */
printf("a = %o\n", a); /* octal output */
printf("a = %x\n", a); /* hexadecimal output */
printf("b = %ld\n", b); /* decimal long output */
printf("c = %d\n", c); /* decimal short output */
printf("d = %u\n", d); /* unsigned output */
printf("e = %c\n", e); /* character output */
printf("f = %f\n", f); /* floating output */
printf("g = %f\n", g); /* double float output */
printf("\n");
printf("a = %d\n", a); /* simple int output */
printf("a = %7d\n", a); /* use a field width of 7 */
printf("a = %-7d\n", a); /* left justify in
field of 7 */
c = 5;
d = 8;
printf("a = %*d\n", c, a); /* use a field width of 5*/
printf("a = %*d\n", d, a); /* use a field width of 8 */
printf("\n");
printf("f = %f\n", f); /* simple float output */
printf("f = %12f\n", f); /* use field width of 12 */
printf("f = %12.3f\n", f); /* use 3 decimal places */
printf("f = %12.5f\n", f); /* use 5 decimal places */
printf("f = %-12.5f\n", f); /* left justify in field */
return 0;
}
実行後のプログラムの結果は次のように表示されます。
A char is 1 bytes
An int is 2 bytes
A short is 2 bytes
A long is 4 bytes
An unsigned char is 1 bytes
An unsigned int is 2 bytes
An unsigned short is 2 bytes
An unsigned long is 4 bytes
A float is 4 bytes
A double is 8 bytes
a = 1023
a = 1777
a = 3ff
b = 2222
c = 123
d = 1234
e = X
f = 3.141590
g = 3.141593
a = 1023
a = 1023
a = 1023
a = 1023
a = 1023
f = 3.141590
f = 3.141590
f = 3.142
f = 3.14159
f = 3.14159 |
Cプログラムで変数を使用する前に、宣言する必要があります。変数宣言は、コンパイラに変数の名前とタイプを通知し、オプションで変数を特定の値に初期化します。
プログラムが宣言されていない変数を使用しようとすると、コンパイラはエラーメッセージを生成します。変数宣言の形式は次のとおりです。
typename varname;
typenameは変数タイプを指定し、キーワードの1つである必要があります。 varnameは変数名です。変数名をコンマで区切ることにより、同じタイプの複数の変数を1行で宣言できます。
int count, number, start; /* three integer variables */
float percent, total; /* two float variables */
typedefキーワード
typedefキーワードは、既存のデータ型の新しい名前を作成するために使用されます。実際、typedefは同義語を作成します。たとえば、ステートメント
typedef int integer;
ここでは、typedefがintの同義語として整数を作成していることがわかります。次に、次の例のように、整数を使用してint型の変数を定義できます。
整数カウント;
したがって、typedefは新しいデータ型を作成せず、事前定義されたデータ型に異なる名前を使用できるようにするだけです。
数値変数の初期化
変数が宣言されると、コンパイラーは変数用のストレージスペースを確保するように指示されます。ただし、そのスペースに格納されている値、つまり変数の値は定義されていません。ゼロの場合もあれば、ランダムな「ゴミ」の場合もあります。価値。変数を使用する前に、常に既知の値に初期化する必要があります。この例を見てみましょう:
int count; /* Set aside storage space for count */
count = 0; /* Store 0 in count */
このステートメントは、Cの代入演算子である等号(=)を使用します。宣言時に変数を初期化することもできます。これを行うには、宣言ステートメントの変数名の後に等号と目的の初期値を付けます。
int count = 0;
double rate = 0.01, complexity = 28.5;
許容範囲外の値で変数を初期化しないように注意してください。範囲外の初期化の2つの例を次に示します。
int amount = 100000;
unsigned int length = -2500;
Cコンパイラはそのようなエラーをキャッチしません。プログラムがコンパイルおよびリンクされる場合がありますが、プログラムの実行時に予期しない結果が生じる可能性があります。
次の例を使用して、ディスク内のセクターの総数を計算してみましょう。
//ディスク内のセクターを計算するためのモデルプログラム//
#include<stdio.h>
#define SECTOR_PER_SIDE 63
#define SIDE_PER_CYLINDER 254
void main()
{
int cylinder=0;
clrscr();
printf("Enter The No. of Cylinders in the Disk \n\n\t");
scanf("%d",&cylinder); // Get the value from the user //
printf("\n\n\t Total Number of Sectors in the disk = %ld", (long)SECTOR_PER_SIDE*SIDE_PER_CYLINDER* cylinder);
getch();
}
プログラムの出力は次のとおりです。
Enter The No. of Cylinders in the Disk
1024
Total Number of Sectors in the disk = 16386048
この例では、学ぶべき3つの新しいことがわかります。 #defineは、プログラムでシンボリック定数を使用するために使用されます。場合によっては、小さなシンボルで長い単語を定義することで時間を節約するために使用されます。
ここでは、プログラムを理解しやすくするために、サイドあたりのセクター数を63としてSECTOR_PER_SIDEと定義しました。同じケースが#defineSIDE_PER_CYLINDER 254にも当てはまります。scanf()はユーザーからの入力を取得するために使用されます。
ここでは、ユーザーからの入力としてシリンダーの数を取得しています。 *は、例に示すように2つ以上の値を乗算するために使用されます。
getch()関数は、基本的にキーボードから1文字の入力を取得します。 getch();と入力します。ここでは、キーボードからキーが押されるまで画面を停止します。
演算子
演算子は、1つ以上のオペランドに対して何らかの操作またはアクションを実行するようにCに指示する記号です。オペランドは、演算子が作用するものです。 Cでは、すべてのオペランドは式です。 C演算子は、次の4つのカテゴリに分類されます。
代入演算子
代入演算子は等号(=)です。プログラミングでの等号の使用は、通常の数学的代数関係での使用とは異なります。あなたが書くなら
x = y;
Cプログラムでは、「xがyに等しい」という意味ではありません。代わりに、「yの値をxに割り当てる」ことを意味します。 C代入ステートメントでは、右側は任意の式にすることができ、左側は変数名でなければなりません。したがって、形式は次のようになります。
変数=式;
実行中に、式が評価され、結果の値が変数に割り当てられます。
数学演算子
Cの数学演算子は、加算や減算などの数学演算を実行します。 Cには、2つの単項数学演算子と5つの2進数学演算子があります。単項数学演算子は、単一のオペランドを取るため、そのように名付けられています。 Cには2つの単項数学演算子があります。
インクリメント演算子とデクリメント演算子は、定数ではなく変数でのみ使用できます。実行される操作は、オペランドに1を加算するか、オペランドから1を減算することです。言い換えれば、ステートメント++ x;および--y;これらのステートメントと同等です。
x = x + 1;
y = y - 1;
2進数学演算子は、2つのオペランドを取ります。電卓で見られる一般的な数学演算(+、-、*、/)を含む最初の4つの二項演算子は、おなじみです。 5番目の演算子Modulusは、最初のオペランドを2番目のオペランドで割ったときに余りを返します。たとえば、11モジュラス4は3に等しくなります(11は4で除算され、2回、残り3になります)。
関係演算子
Cの関係演算子は、式を比較するために使用されます。関係演算子を含む式は、true(1)またはfalse(0)のいずれかに評価されます。 Cには6つの関係演算子があります。
論理演算子
Cの論理演算子を使用すると、2つ以上の関係式を1つの式に結合して、trueまたはfalseのいずれかに評価できます。論理演算子は、オペランドのtrueまたはfalseの値に応じて、trueまたはfalseのいずれかに評価されます。
xが整数変数の場合、論理演算子を使用した式は次のように記述できます。
(x > 1) && (x < 5)
(x >= 2) && (x <= 4)
| Operator |
Symbol |
Description |
Example |
| Assignment operators |
| equal |
= |
assign the value of y to x |
x = y |
| Mathematical operators |
| Increment |
++ |
Increments the operand by one |
++x, x++ |
| Decrement |
-- |
Decrements the operand by one |
--x, x-- |
| Addition |
+ |
Adds two operands |
x + y |
| Subtraction |
- |
Subtracts the second operand from the first |
x - y |
| Multiplication |
* |
Multiplies two operands |
x * y |
| Division |
/ |
Divides the first operand by the second operand |
x / y |
| Modulus |
% |
Gives the remainder when the first operand is divided by the second operand |
x % y |
| Relational operators |
| Equal |
= = |
Equality |
x = = y |
| Greater than |
> |
Greater than |
x > y |
| Less than |
< |
Less than |
x < y |
| Greater than or equal to |
>= |
Greater than or equal to |
x >= y |
| Less than or equal to |
<= |
Less than or equal to |
x <= y |
| Not equal |
!= |
Not equal to |
x != y |
| Logical operators |
| AND |
&& |
True (1) only if both exp1 and exp2 are true; false (0) otherwise |
exp1 && exp2 |
| OR |
|| |
True (1) if either exp1 or exp2 is true; false (0) only if both are false |
exp1 || exp2 |
| NOT |
! |
False (0) if exp1 is true; true (1) if exp1 is false |
!exp1 |
論理式について覚えておくべきこと
| x * = y |
is same as |
x = x * y |
| y - = z + 1 |
is same as |
y = y - z + 1 |
| a / = b |
is same as |
a = a / b |
| x + = y / 8 |
is same as |
x = x + y / 8 |
| y % = 3 |
is same as |
y = y % 3 |
コンマ演算子
コンマは、変数宣言や関数の引数などを区切るために、Cで単純な句読点として頻繁に使用されます。特定の状況では、コンマは演算子として機能します。
2つのサブ式をコンマで区切ることにより、式を作成できます。結果は次のとおりです。
- 両方の式が評価され、左側の式が最初に評価されます。
- 式全体が正しい式の値に評価されます。
例えば、 次のステートメントは、bの値をxに割り当て、次にaをインクリメントし、次にbをインクリメントします。
x =(a ++、b ++);
C演算子の優先順位(C演算子の要約)
| Rank and Associativity |
Operators |
| 1(left to right) |
() [] -> . |
| 2(right to left) |
! ~ ++ -- * (indirection) & (address-of) (type)
sizeof + (unary) - (unary) |
| 3(left to right) |
* (multiplication) / % |
| 4(left to right) |
+ - |
| 5(left to right) |
<< >> |
| 6(left to right) |
< <= > >= |
| 7(left to right) |
= = != |
| 8(left to right) |
& (bitwise AND) |
| 9(left to right) |
^ |
| 10(left to right) |
| |
| 11(left to right) |
&& |
| 12(left to right) |
|| |
| 13(right to left) |
?: |
| 14(right to left) |
= += -= *= /= %= &= ^= |= <<= >>= |
| 15(left to right) |
, |
| () is the function operator; [] is the array operator. |
|
演算子の使用例を見てみましょう。
/ *演算子の使用* /
int main()
{
int x = 0, y = 2, z = 1025;
float a = 0.0, b = 3.14159, c = -37.234;
/* incrementing */
x = x + 1; /* This increments x */
x++; /* This increments x */
++x; /* This increments x */
z = y++; /* z = 2, y = 3 */
z = ++y; /* z = 4, y = 4 */
/* decrementing */
y = y - 1; /* This decrements y */
y--; /* This decrements y */
--y; /* This decrements y */
y = 3;
z = y--; /* z = 3, y = 2 */
z = --y; /* z = 1, y = 1 */
/* arithmetic op */
a = a + 12; /* This adds 12 to a */
a += 12; /* This adds 12 more to a */
a *= 3.2; /* This multiplies a by 3.2 */
a -= b; /* This subtracts b from a */
a /= 10.0; /* This divides a by 10.0 */
/* conditional expression */
a = (b >= 3.0 ? 2.0 : 10.5 ); /* This expression */
if (b >= 3.0) /* And this expression */
a = 2.0; /* are identical, both */
else /* will cause the same */
a = 10.5; /* result. */
c = (a > b ? a : b); /* c will have the max of a or b */
c = (a > b ? b : a); /* c will have the min of a or b */
printf("x=%d, y=%d, z= %d\n", x, y, z);
printf("a=%f, b=%f, c= %f", a, b, c);
return 0;
}
このプログラムの結果は、画面に次のように表示されます。
x=3, y=1, z=1
a=2.000000, b=3.141590, c=2.000000
printf()とScanf()についての詳細
次の2つのprintfステートメントを検討してください
printf(“\t %d\n”, num);
printf(“%5.2f”, fract);
最初のprintfステートメント\ tで、画面上のタブの移動を要求します。引数%dは、numの値を10進整数として出力する必要があることをコンパイラーに指示します。 \ nにより、新しい出力が新しい行から開始されます。
2番目のprintfステートメントで%5.2fは、出力が浮動小数点である必要があることをコンパイラーに通知します。小数点以下2桁で、すべて5桁です。次の表に、円記号の詳細を示します。
| Constant |
Meaning |
| ‘\a’ |
Audible alert (bell) |
| ‘\b’ |
Backspace |
| ‘\f’ |
Form feed |
| ‘\n’ |
New line |
| ‘\r’ |
Carriage return |
| ‘\t’ |
Horizontal tab |
| ‘\v’ |
Vertical tab |
| ‘\’’ |
Single quote |
| ‘\”’ |
Double quote |
| ‘\?’ |
Question mark |
| ‘\\’ |
Backslash |
| ‘\0’ |
Null |
次のscanfステートメントを考えてみましょう
scanf(“%d”、&amp; num);
キーボードからのデータはscanf関数によって受信されます。上記の形式では、&amp;各変数名の前の(アンパサンド)記号は、変数名のアドレスを指定する演算子です。
これにより、実行が停止し、変数numの値が入力されるのを待ちます。整数値を入力してリターンキーを押すと、コンピューターは次のステートメントに進みます。 scanfおよびprintfフォーマットコードを次の表に示します。
| Code |
Reads... |
| %c |
Single character |
| %d |
Decimal integer |
| %e |
Floating point value |
| %f |
Floating point value |
| %g |
Floating point value |
| %h |
Short integer |
| %i |
Decimal, hexadecimal or octal integer |
| %o |
Octal integer |
| %s |
String |
| %u |
Unsigned decimal integer |
| %x |
Hexadecimal integer |
制御ステートメント
プログラムは、通常は順番に実行されるいくつかのステートメントで構成されます。ステートメントが実行される順序を制御できれば、プログラムははるかに強力になります。
ステートメントは、次の3つの一般的なタイプに分類されます。
- 割り当て。値(通常は計算結果)が変数に格納されます。
- 入力/出力、データの読み込みまたは印刷。
- 制御、プログラムは次に何をすべきかを決定します。
このセクションでは、Cでの制御ステートメントの使用について説明します。これらを使用して強力なプログラムを作成する方法を示します。
- プログラムの重要なセクションを繰り返します。
- プログラムのオプションセクションからの選択。
ifelseステートメント
これは、特別な時点で何かを行うかどうかを決定するため、または2つのアクションコースの間で決定するために使用されます。
次のテストは、学生が45の合格点で試験に合格したかどうかを判断します
if (result >= 45)
printf("Pass\n");
else
printf("Fail\n");
It is possible to use the if part without the else.
if (temperature < 0)
print("Frozen\n");
各バージョンは、ifに続く括弧で囲まれたステートメントのテストで構成されています。テストが真の場合、次のステートメントに従います。 falseの場合、elseに続くステートメントが存在する場合はそれに従います。この後、プログラムの残りの部分は通常どおり続行されます。
ifまたはelseの後に複数のステートメントを含める場合は、中括弧で囲んでグループ化する必要があります。このようなグループ化は、複合ステートメントまたはブロックと呼ばれます。
if (result >= 45)
{ printf("Passed\n");
printf("Congratulations\n");
}
else
{ printf("Failed\n");
printf("Better Luck Next Time\n");
}
いくつかの条件に基づいて、多方向の決定をしたい場合があります。これを行う最も一般的な方法は、ifステートメントでelseifバリアントを使用することです。
これは、いくつかの比較をカスケードすることによって機能します。これらのいずれかが真の結果をもたらすとすぐに、次のステートメントまたはブロックが実行され、それ以上の比較は実行されません。次の例では、試験結果に応じて成績を授与しています。
if (result <=100 && result >= 75)
printf("Passed: Grade A\n");
else if (result >= 60)
printf("Passed: Grade B\n");
else if (result >= 45)
printf("Passed: Grade C\n");
else
printf("Failed\n");
この例では、すべての比較でresultという単一の変数がテストされます。その他の場合、各テストには、異なる変数またはテストの組み合わせが含まれる場合があります。同じパターンを他のifで多かれ少なかれ使用することができ、最後の単独でelseを省略できます。
プログラミングの問題ごとに正しい構造を考案するのはプログラマーの責任です。 if elseの使用法をよりよく理解するために、例を見てみましょう
#include <stdio.h>
int main()
{
int num;
for(num = 0 ; num < 10 ; num = num + 1)
{
if (num == 2)
printf("num is now equal to %d\n", num);
if (num < 5)
printf("num is now %d, which is less than 5\n", num);
else
printf("num is now %d, which is greater than 4\n", num);
} /* end of for loop */
return 0;
}
プログラムの結果
num is now 0, which is less than 5
num is now 1, which is less than 5
num is now equal to 2
num is now 2, which is less than 5
num is now 3, which is less than 5
num is now 4, which is less than 5
num is now 5, which is greater than 4
num is now 6, which is greater than 4
num is now 7, which is greater than 4
num is now 8, which is greater than 4
num is now 9, which is greater than 4
switchステートメント
これは、多方向の決定の別の形式です。よく構成されていますが、次のような特定の場合にのみ使用できます。
- テストされる変数は1つだけで、すべてのブランチはその変数の値に依存する必要があります。変数は整数型である必要があります。 (int、long、short、またはchar)。
- 変数の可能な各値は、単一のブランチを制御できます。オプションで、最後のキャッチオールのデフォルトブランチを使用して、指定されていないすべてのケースをトラップできます。
以下の例は、物事を明確にします。これは、整数をあいまいな記述に変換する関数です。量が非常に少ない場合にのみ量を測定することに関心がある場合に役立ちます。
estimate(number)
int number;
/* Estimate a number as none, one, two, several, many */
{ switch(number) {
case 0 :
printf("None\n");
break;
case 1 :
printf("One\n");
break;
case 2 :
printf("Two\n");
break;
case 3 :
case 4 :
case 5 :
printf("Several\n");
break;
default :
printf("Many\n");
break;
}
}
それぞれの興味深いケースは、対応するアクションとともにリストされています。 breakステートメントは、スイッチを離れることにより、それ以上のステートメントが実行されないようにします。ケース3とケース4には後続のブレークがないため、数値のいくつかの値に対して同じアクションを許可し続けます。
if構文とswitch構文の両方を使用すると、プログラマーはいくつかの可能なアクションから選択を行うことができます。例を見てみましょう:
#include <stdio.h>
int main()
{
int num;
for (num = 3 ; num < 13 ; num = num + 1)
{
switch (num)
{
case 3 :
printf("The value is three\n");
break;
case 4 :
printf("The value is four\n");
break;
case 5 :
case 6 :
case 7 :
case 8 :
printf("The value is between 5 and 8\n");
break;
case 11 :
printf("The value is eleven\n");
break;
default :
printf("It is one of the undefined values\n");
break;
} /* end of switch */
} /* end of for loop */
return 0;
}
プログラムの出力は次のようになります
The value is three
The value is four
The value is between 5 and 8
The value is between 5 and 8
The value is between 5 and 8
The value is between 5 and 8
It is one of the undefined values
It is one of the undefined values
The value is eleven
It is one of the undefined values
ブレークステートメント
switchステートメントの議論ですでにブレークに遭遇しました。これは、ループまたはスイッチを終了し、ループまたはスイッチを超えて最初のステートメントに渡される制御を制御するために使用されます。
ループを使用すると、breakを使用して、ループを早期に終了したり、ループ本体の中央で終了するテストを使用してループを実装したりできます。ループ内の中断は、終了条件を制御するためのテストを提供するifステートメント内で常に保護する必要があります。
継続ステートメント
これはbreakに似ていますが、発生頻度は低くなります。これは、ループ制御ステートメントへの即時ジャンプを強制する効果があるループ内でのみ機能します。
- whileループで、テストステートメントにジャンプします。
- do whileループで、テストステートメントにジャンプします。
- forループで、テストにジャンプし、反復を実行します。
休憩のように、continueはifステートメントで保護する必要があります。頻繁に使用することはほとんどありません。ブレークの使用法をよりよく理解して続行するために、次のプログラムを調べてみましょう。
#include <stdio.h>
int main()
{
int value;
for(value = 5 ; value < 15 ; value = value + 1)
{
if (value == 8)
break;
printf("In the break loop, value is now %d\n", value);
}
for(value = 5 ; value < 15 ; value = value + 1)
{
if (value == 8)
continue;
printf("In the continue loop, value is now %d\n", value);
}
return 0;
}
プログラムの出力は次のようになります。
In the break loop, value is now 5
In the break loop, value is now 6
In the break loop, value is now 7
In the continue loop, value is now 5
In the continue loop, value is now 6
In the continue loop, value is now 7
In the continue loop, value is now 9
In the continue loop, value is now 10
In the continue loop, value is now 11
In the continue loop, value is now 12
In the continue loop, value is now 13
In the continue loop, value is now 14
ループ
他の主なタイプの制御ステートメントはループです。ループを使用すると、ステートメントまたはステートメントのブロックを繰り返すことができます。コンピュータは、単純なタスクを何度も繰り返すのが非常に得意です。ループはこれを達成するためのCの方法です。
Cでは、while、do-while、forの3種類のループを選択できます。
- whileループは、関連するテストがfalseを返すまでアクションを繰り返し続けます。これは、ループが何回トラバースされるかをプログラマーが事前に知らない場合に役立ちます。
- do whileループは似ていますが、ループ本体が実行された後にテストが実行されます。これにより、ループ本体が少なくとも1回実行されるようになります。
- forループは頻繁に使用され、通常、ループは一定の回数トラバースされます。それは非常に柔軟性があり、初心者のプログラマーはそれが提供する力を乱用しないように注意する必要があります。
whileループ
whileループは、上部のテストがfalseであることが判明するまで、ステートメントを繰り返します。例として、文字列の長さを返す関数を次に示します。文字列は、ヌル文字 '\ 0'で終了する文字の配列として表されることに注意してください。
int string_length(char string[])
{ int i = 0;
while (string[i] != '\0')
i++;
return(i);
}
文字列は引数として関数に渡されます。配列のサイズは指定されていません。関数は任意のサイズの文字列に対して機能します。
whileループは、ヌル文字が見つかるまで、文字列内の文字を一度に1つずつ調べるために使用されます。次に、ループが終了し、nullのインデックスが返されます。
文字がnullでない間、インデックスがインクリメントされ、テストが繰り返されます。アレイについては後で詳しく説明します。 whileループの例を見てみましょう。
#include <stdio.h>
int main()
{
int count;
count = 0;
while (count < 6)
{
printf("The value of count is %d\n", count);
count = count + 1;
}
return 0;
}
結果は次のように表示されます。
The value of count is 0
The value of count is 1
The value of count is 2
The value of count is 3
The value of count is 4
The value of count is 5
dowhileループ
これは、テストがループ本体の最後で行われることを除いて、whileループと非常によく似ています。これにより、続行する前にループが少なくとも1回実行されることが保証されます。
このような設定は、データを読み取る場合によく使用されます。次に、テストはデータを検証し、受け入れられない場合はループバックして再度読み取ります。
do
{
printf("Enter 1 for yes, 0 for no :");
scanf("%d", &input_value);
} while (input_value != 1 && input_value != 0)
do whileループをよりよく理解するために、次の例を見てみましょう。
#include <stdio.h>
int main()
{
int i;
i = 0;
do
{
printf("The value of i is now %d\n", i);
i = i + 1;
} while (i < 5);
return 0;
}
プログラムの結果は次のように表示されます。
The value of i is now 0
The value of i is now 1
The value of i is now 2
The value of i is now 3
The value of i is now 4
forループ
forループは、ループに入る前にループの反復回数がわかっている場合にうまく機能します。ループの先頭は、セミコロンで区切られた3つの部分で構成されています。
- 1つ目は、ループに入る前に実行されます。これは通常、ループ変数の初期化です。
- 2つ目はテストであり、これがfalseを返すとループが終了します。
- 3番目は、ループ本体が完了するたびに実行されるステートメントです。これは通常、ループカウンターの増分です。
この例は、配列に格納されている数値の平均を計算する関数です。この関数は、配列と要素の数を引数として受け取ります。
float average(float array[], int count)
{
float total = 0.0;
int i;
for(i = 0; i < count; i++)
total += array[i];
return(total / count);
}
forループは、平均を計算する前に、正しい数の配列要素が加算されることを保証します。
forループの先頭にある3つのステートメントは、通常、それぞれ1つのことだけを実行しますが、いずれも空白のままにすることができます。空白の最初または最後のステートメントは、初期化または実行中の増分がないことを意味します。空白の比較ステートメントは常にtrueとして扱われます。これにより、他の手段で中断されない限り、ループが無期限に実行されます。これはreturnまたはbreakステートメントである可能性があります。
複数のステートメントをコンマで区切って1番目または3番目の位置に圧縮することもできます。これにより、複数の制御変数を含むループが可能になります。以下の例は、そのようなループの定義を示しています。変数hiとloは、それぞれ100と0で始まり、収束しています。
forループは、その中で使用されるさまざまな省略形を提供します。次の式に注意してください。この式では、単一のループに2つのforループが含まれています。ここで、hi--はhi = hi-1と同じであり、lo ++はlo = lo +1と同じです
for(hi = 100, lo = 0; hi >= lo; hi--, lo++)
forループは非常に柔軟性があり、さまざまな種類のプログラムの動作を簡単かつ迅速に指定できます。 forループの例を見てみましょう
#include <stdio.h>
int main()
{
int index;
for(index = 0 ; index < 6 ; index = index + 1)
printf("The value of the index is %d\n", index);
return 0;
}
プログラムの結果は次のように表示されます。
The value of the index is 0
The value of the index is 1
The value of the index is 2
The value of the index is 3
The value of the index is 4
The value of the index is 5
gotoステートメント
Cには、構造化されていないジャンプを許可するgotoステートメントがあります。 gotoステートメントを使用するには、予約語gotoの後に、ジャンプ先の記号名を続けるだけです。次に、名前はプログラム内の任意の場所に配置され、その後にコロンが続きます。関数内のほぼどこにでもジャンプできますが、ループからジャンプすることは許可されていますが、ループにジャンプすることは許可されていません。
この特定のプログラムは実際には混乱していますが、ソフトウェア作成者がgotoステートメントの使用を可能な限り排除しようとしている理由の良い例です。このプログラムでgotoを使用するのが合理的な唯一の場所は、プログラムが1回のジャンプで3つのネストされたループからジャンプする場所です。この場合、変数を設定して3つのネストされたループのそれぞれから連続してジャンプするのはかなり面倒ですが、1つのgotoステートメントで3つすべてから非常に簡潔に抜け出すことができます。
goto文はいかなる状況でも決して使用されるべきではないと言う人もいますが、これは心の狭い考え方です。 gotoが他の構成よりも明確に制御フローを実行する場所がある場合は、モニターの残りのプログラムにあるので、自由に使用してください。例を見てみましょう:
#include <stdio.h>
int main()
{
int dog, cat, pig;
goto real_start;
some_where:
printf("This is another line of the mess.\n");
goto stop_it;
/* the following section is the only section with a useable goto */
real_start:
for(dog = 1 ; dog < 6 ; dog = dog + 1)
{
for(cat = 1 ; cat < 6 ; cat = cat + 1)
{
for(pig = 1 ; pig < 4 ; pig = pig + 1)
{
printf("Dog = %d Cat = %d Pig = %d\n", dog, cat, pig);
if ((dog + cat + pig) > 8 ) goto enough;
}
}
}
enough: printf("Those are enough animals for now.\n");
/* this is the end of the section with a useable goto statement */
printf("\nThis is the first line of the code.\n");
goto there;
where:
printf("This is the third line of the code.\n");
goto some_where;
there:
printf("This is the second line of the code.\n");
goto where;
stop_it:
printf("This is the last line of this mess.\n");
return 0;
}
表示された結果を見てみましょう
Dog = 1 Cat = 1 Pig = 1
Dog = 1 Cat = 1 Pig = 2
Dog = 1 Cat = 1 Pig = 3
Dog = 1 Cat = 2 Pig = 1
Dog = 1 Cat = 2 Pig = 2
Dog = 1 Cat = 2 Pig = 3
Dog = 1 Cat = 3 Pig = 1
Dog = 1 Cat = 3 Pig = 2
Dog = 1 Cat = 3 Pig = 3
Dog = 1 Cat = 4 Pig = 1
Dog = 1 Cat = 4 Pig = 2
Dog = 1 Cat = 4 Pig = 3
Dog = 1 Cat = 5 Pig = 1
Dog = 1 Cat = 5 Pig = 2
Dog = 1 Cat = 5 Pig = 3
Those are enough animals for now.
This is the first line of the code.
This is the second line of the code.
This is the third line of the code.
This is another line of the mess.
This is the last line of this mess.
ポインタ
変数がメモリ内のどこにあるかを知りたい場合があります。ポインタには特定の値を持つ変数のアドレスが含まれています。ポインタを宣言するときは、ポインタ名の直前にアスタリスクが付けられます。 。
変数が格納されているメモリ位置のアドレスは、変数名の前にアンパサンドを配置することで確認できます。
int num; /* Normal integer variable */
int *numPtr; /* Pointer to an integer variable */
次の例では、変数の値とその変数のメモリ内のアドレスを出力します。
printf(&quot;値%dはアドレス%Xに格納されます\ n&quot;、num、&amp; num);
変数numのアドレスをポインターnumPtrに割り当てるには、次に示す例のように、変数numのアドレスを割り当てます。
numPtr =&amp; num;
numPtrが指すアドレスに何が格納されているかを確認するには、変数を逆参照する必要があります。間接参照は、ポインターが宣言されたアスタリスクで実現されます。
printf(&quot;値%dはアドレス%Xに格納されます\ n&quot;、* numPtr、numPtr);
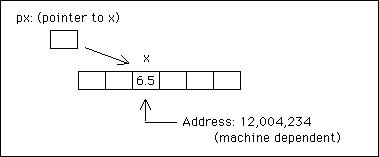
プログラム内のすべての変数はメモリに存在します。以下のステートメントは、コンパイラーが浮動小数点変数x用に32ビットコンピューターに4バイトのメモリーを予約し、それに値6.5を入れることを要求します。
float x;
x = 6.5;
任意の変数のメモリ内のアドレス位置は、演算子&amp;を配置することによって取得されます。したがって、その名前の前に&amp; xはxのアドレスです。 Cを使用すると、さらに1段階進んで、他の変数のアドレスを含むポインターと呼ばれる変数を定義できます。むしろ、ポインタは他の変数を指していると言えます。例えば:
float x;
float* px;
x = 6.5;
px = &x;
pxをfloat型のオブジェクトへのポインタとして定義し、xのアドレスと等しくなるように設定します。したがって、* pxはxの値を参照します。
次のステートメントを調べてみましょう。
int var_x;
int* ptrX;
var_x = 6;
ptrX = &var_x;
*ptrX = 12;
printf("value of x : %d", var_x);
最初の行により、コンパイラーは整数用にメモリー内のスペースを予約します。 2行目は、ポインターを保管するためのスペースを予約するようにコンパイラーに指示します。
ポインタは、アドレスの保存場所です。 3行目は、scanfステートメントを思い出させるはずです。アドレス&quot;&amp;&quot;演算子は、var_xを格納した場所に移動し、格納場所のアドレスをptrXに指定するようにコンパイラーに指示します。
変数の前にあるアスタリスク*は、ポインターを逆参照してメモリーに移動するようにコンパイラーに指示します。次に、その場所に保存されている変数に割り当てることができます。変数を参照し、ポインターを介してそのデータにアクセスできます。ポインタの例を見てみましょう。
/* illustration of pointer use */
#include <stdio.h>
int main()
{
int index, *pt1, *pt2;
index = 39; /* any numerical value */
pt1 = &index; /* the address of index */
pt2 = pt1;
printf("The value is %d %d %d\n", index, *pt1, *pt2);
*pt1 = 13; /* this changes the value of index */
printf("The value is %d %d %d\n", index, *pt1, *pt2);
return 0;
}
プログラムの出力は次のように表示されます。
The value is 39 39 39
The value is 13 13 13
ポインタの使用法をよりよく理解するために、別の例を見てみましょう。
#include <stdio.h>
#include <string.h>
int main()
{
char strg[40], *there, one, two;
int *pt, list[100], index;
strcpy(strg, "This is a character string.");
/* the function strcpy() is to copy one string to another. we’ll read about strcpy() function in String Section later */
one = strg[0]; /* one and two are identical */
two = *strg;
printf("The first output is %c %c\n", one, two);
one = strg[8]; /* one and two are identical */
two = *(strg+8);
printf("The second output is %c %c\n", one, two);
there = strg+10; /* strg+10 is identical to &strg[10] */
printf("The third output is %c\n", strg[10]);
printf("The fourth output is %c\n", *there);
for (index = 0 ; index < 100 ; index++)
list[index] = index + 100;
pt = list + 27;
printf("The fifth output is %d\n", list[27]);
printf("The sixth output is %d\n", *pt);
return 0;
}
プログラムの出力は次のようになります。
The first output is T T
The second output is a a
The third output is c
The fourth output is c
The fifth output is 127
The sixth output is 127
配列
配列は、同じタイプの変数のコレクションです。個々の配列要素は、整数インデックスによって識別されます。 Cでは、インデックスはゼロから始まり、常に角かっこで囲まれています。
このように宣言された一次元配列はすでに満たされています
intの結果[20];
配列はより多くの次元を持つことができます。その場合、配列は次のように宣言される可能性があります
int results_2d[20][5];
int results_3d[20][5][3];
各インデックスには、独自の角かっこがあります。配列はmain関数で宣言され、通常は次元の詳細が含まれています。配列の代わりにポインタと呼ばれる別のタイプを使用することができます。つまり、寸法はすぐには固定されませんが、必要に応じてスペースを割り当てることができます。これは、特定の特殊なプログラムでのみ必要とされる高度な手法です。
例として、1次元配列のすべての整数を合計する簡単な関数を次に示します。
int add_array(int array[], int size)
{
int i;
int total = 0;
for(i = 0; i < size; i++)
total += array[i];
return(total);
}
次に示すプログラムは、文字列を作成し、その中のいくつかのデータにアクセスして、それを印刷します。ポインタを使用して再度アクセスし、文字列を出力します。 「Hi!」と表示されます。と「012345678」は別の行にあります。プログラムのコーディングを見てみましょう。
#include <stdio.h>
#define STR_LENGTH 10
void main()
{
char Str[STR_LENGTH];
char* pStr;
int i;
Str[0] = 'H';
Str[1] = 'i';
Str[2] = '!';
Str[3] = '\0'; // special end string character NULL
printf("The string in Str is : %s\n", Str);
pStr = &Str[0];
for (i = 0; i < STR_LENGTH; i++)
{
*pStr = '0'+i;
pStr++;
}
Str[STR_LENGTH-1] = '\0';
printf("The string in Str is : %s\n", Str);
}
[](中括弧)は、配列を宣言するために使用されます。プログラムcharStr [STR_LENGTH]の行。 10文字の配列を宣言します。これらは10個の個別の文字であり、すべて同じ場所にメモリ内でまとめられています。これらはすべて、変数名Strと[n]を介してアクセスできます。ここで、nは要素番号です。
配列について話すときは、Cが10の配列を宣言するとき、アクセスできる要素には0から9の番号が付けられることに常に注意してください。最初の要素へのアクセスは0番目の要素へのアクセスに対応します。したがって、配列の場合、常に0から配列のサイズ-1までカウントします。
次に、「こんにちは!」という文字を入れていることに注意してください。配列に入れますが、「\ 0」を入れると、おそらくこれが何であるか疑問に思うでしょう。 &quot; \ 0&quot; NULLを表し、文字列の終わりを表します。すべての文字列は、この特殊文字 '\ 0'で終わる必要があります。そうでない場合、誰かが文字列に対してprintfを呼び出すと、printfは文字列のメモリ位置から開始し、「\ 0」に遭遇したことを通知して印刷を続行するため、最後に大量のゴミが発生します。あなたの文字列の。したがって、文字列を正しく終了するようにしてください。
文字配列
次のような文字列定数
"私はひもです"
文字の配列です。 Cでは、文字列内のASCII文字、つまり「I」、空白、「a」、「m」、または上記の文字列で内部的に表され、プログラムができるように特殊なヌル文字「\ 0」で終了します。文字列の終わりを見つけます。
文字列定数は、printfを使用してコードの出力を理解できるようにするためによく使用されます。
printf("Hello, world\n");
printf("The value of a is: %f\n", a);
文字列定数は変数に関連付けることができます。 Cは、一度に1文字(1バイト)を含むことができる文字型変数を提供します。文字列は、場所ごとに1つのASCII文字である文字タイプの配列に格納されます。
文字列は通常、ヌル文字「\ 0」で終了するため、配列内に1つの追加の格納場所が必要になることを忘れないでください。
Cは、文字列全体を一度に操作する演算子を提供していません。文字列は、ポインタを介して、または標準の文字列ライブラリstring.hから利用できる特別なルーチンを介して操作されます。
配列の名前は最初の要素への単なるポインタであるため、文字ポインタの使用は比較的簡単です。次に与えるプログラムを考えてみましょう。
#include<stdio.h>
void main()
{
char text_1[100], text_2[100], text_3[100];
char *ta, *tb;
int i;
/* set message to be an arrray */
/* of characters; initialize it */
/* to the constant string "..." */
/* let the compiler decide on */
/* its size by using [] */
char message[] = "Hello, I am a string; what are
you?";
printf("Original message: %s\n", message);
/* copy the message to text_1 */
i=0;
while ( (text_1[i] = message[i]) != '\0' )
i++;
printf("Text_1: %s\n", text_1);
/* use explicit pointer arithmetic */
ta=message;
tb=text_2;
while ( ( *tb++ = *ta++ ) != '\0' )
;
printf("Text_2: %s\n", text_2);
}
プログラムの出力は次のようになります。
Original message: Hello, I am a string; what are you?
Text_1: Hello, I am a string; what are you?
Text_2: Hello, I am a string; what are you?
標準の「文字列」ライブラリには、文字列を操作するための多くの便利な関数が含まれています。これについては、後で文字列のセクションで学習します。
要素へのアクセス
配列内の個々の要素にアクセスするには、インデックス番号が角括弧内の変数名の後に続きます。この変数は、Cの他の変数と同じように扱うことができます。次の例では、配列の最初の要素に値を割り当てます。
x[0] = 16;
次の例では、配列の3番目の要素の値を出力します。
printf("%d\n", x[2]);
次の例では、scanf関数を使用して、キーボードから10個の要素を持つ配列の最後の要素に値を読み取ります。
scanf("%d", &x[9]);
配列要素の初期化
配列は、他の変数と同じように代入によって初期化できます。配列には複数の値が含まれているため、個々の値は中括弧で囲まれ、コンマで区切られます。次の例では、3回の九九の最初の10個の値を使用して10次元配列を初期化します。
int x [10] = {3、6、9、12、15、18、21、24、27、30};
これにより、次の例のように値を個別に割り当てる必要がなくなります。
int x[10];
x[0] = 3;
x[1] = 6;
x[2] = 9;
x[3] = 12;
x[4] = 15;
x[5] = 18;
x[6] = 21;
x[7] = 24;
x[8] = 27;
x[9] = 30;
配列をループする
配列には順番にインデックスが付けられるため、forループを使用して配列のすべての値を表示できます。次の例は、配列のすべての値を表示します。
#include <stdio.h>
int main()
{
int x[10];
int counter;
/* Randomise the random number generator */
srand((unsigned)time(NULL));
/* Assign random values to the variable */
for (counter=0; counter<10; counter++)
x[counter] = rand();
/* Display the contents of the array */
for (counter=0; counter<10; counter++)
printf("element %d has the value %d\n", counter, x[counter]);
return 0;
}
出力は毎回異なる値を出力しますが、結果は次のように表示されます。
element 0 has the value 17132
element 1 has the value 24904
element 2 has the value 13466
element 3 has the value 3147
element 4 has the value 22006
element 5 has the value 10397
element 6 has the value 28114
element 7 has the value 19817
element 8 has the value 27430
element 9 has the value 22136
多次元配列
配列は複数の次元を持つことができます。配列に複数の次元を持たせることにより、柔軟性が向上します。たとえば、スプレッドシートは2次元配列で作成されます。行の配列と列の配列。
次の例では、それぞれ5つの列を含む2つの行を持つ2次元配列を使用しています。
#include <stdio.h>
int main()
{
/* Declare a 2 x 5 multidimensional array */
int x[2][5] = { {1, 2, 3, 4, 5},
{2, 4, 6, 8, 10} };
int row, column;
/* Display the rows */
for (row=0; row<2; row++)
{
/* Display the columns */
for (column=0; column<5; column++)
printf("%d\t", x[row][column]);
putchar('\n');
}
return 0;
}
このプログラムの出力は次のように表示されます。
1 2 3 4 5
2 4 6 8 10
文字列
文字列は文字のグループであり、通常はアルファベットの文字です。見栄えがよく、意味のある名前とタイトルがあり、あなたとあなたの出力を使用する人々に美的に喜ばれるように印刷表示をフォーマットするためにプログラム。
実際、前のトピックの例ではすでに文字列を使用しています。しかし、それは文字列の完全な導入ではありません。プログラミングには多くの可能性のあるケースがあり、フォーマットされた文字列を使用することで、プログラマーはプログラムの複雑さやバグの多さを回避できます。
文字列の完全な定義は、ヌル文字( ‘\ 0’)で終了する一連の文字タイプデータです。
Cが何らかの方法でデータの文字列を使用する場合、データを別の文字列と比較したり、出力したり、別の文字列にコピーしたりする場合、関数はnullになるまで呼び出されたとおりに実行するように設定されます。が検出されました。
代わりに、Cには文字列の基本的なデータ型はありません。 Cの文字列は、文字の配列として実装されます。たとえば、名前を格納するには、名前を格納するのに十分な大きさの文字配列を宣言してから、適切なライブラリ関数を使用して名前を操作できます。
次の例では、ユーザーが入力した文字列を画面に表示します。
#include <stdio.h>
int main()
{
char name[80]; /* Create a character array
called name */
printf("Enter your name: ");
gets(name);
printf("The name you entered was %s\n", name);
return 0;
}
プログラムの実行は次のようになります。
Enter your name: Tarun Tyagi
The name you entered was Tarun Tyagi
いくつかの一般的な文字列関数
標準のstring.hライブラリには、文字列を操作するための多くの便利な関数が含まれています。最も便利な関数のいくつかをここに示します。
strlen関数
strlen関数は、文字列の長さを決定するために使用されます。例を挙げてstrlenの使用法を学びましょう。
#include <stdio.h>
#include <string.h>
int main()
{
char name[80];
int length;
printf("Enter your name: ");
gets(name);
length = strlen(name);
printf("Your name has %d characters\n", length);
return 0;
}
また、プログラムの実行は次のようになります。
Enter your name: Tarun Subhash Tyagi
Your name has 19 characters
Enter your name: Preeti Tarun
Your name has 12 characters
strcpy関数
strcpy関数は、ある文字列を別の文字列にコピーするために使用されます。この関数の使用法を例を挙げて学びましょう。
#include <stdio.h>
#include <string.h>
int main()
{
char first[80];
char second[80];
printf("Enter first string: ");
gets(first);
printf("Enter second string: ");
gets(second);
printf("first: %s, and second: %s Before strcpy()\n "
, first, second);
strcpy(second, first);
printf("first: %s, and second: %s After strcpy()\n",
first, second);
return 0;
}
プログラムの出力は次のようになります。
Enter first string: Tarun
Enter second string: Tyagi
first: Tarun, and second: Tyagi Before strcpy()
first: Tarun, and second: Tarun After strcpy()
strcmp関数
strcmp関数は、2つの文字列を比較するために使用されます。配列の変数名は、その配列のベースアドレスを指します。したがって、以下を使用して2つの文字列を比較しようとすると、2つのアドレスを比較することになります。これは、同じ場所に2つの値を格納できないため、明らかに同じになることはありません。
if(first == second)/ *文字列を比較することはできません* /
次の例では、strcmp関数を使用して2つの文字列を比較します。
#include <string.h>
int main()
{
char first[80], second[80];
int t;
for(t=1;t<=2;t++)
{
printf("\nEnter a string: ");
gets(first);
printf("Enter another string: ");
gets(second);
if (strcmp(first, second) == 0)
puts("The two strings are equal");
else
puts("The two strings are not equal");
}
return 0;
}
また、プログラムの実行は次のようになります。
Enter a string: Tarun
Enter another string: tarun
The two strings are not equal
Enter a string: Tarun
Enter another string: Tarun
The two strings are equal
strcat関数
strcat関数は、ある文字列を別の文字列に結合するために使用されます。どのように見てみましょう?例の助けを借りて:
#include <string.h>
int main()
{
char first[80], second[80];
printf("Enter a string: ");
gets(first);
printf("Enter another string: ");
gets(second);
strcat(first, second);
printf("The two strings joined together: %s\n",
first);
return 0;
}
また、プログラムの実行は次のようになります。
Enter a string: Data
Enter another string: Recovery
The two strings joined together: DataRecovery
strtok関数
strtok関数は、文字列内の次のトークンを見つけるために使用されます。トークンは、可能な区切り文字のリストによって指定されます。
次の例では、ファイルから1行のテキストを読み取り、区切り文字、スペース、タブ、および改行を使用して単語を判別します。次に、各単語が別々の行に表示されます。
#include <stdio.h>
#include <string.h>
int main()
{
FILE *in;
char line[80];
char *delimiters = " \t\n";
char *token;
if ((in = fopen("C:\\text.txt", "r")) == NULL)
{
puts("Unable to open the input file");
return 0;
}
/* Read each line one at a time */
while(!feof(in))
{
/* Get one line */
fgets(line, 80, in);
if (!feof(in))
{
/* Break the line up into words */
token = strtok(line, delimiters);
while (token != NULL)
{
puts(token);
/* Get the next word */
token = strtok(NULL, delimiters);
}
}
}
fclose(in);
return 0;
}
プログラムの上にある= fopen(&quot; C:\\ text.txt&quot;、&quot; r&quot;)で、既存のファイルC:\\ text.txtを開きます。指定されたパスにが存在しない場合、または何らかの理由でファイルを開くことができなかった場合、エラーメッセージが画面に表示されます。
これらの関数のいくつかを使用する次の例を考えてみましょう。
#include <stdio.h>
#include <string.h>
void main()
{
char line[100], *sub_text;
/* initialize string */
strcpy(line,"hello, I am a string;");
printf("Line: %s\n", line);
/* add to end of string */
strcat(line," what are you?");
printf("Line: %s\n", line);
/* find length of string */
/* strlen brings back */
/* length as type size_t */
printf("Length of line: %d\n", (int)strlen(line));
/* find occurence of substrings */
if ( (sub_text = strchr ( line, 'W' ) )!= NULL )
printf("String starting with \"W\" ->%s\n",
sub_text);
if ( ( sub_text = strchr ( line, 'w' ) )!= NULL )
printf("String starting with \"w\" ->%s\n",
sub_text);
if ( ( sub_text = strchr ( sub_text, 'u' ) )!= NULL )
printf("String starting with \"w\" ->%s\n",
sub_text);
}
プログラムの出力は次のように表示されます。
Line: hello, I am a string;
Line: hello, I am a string; what are you?
Length of line: 35
String starting with "w" ->what are you?
String starting with "w" ->u?
関数
大規模なプログラムを開発および保守するための最良の方法は、それぞれが管理しやすい小さな部分からプログラムを構築することです(分割統治と呼ばれることもある手法)。関数を使用すると、プログラマーはプログラムをモジュール化できます。
関数を使用すると、複雑なプログラムを小さなブロックに分割できます。各ブロックは、書き込み、読み取り、および保守が容易です。すでに関数mainに遭遇し、標準ライブラリのprintfを利用しました。もちろん、独自の関数やヘッダーファイルを作成することもできます。関数のレイアウトは次のとおりです。
return-type function-name ( argument list if necessary )
{
local-declarations;
statements ;
return return-value;
}
return-typeを省略した場合、Cのデフォルトはintになります。戻り値は宣言された型でなければなりません。関数内で宣言されたすべての変数は、それらが定義された関数でのみ認識されるという点で、ローカル変数と呼ばれます。
一部の関数には、関数と関数を呼び出したモジュールとの間の通信方法を提供するパラメーターリストがあります。パラメータは、関数の外部では使用できないという点で、ローカル変数でもあります。これまでに取り上げたプログラムにはすべて、関数であるmainがあります。
関数は、値を返さずに単にタスクを実行する場合があります。その場合、関数のレイアウトは次のようになります。
void function-name ( argument list if necessary )
{
local-declarations ;
statements;
}
引数は、C関数呼び出しでは常に値によって渡されます。これは、引数の値のローカルコピーがルーチンに渡されることを意味します。関数の内部で引数に加えられた変更は、引数のローカルコピーにのみ行われます。
引数リストの引数を変更または定義するには、この引数をアドレスとして渡す必要があります。関数がこれらの引数の値を変更しない場合は、通常の変数を使用します。関数がこれらの引数の値を変更する場合は、ポインターを使用する必要があります。
Let us learn with examples:
#include <stdio.h>
void exchange ( int *a, int *b )
{
int temp;
temp = *a;
*a = *b;
*b = temp;
printf(" From function exchange: ");
printf("a = %d, b = %d\n", *a, *b);
}
void main()
{
int a, b;
a = 5;
b = 7;
printf("From main: a = %d, b = %d\n", a, b);
exchange(&a, &b);
printf("Back in main: ");
printf("a = %d, b = %d\n", a, b);
}
そして、このプログラムの出力は次のように表示されます。
From main: a = 5, b = 7
From function exchange: a = 7, b = 5
Back in main: a = 7, b = 5
別の例を見てみましょう。次の例では、1から10までの数値の2乗を書き込むsquareという関数を使用しています。
#include <stdio.h>
int square(int x); /* Function prototype */
int main()
{
int counter;
for (counter=1; counter<=10; counter++)
printf("Square of %d is %d\n", counter, square(counter));
return 0;
}
/* Define the function 'square' */
int square(int x)
{
return x * x;
}
このプログラムの出力は次のように表示されます。
Square of 1 is 1
Square of 2 is 4
Square of 3 is 9
Square of 4 is 16
Square of 5 is 25
Square of 6 is 36
Square of 7 is 49
Square of 8 is 64
Square of 9 is 81
Square of 10 is 100
関数プロトタイプsquareは、整数パラメーターを受け取り、整数を返す関数を宣言します。コンパイラがメインプログラムのsquareへの関数呼び出しに到達すると、関数の定義に対して関数呼び出しをチェックできます。
プログラムが関数squareを呼び出す行に到達すると、プログラムは関数にジャンプしてその関数を実行してから、メインプログラムのパスを再開します。戻り型を持たないプログラムは、voidを使用して宣言する必要があります。したがって、関数のパラメーターは、Pass ByValueまたはPassByReferenceの場合があります。
再帰関数は、それ自体を呼び出す関数です。そして、このプロセスは再帰と呼ばれます。
値渡し関数
前の例の2乗関数のパラメーターは、値によって渡されます。これは、変数のコピーのみが関数に渡されたことを意味します。値への変更は、呼び出し元の関数に反映されません。
次の例では、値渡しを使用し、渡されたパラメーターの値を変更します。これは、呼び出し元の関数には影響しません。関数count_downは、戻り型がないため、voidとして宣言されています。
#include <stdio.h>
void count_down(int x);
int main()
{
int counter;
for (counter=1; counter<=10; counter++)
count_down(counter);
return 0;
}
void count_down(int x)
{
int counter;
for (counter = x; counter > 0; counter--)
{
printf("%d ", x);
x--;
}
putchar('\n');
}
プログラムの出力は次のように表示されます。
1
2 1
3 2 1
4 3 2 1
5 4 3 2 1
6 5 4 3 2 1
7 6 5 4 3 2 1
8 7 6 5 4 3 2 1
9 8 7 6 5 4 3 2 1
10 9 8 7 6 5 4 3 2 1
理解を深めるために、別のCパスバイ値の例を見てみましょう。次の例では、ユーザーが入力した1〜30,000の数字を単語に変換します。
#include <stdio.h>
void do_units(int num);
void do_tens(int num);
void do_teens(int num);
int main()
{
int num, residue;
do
{
printf("Enter a number between 1 and 30,000: ");
scanf("%d", &num);
} while (num < 1 || num > 30000);
residue = num;
printf("%d in words = ", num);
do_tens(residue/1000);
if (num >= 1000)
printf("thousand ");
residue %= 1000;
do_units(residue/100);
if (residue >= 100)
{
printf("hundred ");
}
if (num > 100 && num%100 > 0)
printf("and ");
residue %=100;
do_tens(residue);
putchar('\n');
return 0;
}
void do_units(int num)
{
switch(num)
{
case 1:
printf("one ");
break;
case 2:
printf("two ");
break;
case 3:
printf("three ");
break;
case 4:
printf("four ");
break;
case 5:
printf("five ");
break;
case 6:
printf("six ");
break;
case 7:
printf("seven ");
break;
case 8:
printf("eight ");
break;
case 9:
printf("nine ");
}
}
void do_tens(int num)
{
switch(num/10)
{
case 1:
do_teens(num);
break;
case 2:
printf("twenty ");
break;
case 3:
printf("thirty ");
break;
case 4:
printf("forty ");
break;
case 5:
printf("fifty ");
break;
case 6:
printf("sixty ");
break;
case 7:
printf("seventy ");
break;
case 8:
printf("eighty ");
break;
case 9:
printf("ninety ");
}
if (num/10 != 1)
do_units(num%10);
}
void do_teens(int num)
{
switch(num)
{
case 10:
printf("ten ");
break;
case 11:
printf("eleven ");
break;
case 12:
printf("twelve ");
break;
case 13:
printf("thirteen ");
break;
case 14:
printf("fourteen ");
break;
case 15:
printf("fifteen ");
break;
case 16:
printf("sixteen ");
break;
case 17:
printf("seventeen ");
break;
case 18:
printf("eighteen ");
break;
case 19:
printf("nineteen ");
}
}
プログラムの出力は次のようになります。
Enter a number between 1 and 30,000: 12345
12345 in words = twelve thousand three hundred and forty five
参照による呼び出し
参照による関数呼び出しを行うには、変数自体を渡す代わりに、変数のアドレスを渡します。変数のアドレスは、&amp;を使用して取得できます。オペレーター。以下は、実際の値の代わりに変数のアドレスを渡すスワップ関数を呼び出します.
swap(&x, &y);
間接参照
現在の問題は、関数swapに変数ではなくアドレスが渡されているため、変数を逆参照して、変数をスワップするために変数のアドレスではなく実際の値を確認する必要があることです。
間接参照は、ポインター(*)表記を使用してCで実現されます。簡単に言うと、これは、アドレスではなく変数の値を参照するために、使用する前に各変数の前に*を配置することを意味します。次のプログラムは、2つの値を交換するための参照渡しを示しています。
#include <stdio.h>
void swap(int *x, int *y);
int main()
{
int x=6, y=10;
printf("Before the function swap, x = %d and y =
%d\n\n", x, y);
swap(&x, &y);
printf("After the function swap, x = %d and y =
%d\n\n", x, y);
return 0;
}
void swap(int *x, int *y)
{
int temp = *x;
*x = *y;
*y = temp;
}
プログラムの出力を見てみましょう。
Before the function swap, x = 6 and y = 10
After the function swap, x = 10 and y = 6
関数は再帰的である可能性があります。つまり、関数はそれ自体を呼び出す可能性があります。それ自体を呼び出すたびに、関数の現在の状態がスタックにプッシュされる必要があります。スタックオーバーフローは簡単に発生するため、この事実を覚えておくことが重要です。つまり、スタックにデータを配置するためのスペースが不足しています。
次の例では、再帰を使用して数値の階乗を計算します。階乗は、それ自体の下にある1つおきの整数を掛けた数値で、1になります。たとえば、数値6の階乗は次のとおりです。
階乗6 = 6 * 5 * 4 * 3 * 2 * 1
したがって、6の階乗は720です。上記の例から、階乗6 = 6 *階乗5であることがわかります。同様に、階乗5 = 5 *階乗4などです。
階乗数を計算するための一般的な規則は次のとおりです。
factorial(n)= n * factorial(n-1)
上記のルールは、1の階乗が1であるため、n = 1のときに終了します。例を使用して、それをよりよく理解してみましょう。
#include <stdio.h>
long int factorial(int num);
int main()
{
int num;
long int f;
printf("Enter a number: ");
scanf("%d", &num);
f = factorial(num);
printf("factorial of %d is %ld\n", num, f);
return 0;
}
long int factorial(int num)
{
if (num == 1)
return 1;
else
return num * factorial(num-1);
}
このプログラムの実行の出力を見てみましょう。
Enter a number: 7
factorial of 7 is 5040
Cでのメモリ割り当て
Cコンパイラには、malloc.hで定義されているメモリ割り当てライブラリがあります。メモリはmalloc関数を使用して予約され、アドレスへのポインタを返します。 1つのパラメータ、バイト単位で必要なメモリのサイズを取ります。
次の例では、文字列にスペースを割り当てます。 "こんにちは世界".
ptr =(char *)malloc(strlen("こんにちは世界") + 1);
文字列の終了文字「\ 0」を考慮するために、余分な1バイトが必要です。 (char *)はキャストと呼ばれ、戻り型を強制的にchar *にします。
データ型にはさまざまなサイズがあり、mallocはスペースをバイト単位で返すため、移植性の理由から、割り当てるサイズを指定するときにsizeof演算子を使用することをお勧めします。
次の例では、文字列を文字配列バッファに読み込み、必要なメモリの正確な量を割り当てて、「ptr」という変数にコピーします。
#include <string.h>
#include <malloc.h>
int main()
{
char *ptr, buffer[80];
printf("Enter a string: ");
gets(buffer);
ptr = (char *)malloc((strlen(buffer) + 1) *
sizeof(char));
strcpy(ptr, buffer);
printf("You entered: %s\n", ptr);
return 0;
}
プログラムの出力は次のようになります。
Enter a string: India is the best
You entered: India is the best
メモリの再割り当て
プログラミング中に、メモリを再割り当てすることが何度も可能です。これは、realloc関数を使用して実行されます。 realloc関数は、サイズを変更するメモリのベースアドレスと、予約するスペースの量の2つのパラメータを取り、ベースアドレスへのポインタを返します。
msgというポインタ用にスペースを予約していて、すでに使用しているスペースの量と別の文字列の長さにスペースを再割り当てしたいとします。次のように使用できます。
msg =(char *)realloc(msg、(strlen(msg)+ strlen(buffer)+ 1)* sizeof(char));
次のプログラムは、malloc、realloc、およびfreeの使用法を示しています。ユーザーは、結合された一連の文字列を入力します。空の文字列が入力されると、プログラムは文字列の読み取りを停止します。
#include <string.h>
#include <malloc.h>
int main()
{
char buffer[80], *msg;
int firstTime=0;
do
{
printf("\nEnter a sentence: ");
gets(buffer);
if (!firstTime)
{
msg = (char *)malloc((strlen(buffer) + 1) *
sizeof(char));
strcpy(msg, buffer);
firstTime = 1;
}
else
{
msg = (char *)realloc(msg, (strlen(msg) +
strlen(buffer) + 1) * sizeof(char));
strcat(msg, buffer);
}
puts(msg);
} while(strcmp(buffer, ""));
free(msg);
return 0;
}
プログラムの出力は次のようになります。
Enter a sentence: Once upon a time
Once upon a time
Enter a sentence: there was a king
Once upon a timethere was a king
Enter a sentence: the king was
Once upon a timethere was a kingthe king was
Enter a sentence:
Once upon a timethere was a kingthe king was
メモリの解放
割り当てられたメモリを使い終わったら、リソースを解放して速度を向上させるため、メモリを解放することを忘れないでください。割り当てられたメモリを解放するには、free機能を使用します。
free(ptr);
構造
Cには、基本的なデータ型に加えて、相互に関連するデータ項目を共通の名前でグループ化できる構造メカニズムがあります。これは通常、ユーザー定義型と呼ばれます。
キーワードstructは構造体定義を開始し、タグは構造体に一意の名前を付けます。構造体に追加されたデータ型と変数名は、構造体のメンバーです。結果は、型指定子として使用できる構造テンプレートです。以下は、月のタグが付いた構造です。
struct month
{
char name[10];
char abbrev[4];
int days;
};
構造型は通常、typedefステートメントを使用してファイルの先頭近くで定義されます。 typedefは新しい型を定義して名前を付け、プログラム全体で使用できるようにします。 typedefは通常、ファイル内の#defineステートメントと#includeステートメントの直後に発生します。
typedefキーワードは、構造体の名前でstructキーワードを指定するのではなく、構造体を参照する単語を定義するために使用できます。 typedefには大文字で名前を付けるのが一般的です。構造体定義の例を次に示します。
typedef struct {
char name[64];
char course[128];
int age;
int year;
} student; これは、student型の新しい型student変数を次のように宣言できることを定義します。
学生st_rec;
これがintまたはfloatの宣言にどれほど似ているかに注目してください。変数名はst_recで、name、course、age、yearというメンバーがあります。同様に、
typedef struct element
{
char data;
struct element *next;
} STACKELEMENT;
A variable of the user defined type struct element may now be declared as follows.
STACKELEMENT *stack;
次の構造を検討してください。
struct student
{
char *name;
int grade;
};
構造体studentへのポインタは次のように定義できます。
struct student *hnc;
When accessing a pointer to a structure, the member pointer operator, -> is used instead of the dot operator. To add a grade to a structure,
s.grade = 50;
次のように、構造にグレードを割り当てることができます。
s-&gt; grade = 50;
基本的なデータ型と同様に、渡されるパラメーターに対して関数で行われた変更を永続的にする場合は、参照で渡す(アドレスを渡す)必要があります。メカニズムは、基本的なデータ型とまったく同じです。アドレスを渡し、ポインタ表記を使用して変数を参照します。
構造を定義したら、そのインスタンスを宣言し、ドット表記を使用してメンバーに値を割り当てることができます。次の例は、月構造の使用法を示しています。
#include <stdio.h>
#include <string.h>
struct month
{
char name[10];
char abbreviation[4];
int days;
};
int main()
{
struct month m;
strcpy(m.name, "January");
strcpy(m.abbreviation, "Jan");
m.days = 31;
printf("%s is abbreviated as %s and has %d days\n", m.name, m.abbreviation, m.days);
return 0;
}
プログラムの出力は次のようになります。
January is abbreviated as Jan and has 31 days
すべてのANSICコンパイラでは、メンバーごとのコピーを実行して、ある構造を別の構造に割り当てることができます。 m1およびm2と呼ばれる月構造がある場合、次のようにm1からm2に値を割り当てることができます。
- ポインタメンバーを使用した構造。
- 構造が初期化されます。
- 構造体を関数に渡す。
- ポインタと構造。
Cのポインタメンバーを持つ構造
固定サイズの配列で文字列を保持することは、メモリの非効率的な使用です。より効率的なアプローチは、ポインターを使用することです。ポインターは、通常のポインター定義で使用されるのとまったく同じ方法で構造体で使用されます。例を見てみましょう:
#include <string.h>
#include <malloc.h>
struct month
{
char *name;
char *abbreviation;
int days;
};
int main()
{
struct month m;
m.name = (char *)malloc((strlen("January")+1) *
sizeof(char));
strcpy(m.name, "January");
m.abbreviation = (char *)malloc((strlen("Jan")+1) *
sizeof(char));
strcpy(m.abbreviation, "Jan");
m.days = 31;
printf("%s is abbreviated as %s and has %d days\n",
m.name, m.abbreviation, m.days);
return 0;
}
プログラムの出力は次のようになります。
1月は1月と省略され、31日あります
Cの構造イニシャライザー
構造体の初期値のセットを提供するために、Initialisersを宣言ステートメントに追加できます。月は1から始まりますが、配列はCでゼロから始まります。次の例では、位置0にジャンクと呼ばれる追加の要素が使用されています。
#include <stdio.h>
#include <string.h>
struct month
{
char *name;
char *abbreviation;
int days;
} month_details[] =
{
"Junk", "Junk", 0,
"January", "Jan", 31,
"February", "Feb", 28,
"March", "Mar", 31,
"April", "Apr", 30,
"May", "May", 31,
"June", "Jun", 30,
"July", "Jul", 31,
"August", "Aug", 31,
"September", "Sep", 30,
"October", "Oct", 31,
"November", "Nov", 30,
"December", "Dec", 31
};
int main()
{
int counter;
for (counter=1; counter<=12; counter++)
printf("%s is abbreviated as %s and has %d days\n",
month_details[counter].name,
month_details[counter].abbreviation,
month_details[counter].days);
return 0;
}
そして、出力は次のように表示されます。
January is abbreviated as Jan and has 31 days
February is abbreviated as Feb and has 28 days
March is abbreviated as Mar and has 31 days
April is abbreviated as Apr and has 30 days
May is abbreviated as May and has 31 days
June is abbreviated as Jun and has 30 days
July is abbreviated as Jul and has 31 days
August is abbreviated as Aug and has 31 days
September is abbreviated as Sep and has 30 days
October is abbreviated as Oct and has 31 days
November is abbreviated as Nov and has 30 days
December is abbreviated as Dec and has 31 days
Cの関数に構造体を渡す
構造体は、基本的なデータ型と同様に、パラメーターとして関数に渡すことができます。次の例では、isLeapYear関数に渡されたdateという構造を使用して、年がうるう年であるかどうかを判別します。
通常は日の値のみを渡しますが、関数への構造体の受け渡しを説明するために構造体全体が渡されます。
#include <stdio.h>
#include <string.h>
struct month
{
char *name;
char *abbreviation;
int days;
} month_details[] =
{
"Junk", "Junk", 0,
"January", "Jan", 31,
"February", "Feb", 28,
"March", "Mar", 31,
"April", "Apr", 30,
"May", "May", 31,
"June", "Jun", 30,
"July", "Jul", 31,
"August", "Aug", 31,
"September", "Sep", 30,
"October", "Oct", 31,
"November", "Nov", 30,
"December", "Dec", 31
};
struct date
{
int day;
int month;
int year;
};
int isLeapYear(struct date d);
int main()
{
struct date d;
printf("Enter the date (eg: 11/11/1980): ");
scanf("%d/%d/%d", &d.day, &d.month, &d.year);
printf("The date %d %s %d is ", d.day,
month_details[d.month].name, d.year);
if (isLeapYear(d) == 0)
printf("not ");
puts("a leap year");
return 0;
}
int isLeapYear(struct date d)
{
if ((d.year % 4 == 0 && d.year % 100 != 0) ||
d.year % 400 == 0)
return 1;
return 0;
}
また、プログラムの実行は次のようになります。
Enter the date (eg: 11/11/1980): 9/12/1980
The date 9 December 1980 is a leap year
次の例では、構造体の配列を動的に割り当てて、学生の名前と成績を保存します。その後、成績は昇順でユーザーに表示されます。
#include <string.h>
#include <malloc.h>
struct student
{
char *name;
int grade;
};
void swap(struct student *x, struct student *y);
int main()
{
struct student *group;
char buffer[80];
int spurious;
int inner, outer;
int counter, numStudents;
printf("How many students are there in the group: ");
scanf("%d", &numStudents);
group = (struct student *)malloc(numStudents *
sizeof(struct student));
for (counter=0; counter<numStudents; counter++)
{
spurious = getchar();
printf("Enter the name of the student: ");
gets(buffer);
group[counter].name = (char *)malloc((strlen(buffer)+1) * sizeof(char));
strcpy(group[counter].name, buffer);
printf("Enter grade: ");
scanf("%d", &group[counter].grade);
}
for (outer=0; outer<numStudents; outer++)
for (inner=0; inner<outer; inner++)
if (group[outer].grade <
group[inner].grade)
swap(&group[outer], &group[inner]);
puts("The group in ascending order of grades ...");
for (counter=0; counter<numStudents; counter++)
printf("%s achieved Grade %d \n”,
group[counter].name,
group[counter].grade);
return 0;
}
void swap(struct student *x, struct student *y)
{
struct student temp;
temp.name = (char *)malloc((strlen(x->name)+1) *
sizeof(char));
strcpy(temp.name, x->name);
temp.grade = x->grade;
x->grade = y->grade;
x->name = (char *)malloc((strlen(y->name)+1) *
sizeof(char));
strcpy(x->name, y->name);
y->grade = temp.grade;
y->name = (char *)malloc((strlen(temp.name)+1) *
sizeof(char));
strcpy(y->name, temp.name);
}
出力の実行は次のようになります。
How many students are there in the group: 4
Enter the name of the student: Anuraaj
Enter grade: 7
Enter the name of the student: Honey
Enter grade: 2
Enter the name of the student: Meetushi
Enter grade: 1
Enter the name of the student: Deepti
Enter grade: 4
The group in ascending order of grades ...
Meetushi achieved Grade 1
Honey achieved Grade 2
Deepti achieved Grade 4
Anuraaj achieved Grade 7
連合
共用体を使用すると、同じデータを異なるタイプで表示したり、同じデータを異なる名前で使用したりすることができます。ユニオンは構造に似ています。ユニオンは、構造体と同じ方法で宣言および使用されます。
共用体は、一度に1つのメンバーしか使用できないという点で構造体とは異なります。この理由は単純です。組合のすべてのメンバーは、同じ記憶領域を占めます。それらは互いに重なり合っています。
ユニオンは、構造体と同じ方法で定義および宣言されます。宣言の唯一の違いは、structの代わりにキーワードunionが使用されることです。 char変数とinteger変数の単純な和集合を定義するには、次のように記述します。
union shared {
char c;
int i;
};
共有されているこのユニオンは、文字値cまたは整数値iのいずれかを保持できるユニオンのインスタンスを作成するために使用できます。これはOR条件です。両方の値を保持する構造とは異なり、ユニオンは一度に1つの値しか保持できません。
ユニオンは、その宣言で初期化できます。一度に使用できるメンバーは1つだけであり、初期化できるのは1つだけだからです。混乱を避けるために、ユニオンの最初のメンバーのみを初期化できます。次のコードは、宣言および初期化されている共有ユニオンのインスタンスを示しています。
union shared generic_variable = {`@ '};
構造体の最初のメンバーが初期化されるのと同じように、generic_variableユニオンが初期化されたことに注意してください。
個々の共用体メンバーは、メンバー演算子(。)を使用して構造体メンバーを使用するのと同じ方法で使用できます。ただし、共用体メンバーへのアクセスには重要な違いがあります。
一度にアクセスできる組合員は1人だけです。ユニオンはメンバーを相互に重ねて保存するため、一度に1つのメンバーにのみアクセスすることが重要です。
ユニオンキーワード
union tag {
union_member(s);
/* additional statements may go here */
}instance;
unionキーワードは、共用体を宣言するために使用されます。ユニオンは、単一の名前でグループ化された1つ以上の変数(union_members)のコレクションです。さらに、これらの組合員のそれぞれが同じ記憶領域を占めています。
キーワードunionは、ユニオン定義の始まりを識別します。その後に、ユニオンに付けられた名前のタグが続きます。タグの後には、中かっこで囲まれた組合員が続きます。
インスタンス、つまりユニオンの実際の宣言も定義できます。インスタンスなしで構造を定義する場合、それは後でプログラムで構造を宣言するために使用できる単なるテンプレートです。テンプレートの形式は次のとおりです。
union tag {
union_member(s);
/* additional statements may go here */
};
テンプレートを使用するには、次の形式を使用します。
ユニオンタグインスタンス。
この形式を使用するには、指定されたタグでユニオンを事前に宣言しておく必要があります。
/* Declare a union template called tag */
union tag {
int num;
char alps;
}
/* Use the union template */
union tag mixed_variable;
/* Declare a union and instance together */
union generic_type_tag {
char c;
int i;
float f;
double d;
} generic;
/* Initialize a union. */
union date_tag {
char full_date[9];
struct part_date_tag {
char month[2];
char break_value1;
char day[2];
char break_value2;
char year[2];
} part_date;
}date = {"09/12/80"};
例を参考にして、それをよりよく理解しましょう。
#include <stdio.h>
int main()
{
union
{
int value; /* This is the first part of the union */
struct
{
char first; /* These two values are the second part of it */
char second;
} half;
} number;
long index;
for (index = 12 ; index < 300000L ; index += 35231L)
{
number.value = index;
printf("%8x %6x %6x\n", number.value,
number.half.first,
number.half.second);
}
return 0;
}
そして、プログラムの出力は次のように表示されます。
c c 0
89ab ffab ff89
134a 4a 13
9ce9 ffe9 ff9c
2688 ff88 26
b027 27 ffb0
39c6 ffc6 39
c365 65 ffc3
4d04 4 4d
データリカバリにおけるユニオンの実用化
ここで、unionの実際の使用法がデータ回復プログラミングであることを見てみましょう。少し例を見てみましょう。次のプログラムは、フロッピーディスクドライブ(a :)の不良セクタスキャンプログラムの小さなモデルですが、不良セクタスキャンソフトウェアの完全なモデルではありません。
プログラムを調べてみましょう。
#include<dos.h>
#include<conio.h>
int main()
{
int rp, head, track, sector, status;
char *buf;
union REGS in, out;
struct SREGS s;
clrscr();
/* Reset the disk system to initialize to disk */
printf("\n Resetting the disk system....");
for(rp=0;rp<=2;rp++)
{
in.h.ah = 0;
in.h.dl = 0x00;
int86(0x13,&in,&out);
}
printf("\n\n\n Now Testing the Disk for Bad Sectors....");
/* scan for bad sectors */
for(track=0;track<=79;track++)
{
for(head=0;head<=1;head++)
{
for(sector=1;sector<=18;sector++)
{
in.h.ah = 0x04;
in.h.al = 1;
in.h.dl = 0x00;
in.h.ch = track;
in.h.dh = head;
in.h.cl = sector;
in.x.bx = FP_OFF(buf);
s.es = FP_SEG(buf);
int86x(0x13,&in,&out,&s);
if(out.x.cflag)
{
status=out.h.ah;
printf("\n track:%d Head:%d Sector:%d Status ==0x%X",track,head,sector,status);
}
}
}
}
printf("\n\n\nDone");
return 0;
}
次に、フロッピーディスクに不良セクタがある場合の出力がどのようになるかを見てみましょう。
ディスクシステムをリセットしています...
不良セクタについてディスクをテストしています...
track:0 Head:0 Sector:4 Status ==0xA
track:0 Head:0 Sector:5 Status ==0xA
track:1 Head:0 Sector:4 Status ==0xA
track:1 Head:0 Sector:5 Status ==0xA
track:1 Head:0 Sector:6 Status ==0xA
track:1 Head:0 Sector:7 Status ==0xA
track:1 Head:0 Sector:8 Status ==0xA
track:1 Head:0 Sector:11 Status ==0xA
track:1 Head:0 Sector:12 Status ==0xA
track:1 Head:0 Sector:13 Status ==0xA
track:1 Head:0 Sector:14 Status ==0xA
track:1 Head:0 Sector:15 Status ==0xA
track:1 Head:0 Sector:16 Status ==0xA
track:1 Head:0 Sector:17 Status ==0xA
track:1 Head:0 Sector:18 Status ==0xA
track:1 Head:1 Sector:5 Status ==0xA
track:1 Head:1 Sector:6 Status ==0xA
track:1 Head:1 Sector:7 Status ==0xA
track:1 Head:1 Sector:8 Status ==0xA
track:1 Head:1 Sector:9 Status ==0xA
track:1 Head:1 Sector:10 Status ==0xA
track:1 Head:1 Sector:11 Status ==0xA
track:1 Head:1 Sector:12 Status ==0xA
track:1 Head:1 Sector:13 Status ==0xA
track:1 Head:1 Sector:14 Status ==0xA
track:1 Head:1 Sector:15 Status ==0xA
track:1 Head:1 Sector:16 Status ==0xA
track:1 Head:1 Sector:17 Status ==0xA
track:1 Head:1 Sector:18 Status ==0xA
track:2 Head:0 Sector:4 Status ==0xA
track:2 Head:0 Sector:5 Status ==0xA
track:14 Head:0 Sector:6 Status ==0xA
Done
このプログラムで使用されている機能や割り込みを理解して、ディスクの不良セクタを確認したり、ディスクシステムをリセットしたりするのは少し難しいかもしれませんが、心配する必要はありません。BIOSと割り込みプログラミングでこれらすべてを学習します。次の章の後半のセクション。
Cでのファイル処理
Cでのファイルアクセスは、ストリームをファイルに関連付けることによって実現されます。 Cは、ファイルポインタと呼ばれる新しいデータ型を使用してファイルと通信します。このタイプはstdio.h内で定義され、FILE *として記述されます。 output_fileというファイルポインタは、次のようなステートメントで宣言されます。
FILE * output_file;
fopen関数のファイルモード
プログラムは、ファイルにアクセスする前にファイルを開く必要があります。これは、必要なファイルポインタを返すfopen関数を使用して行われます。何らかの理由でファイルを開くことができない場合は、値NULLが返されます。通常、fopenは次のように使用します
if ((output_file = fopen("output_file", "w")) == NULL)
fprintf(stderr, "Cannot open %s\n",
"output_file");
fopenは2つの引数を取ります。どちらも文字列です。最初の引数は開くファイルの名前、2番目の引数はアクセス文字で、通常はr、a、wなどのいずれかです。ファイルはさまざまなモードで開くことができます。次の表に示すように。
| File Modes |
| r |
Open a text file for reading. |
| w |
Create a text file for writing. If the file exists, it is overwritten. |
| a |
Open a text file in append mode. Text is added to the end of the file. |
| rb |
Open a binary file for reading. |
| wb |
Create a binary file for writing. If the file exists, it is overwritten. |
| ab |
Open a binary file in append mode. Data is added to the end of the file. |
| r+ |
Open a text file for reading and writing. |
| w+ |
Create a text file for reading and writing. If the file exists, it is overwritten. |
| a+ |
Open a text file for reading and writing at the end. |
| r+b or rb+ |
Open binary file for reading and writing. |
| w+b or wb+ |
Create a binary file for reading and writing. If the file exists, it is overwritten. |
| a+b or ab+ |
Open a text file for reading and writing at the end. |
更新モードは、fseek、fsetpos、および巻き戻し機能で使用されます。 fopen関数はファイルポインタを返します。エラーが発生した場合はNULLを返します。
次の例では、ファイルtarun.txtを読み取り専用モードで開きます。ファイルが存在するかどうかをテストすることをお勧めします。
if ((in = fopen("tarun.txt", "r")) == NULL)
{
puts("Unable to open the file");
return 0;
}
ファイルを閉じる
fclose関数を使用してファイルを閉じます。構文は次のとおりです。
fclose(in);
ファイルの読み取り
feof関数は、ファイルの終わりをテストするために使用されます。関数fgetc、fscanf、およびfgetsは、ファイルからデータを読み取るために使用されます。
次の例は、fgetcを使用してファイルを一度に1文字ずつ読み取ることにより、画面上のファイルの内容を一覧表示します。
#include <stdio.h>
int main()
{
FILE *in;
int key;
if ((in = fopen("tarun.txt", "r")) == NULL)
{
puts("Unable to open the file");
return 0;
}
while (!feof(in))
{
key = fgetc(in);
/* The last character read is the end of file marker so don't print it */
if (!feof(in))
putchar(key);
}
fclose(in);
return 0;
}
次の例のように、fscanf関数を使用して、ファイルからさまざまなデータ型を読み取ることができます。ただし、ファイル内のデータがfscanfで使用されるフォーマット文字列の形式である必要があります。
fscanf(in、&quot;%d /%d /%d&quot;、&amp; day、&amp; month、&amp; year);
fgets関数は、ファイルからいくつかの文字を読み取るために使用されます。 stdinは標準入力ファイルストリームであり、fgets関数を使用して入力を制御できます。
ファイルへの書き込み
fputcとfprintfを使用してデータをファイルに書き込むことができます。次の例では、fgetc関数とfputc関数を使用して、テキストファイルのコピーを作成します。
#include <stdio.h>
int main()
{
FILE *in, *out;
int key;
if ((in = fopen("tarun.txt", "r")) == NULL)
{
puts("Unable to open the file");
return 0;
}
out = fopen("copy.txt", "w");
while (!feof(in))
{
key = fgetc(in);
if (!feof(in))
fputc(key, out);
}
fclose(in);
fclose(out);
return 0;
}
fprintf関数を使用して、フォーマットされたデータをファイルに書き込むことができます。
fprintf(out, "Date: %02d/%02d/%02d\n",
day, month, year);
Cを使用したコマンドライン引数
main()関数を宣言するためのANSI C定義は、次のいずれかです。
int main()またはint main(int argc、char ** argv)
2番目のバージョンでは、コマンドラインから引数を渡すことができます。パラメーターargcは引数カウンターであり、コマンドラインから渡されたパラメーターの数が含まれています。パラメータargvは、渡された実際のパラメータを表す文字列へのポインタの配列である引数ベクトルです。
次の例では、コマンドラインから任意の数の引数を渡して出力できます。 argv [0]は実際のプログラムです。プログラムは、コマンドプロンプトから実行する必要があります。
#include <stdio.h>
int main(int argc, char **argv)
{
int counter;
puts("The arguments to the program are:");
for (counter=0; counter<argc; counter++)
puts(argv[counter]);
return 0;
}
If the program name was count.c, it could be called as follows from the command line.
count 3
or
count 7
or
count 192 etc.
次の例では、ファイル処理ルーチンを使用して、テキストファイルを新しいファイルにコピーします。たとえば、コマンドライン引数は次のように呼び出すことができます。
txtcpy one.txt two.txt
#include <stdio.h>
int main(int argc, char **argv)
{
FILE *in, *out;
int key;
if (argc < 3)
{
puts("Usage: txtcpy source destination\n");
puts("The source must be an existing file");
puts("If the destination file exists, it will be
overwritten");
return 0;
}
if ((in = fopen(argv[1], "r")) == NULL)
{
puts("Unable to open the file to be copied");
return 0;
}
if ((out = fopen(argv[2], "w")) == NULL)
{
puts("Unable to open the output file");
return 0;
}
while (!feof(in))
{
key = fgetc(in);
if (!feof(in))
fputc(key, out);
}
fclose(in);
fclose(out);
return 0;
}
ビットごとのマニピュレータ
ハードウェアレベルでは、データは2進数として表されます。数値59の2進表現は111011です。ビット0は最下位ビットであり、この場合、ビット5が最上位ビットです。
各ビットセットは、ビットセットの2の累乗として計算されます。ビット演算子を使用すると、整数変数をビットレベルで操作できます。以下に、59という数値の2進表現を示します。
| binary representation of the number 59 |
| bit 5 4 3 2 1 0 |
| 2 power n 32 16 8 4 2 1 |
| set 1 1 1 0 1 1 |
3ビットの場合、0から7までの数字を表すことができます。次の表に、0から7までの数字を2進形式で示します。
| Binary Digits |
| 000 |
0 |
| 001 |
1 |
| 010 |
2 |
| 011 |
3 |
| 100 |
4 |
| 101 |
5 |
| 110 |
6 |
| 111 |
7 |
次の表に、2進数の操作に使用できるビット演算子を示します。
| Binary Digits |
| & |
Bitwise AND |
| | |
Bitwise OR |
| ^ |
Bitwise Exclusive OR |
| ~ |
Bitwise Complement |
| << |
Bitwise Shift Left |
| >> |
Bitwise Shift Right |
ビットごとのAND
ビット単位のANDは、両方のビットが設定されている場合にのみTrueになります。次の例は、数値23と12のビットごとのANDの結果を示しています。
| 10111 (23)
01100 (12) AND
____________________
00100 (result = 4) |
マスク値を使用して、特定のビットが設定されているかどうかを確認できます。ビット1と3が設定されているかどうかを確認したい場合は、数値を10(ビット1と3の場合の値)でマスクし、結果をマスクに対してテストできます。
#include <stdio.h>
int main()
{
int num, mask = 10;
printf("Enter a number: ");
scanf("%d", &num);
if ((num & mask) == mask)
puts("Bits 1 and 3 are set");
else
puts("Bits 1 and 3 are not set");
return 0;
}
ビットごとのOR
いずれかのビットが設定されている場合、ビットごとのORは真です。以下は、数値23と12のビットごとのORの結果を示しています。
| 10111 (23)
01100 (12) OR
______________________
11111 (result = 31) |
マスクを使用して、1つまたは複数のビットが設定されていることを確認できます。次の例では、ビット2が設定されていることを確認します。
#include <stdio.h>
int main()
{
int num, mask = 4;
printf("Enter a number: ");
scanf("%d", &num);
num |= mask;
printf("After ensuring bit 2 is set: %d\n", num);
return 0;
}
ビット単位の排他的論理和
ビット単位の排他的論理和は、両方ではなくいずれかのビットが設定されている場合にTrueになります。以下は、数値23と12のビット単位の排他的論理和の結果を示しています。
| 10111 (23)
01100 (12) Exclusive OR (XOR)
_____________________________
11011 (result = 27) |
排他的論理和にはいくつかの興味深い特性があります。数値を排他的論理和する場合、ゼロはゼロのままであり、両方を設定することはできないため、ゼロに設定されるため、ゼロに設定されます。
この結果、ある数値を別の数値と排他的論理和し、その結果を別の数値と排他的論理和すると、結果は元の数値になります。上記の例で使用されている番号でこれを試すことができます。
23 XOR 12 = 27
27 XOR 12 = 23
27 XOR 23 = 12
この機能は暗号化に使用できます。次のプログラムは、23の暗号化キーを使用して、ユーザーが入力した番号のプロパティを示しています。
#include <stdio.h>
int main()
{
int num, key = 23;
printf("Enter a number: ");
scanf("%d", &num);
num ^= key;
printf("Exclusive OR with %d gives %d\n", key, num);
num ^= key;
printf("Exclusive OR with %d gives %d\n", key, num);
return 0;
}
ビット単位の褒め言葉
ビット単位の補数は、ビットのオンとオフを切り替える1の補数演算子です。 1の場合は0に設定され、0の場合は1に設定されます。
#include <stdio.h>
int main()
{
int num = 0xFFFF;
printf("The compliment of %X is %X\n", num, ~num);
return 0;
}
ビット単位の左シフト
ビット単位の左シフト演算子は、数値を左にシフトします。数値が左に移動すると最上位ビットが失われ、空になった最下位ビットはゼロになります。以下に、43のバイナリ表現を示します。
0101011(10進数43)
ビットを左にシフトすることにより、最上位ビット(この場合はゼロ)が失われ、最下位ビットで数値がゼロで埋められます。結果の数値は次のとおりです。
1010110(10進数の86)
ビット単位の右シフト
ビット単位の右シフト演算子は、数値を右にシフトします。空になった最上位ビットにゼロが導入され、空になった最下位ビットが失われます。以下に、数値43の2進表現を示します。
0101011(10進数43)
ビットを右にシフトすると、最下位ビット(この場合は1)が失われ、最上位ビットの数値にゼロが埋め込まれます。結果の数値は次のとおりです。
0010101(10進数21)
次のプログラムは、ビット単位の右シフトとビット単位のANDを使用して、数値を16ビットの2進数として表示します。数値は16からゼロまで連続して右にシフトされ、ビットごとに1とAND演算されて、ビットが設定されているかどうかが確認されます。別の方法は、ビット単位のOR演算子で連続するマスクを使用することです。
#include <stdio.h>
int main()
{
int counter, num;
printf("Enter a number: ");
scanf("%d", &num);
printf("%d is binary: ", num);
for (counter=15; counter>=0; counter--)
printf("%d", (num >> counter) & 1);
putchar('\n');
return 0;
}
2進数–10進数変換の関数
次に示す2つの関数は、2進数から10進数への変換と10進数から2進数への変換です。 10進数を対応する2進数に変換するために次に示す関数は、最大32ビットの2進数をサポートします。要件に応じて、これまたは前に提供されたプログラムを変換に使用できます。
10進数から2進数への変換関数:
void Decimal_to_Binary(void)
{
int input =0;
int i;
int count = 0;
int binary [32]; /* 32 Bit, MAXIMUM 32 elements */
printf ("Enter Decimal number to convert into
Binary :");
scanf ("%d", &input);
do
{
i = input%2; /* MOD 2 to get 1 or a 0*/
binary[count] = i; /* Load Elements into the Binary Array */
input = input/2; /* Divide input by 2 to decrement via binary */
count++; /* Count how many elements are needed*/
}while (input > 0);
/* Reverse and output binary digits */
printf ("Binary representation is: ");
do
{
printf ("%d", binary[count - 1]);
count--;
} while (count > 0);
printf ("\n");
}
2進数から10進数への変換関数:
次の関数は、任意の2進数を対応する10進数に変換することです。
void Binary_to_Decimal(void)
{
char binaryhold[512];
char *binary;
int i=0;
int dec = 0;
int z;
printf ("Please enter the Binary Digits.\n");
printf ("Binary digits are either 0 or 1 Only ");
printf ("Binary Entry : ");
binary = gets(binaryhold);
i=strlen(binary);
for (z=0; z<i; ++z)
{
dec=dec*2+(binary[z]=='1'? 1:0); /* if Binary[z] is
equal to 1,
then 1 else 0 */
}
printf ("\n");
printf ("Decimal value of %s is %d",
binary, dec);
printf ("\n");
}
デバッグとテスト
構文エラー
構文とは、ステートメント内の要素の文法、構造、および順序を指します。ステートメントをセミコロンで終了するのを忘れるなど、ルールに違反すると構文エラーが発生します。プログラムをコンパイルすると、コンパイラーは発生する可能性のある構文エラーのリストを生成します。
優れたコンパイラは、エラーの説明を含むリストを出力し、可能な解決策を提供する可能性があります。エラーを修正すると、再コンパイル時にさらにエラーが表示される場合があります。これは、以前のエラーによってプログラムの構造が変更されたため、元のコンパイル中にそれ以上のエラーが抑制されたためです。
同様に、1つのミスで複数のエラーが発生する可能性があります。正しくコンパイルおよび実行されるプログラムのメイン関数の最後にセミコロンを付けてみてください。再コンパイルすると、エラーの膨大なリストが表示されますが、セミコロンの位置が間違っているだけです。
構文エラーだけでなく、コンパイラも警告を発行する場合があります。警告はエラーではありませんが、プログラムの実行中に問題を引き起こす可能性があります。たとえば、倍精度浮動小数点数を単精度浮動小数点数に割り当てると、精度が低下する可能性があります。構文エラーではありませんが、問題が発生する可能性があります。この特定の例では、変数を適切なデータ型にキャストすることで意図を示すことができます。
次の例を考えてみましょう。ここで、xは単精度浮動小数点数であり、yは倍精度浮動小数点数です。 yは、割り当て中に明示的にfloatにキャストされます。これにより、コンパイラーの警告がなくなります。
x =(float)y;
論理エラー
ロジックエラーは、ロジックにエラーがある場合に発生します。たとえば、数値が4未満で8より大きいことをテストできます。これはおそらく真実ではありませんが、構文的に正しい場合、プログラムは正常にコンパイルされます。次の例を考えてみましょう。
if (x < 4 && x > 8)
puts("Will never happen!");
構文が正しいため、プログラムはコンパイルされますが、xの値が同時に4より小さく8より大きい可能性があるため、putsステートメントは出力されません。
ほとんどの論理エラーは、プログラムの初期テストを通じて発見されます。期待どおりに動作しない場合は、論理ステートメントをより詳細に調べて修正します。これは、明らかな論理エラーにのみ当てはまります。プログラムが大きいほど、プログラムを通過するパスが多くなり、プログラムが期待どおりに動作することを確認するのが難しくなります。
テスト
ソフトウェア開発プロセスでは、開発中のどの段階でもエラーが発生する可能性があります。これは、ソフトウェア開発の初期段階の検証方法が手動であるためです。したがって、コーディングアクティビティ中に開発されたコードには、コーディングアクティビティ中に導入されたエラーに加えて、いくつかの要件エラーと設計エラーが発生する可能性があります。テスト中、テスト対象のプログラムは一連のテストケースを使用して実行され、テストケースのプログラムの出力が評価されて、プログラミングが期待どおりに実行されているかどうかが判断されます。
したがって、テストとは、ソフトウェアアイテムを分析して、既存の条件と必要な条件(バグなど)の違いを検出し、ソフトウェアアイテムの機能を評価するプロセスです。したがって、テストは、エラーを見つけることを目的としてプログラムを分析するプロセスです。
いくつかのテスト原則
- テストでは、欠陥がないことを示すことはできず、欠陥があることだけを示すことができます。
- エラーが発生するのが早いほど、コストが高くなります。
- 後でエラーが検出されると、コストが高くなります。
次に、いくつかのテスト手法について説明します。
ホワイトボックステスト
ホワイトボックステストは、プログラム内のすべてのパスをすべての可能な値でテストする手法です。このアプローチには、プログラムがどのように動作するかについての知識が必要です。たとえば、プログラムが1〜50の整数値を受け入れた場合、ホワイトボックステストは50の値すべてを使用してプログラムをテストし、それぞれが正しいことを確認してから、整数が取る可能性のある他のすべての値をテストし、期待どおりに動作しました。一般的なプログラムが持つ可能性のあるデータ項目の数を考慮すると、可能な順列により、大規模なプログラムのホワイトボックステストは非常に困難になります。
ホワイトボックステストは、大規模なプログラムのセーフティクリティカルな機能に適用でき、残りの多くは、以下で説明するブラックボックステストを使用してテストされます。順列の数が多いため、ホワイトボックステストは通常、テストハーネスを使用して実行されます。この場合、値の範囲が特別なプログラムを介してプログラムに迅速に供給され、予想される動作の例外がログに記録されます。ホワイトボックステストは、構造テスト、クリアボックステスト、またはオープンボックステストと呼ばれることもあります。
ブラックボックステスト
ブラックボックステストはホワイトボックステストに似ていますが、可能なすべての値をテストするのではなく、選択した値をテストする点が異なります。このタイプのテストでは、テスターは入力と期待される結果がどうあるべきかを知っていますが、必ずしもプログラムがそれらに到達した方法を知っているわけではありません。ブラックボックステストは、機能テストと呼ばれることもあります。
ブラックボックステストのテストケースは、通常、プログラムの仕様が完成するとすぐに考案されます。テストケースは、同値類に基づいています。
同値類
入力ごとに、等価クラスは有効な状態と無効な状態を識別します。等価クラスを定義するときに計画するシナリオは、一般に3つあります。
入力が範囲または特定の値を指定する場合、1つの有効な状態と、2つの無効な状態が定義されます。たとえば、数値が1から20の間でなければならない場合、有効な状態は1から20の間であり、1未満の場合は無効な状態になり、20を超える場合は無効な状態になります。
入力が範囲または特定の値を除外する場合、2つの有効な状態があり、1つの無効な状態が定義されます。たとえば、数値が1〜20であってはならない場合、有効な状態は1未満で20を超え、無効な状態は1〜20です。
入力でブール値が指定されている場合、1つは有効、もう1つは無効の2つの状態になります。
境界値分析
境界値分析では、入力の境界にある値のみが考慮されます。たとえば、数値が1〜20の場合、テストケースは1、20、0、21になります。その背後にある考え方は、プログラムがこれらの値で期待どおりに機能する場合、他の値も期待どおりに動作します。
次の表に、特定する可能性のある一般的な境界の概要を示します。
| Testing Ranges |
| Input type |
Test Values |
| Range |
- x[lower_bound]-1
- x[lower_bound]
- x[upper_bound]
- x[upper_bound]+1
|
| Boolean |
|
テスト計画の策定
同値類を特定し、各クラスについて境界を特定します。クラスの境界を特定したら、境界に有効な値と無効な値のリスト、および予想される動作を記述します。次に、テスターは境界値を使用してプログラムを実行し、境界値が必要な結果に対してテストされたときに何が起こったかを示すことができます。
以下は、許容値が10から110の範囲にある、入力されている年齢をチェックするために使用される典型的なテスト計画です。
| Equivalence Class |
| Valid |
Invalid |
| Between 10 and 110 |
> 110 |
|
< 10 |
同値類を定義したので、年齢のテスト計画を立てることができます。
| Test Plan |
| Value |
State |
Expected Result |
Actual Result |
| 10 |
Valid |
Continue execution to get name |
|
| 110 |
Valid |
Continue execution to get name |
|
| 9 |
Invalid |
Ask for age again |
|
| 111 |
Invalid |
Ask for age again |
|
「実際の結果」テスト時に完了するため、列は空白のままになります。結果が期待どおりの場合、列にチェックマークが付けられます。そうでない場合は、何が起こったかを示すコメントを入力する必要があります。

 家
家