第 5 章
C 程序设计简介
介绍
“C”是当今计算机世界中最流行的计算机语言之一。 “C”编程语言由贝尔研究实验室的 Brian Kernighan 和 Dennis Ritchie 于 1972 年设计和开发。
“C”是一种专门创建的语言,旨在允许程序员访问几乎所有机器的内部结构——寄存器、I/O 插槽和绝对地址。同时,“C”允许尽可能多的数据处理和编程文本模块化,以允许以有组织和及时的方式构建非常复杂的多程序员项目。
尽管该语言最初旨在在 UNIX 下运行,但人们对在 IBM PC 和兼容机上的 MS-DOS 操作系统下运行它产生了浓厚的兴趣。由于表达简单、代码紧凑、适用范围广,因此它是这种环境下的优秀语言。
此外,由于编写 C 编译器的简单性和易用性,它通常是任何新计算机(包括微型计算机、小型计算机和大型机)上可用的第一种高级语言。
为什么在数据恢复编程中使用 C
在当今的计算机编程世界中,有许多高级语言可供使用。这些语言具有许多适合大多数编程任务的特性。然而,有几个原因使 C 成为愿意为数据恢复、系统编程、设备编程或硬件编程进行编程的程序员的首选:
- C 是专业程序员首选的流行语言。因此,可以使用各种各样的 C 编译器和有用的附件。
- C 是一种可移植语言。为一个计算机系统编写的 C 程序可以编译并在另一个系统上运行,只需很少或无需修改。 C 的 ANSI 标准(C 编译器的一组规则)增强了可移植性。
- C 允许在编程中广泛使用模块。 C 代码可以编写在称为函数的例程中。 这些函数可以在其他应用程序或程序中重用。您无需在新应用程序的编程中付出额外的努力来创建您之前在另一个应用程序编程中开发的相同模块。
您可以在新程序中使用此功能而无需任何更改或一些小的更改。在数据恢复编程的情况下,当您需要在不同程序的不同应用程序中多次运行相同的功能时,您会发现这种质量非常有帮助。
- C 是一种强大而灵活的语言。这就是为什么 C 被用于各种项目的原因,例如操作系统、文字处理器、图形、电子表格,甚至是其他语言的编译器。
- C 是一种少词的语言,只包含少量的术语,称为关键字,它们是构建语言功能的基础。这些关键字,也称为保留字,使它更强大,提供更广泛的编程领域,让程序员感觉可以用 C 进行任何类型的编程。
让我假设你对 C 语言一无所知
我假设你对 C 编程一无所知,也对编程一无所知。我将从最基本的 C 概念开始,带您进入高级 C 编程,包括通常令人生畏的指针、结构和动态分配概念。
要完全理解这些概念,您需要花费大量时间和精力,因为它们不是特别容易掌握,但它们是非常强大的工具。
在那些您可能需要使用汇编语言但宁愿保持其易于编写和易于维护的程序的领域中,C 编程是一项巨大的资产。在这种情况下,C 编码节省的时间可能是巨大的。
尽管 C 语言在将程序从一种实现传输到另一种实现时有着良好的记录,但在您尝试使用另一种编译器时,您会发现编译器之间存在差异。
当您使用非标准扩展(例如在使用 MS-DOS 时调用 DOS BIOS)时,大多数差异会变得很明显,但即使是这些差异也可以通过仔细选择编程结构来最小化。
当 C 编程语言明显成为广泛的计算机上可用的一种非常流行的语言时,一群关心的人开会提出了一套使用 C 编程语言的标准规则。
该小组代表了软件行业的各个部门,经过多次会议和许多初稿,他们最终为 C 语言编写了一个可接受的标准。 它已被美国国家标准协会(ANSI)接受,并由国际标准组织 (ISO)。
它不是强加给任何团体或用户的,但由于它被广泛接受,任何编译器编写者拒绝遵守该标准将是经济上的自杀。
本书中编写的程序主要用于 IBM-PC 或兼容计算机,但可以与任何 ANSI 标准编译器一起使用,因为它非常符合 ANSI 标准。
让我们开始
在你可以用任何语言做任何事情并开始编程之前,你必须知道如何命名一个标识符。标识符用于任何变量、函数、数据定义等。在 C 编程语言中,标识符是字母数字字符的组合,第一个是字母表中的字母或下划线,其余是字母、任何数字或下划线。
命名标识符时必须牢记两条规则。
- 字母字符的大小写很重要。 C 是区分大小写的语言。这意味着 Recovery 与 recovery 不同,并且 rEcOveRY 与前面提到的两者不同。
- 根据 ANSI-C 标准,至少可以使用 31 个有效字符,符合 ANSI-C 的编译器会认为这些字符是有效的。如果使用超过 31 个,则任何给定编译器都可以忽略第 31 个之后的所有字符。
关键字
C 中有 32 个词被定义为关键字。这些词具有预定义的用途,不能用于 C 程序中的任何其他目的。编译器使用它们来帮助编译程序。它们总是小写。完整列表如下:
| auto |
break |
case |
char |
| const |
continue |
default |
do |
| double |
else |
enum |
extern |
| float |
for |
goto |
if |
| int |
long |
register |
return |
| short |
signed |
sizeof |
static |
| struct |
switch |
typedef |
union |
| unsigned |
void |
volatile |
while |
在这里,我们看到了 C 的魔力。仅 32 个关键字 的精彩集合在不同的应用程序中提供了广泛的用途。任何计算机程序都需要考虑两个实体,即数据和程序。他们高度依赖彼此,对两者的仔细规划会产生一个精心策划和编写良好的程序。
让我们从一个简单的 C 程序开始:
/* 第一个学习 C 的程序 */
#include <stdio.h>
void main()
{
printf("This is a C program\n"); // printing a message
}
虽然程序很简单,但有几点值得注意。让我们检查一下上面的程序。 /* 和 */ 中的所有内容都被视为注释,编译器将忽略它。您不应该在其他评论中包含评论,因此不允许这样的事情:
/* 这是 /* 注释 */ 在注释中,这是错误的 */
还有一种在一行内工作的文档方式。通过使用 // 我们可以在该行中添加小文档。
每个 C 程序都包含一个名为 main 的函数。这是程序的起点。每个函数都应该返回一个值。在这个程序中,函数 main 没有返回值,因此我们编写了 void main。我们也可以把这个程序写成:
/* 第一个学习 C 的程序 */
#include <stdio.h>
main()
{
printf("This is a C program\n"); // printing a message
return 0;
}
两个程序相同,执行相同的任务。这两个程序的结果都会在屏幕上打印以下输出:
这是一个 C 程序
#include<stdio.h> 允许程序与计算机的屏幕、键盘和文件系统进行交互。您会在几乎每个 C 程序的开头找到它。
main() 声明函数的开始,而两个大括号表示函数的开始和结束。 C 中的花括号用于将语句组合在一起,就像在函数中或在循环体中一样。这种分组称为复合语句或块。
printf("This is a C program\n"); 在屏幕上打印单词。要打印的文本用双引号括起来。文本末尾的 \n 告诉程序打印一个新行作为输出的一部分。 printf() 函数用于监视显示输出。
大多数 C 程序都是小写字母。您通常会在稍后讨论的预处理器定义中使用大写字母,或者在引号内作为字符串的一部分。
C编译程序
让我们的程序名称为 CPROG.C。要输入和编译 C 程序,请按以下步骤操作:
- 创建 C 程序的活动目录并启动编辑器。为此,可以使用任何文本编辑器,但大多数 C 编译器(例如 Borland 的 Turbo C++)都有一个集成开发环境 (IDE),可让您在一个方便的设置中输入、编译和链接您的程序。
- 编写并保存源代码。您应该将文件命名为 CPROG.C。
- 编译并链接 CPROG.C。执行编译器手册指定的适当命令。您应该会收到一条消息,指出没有错误或警告。
- 检查编译器消息。如果您没有收到错误或警告,那么一切都应该没问题。如果键入程序有任何错误,编译器将捕获它并显示错误消息。更正错误,显示在错误消息中。
- 您的第一个 C 程序现在应该已经编译并可以运行了。如果您显示所有名为 CPROG 的文件的目录列表,您将获得四个具有不同扩展名的文件,如下所述:
- CPROG.C,源代码文件
- CPROG.BAK,你用编辑器创建的源文件的备份文件
- CPROG.OBJ,包含 CPROG.C 的目标代码
- CPROG.EXE,编译和链接CPROG.C时创建的可执行程序
- 要执行或运行 CPROG.EXE,只需输入 cprog。屏幕上会显示“这是一个 C 程序”消息。
现在让我们检查以下程序:
/* 第一个学习 C 的程序 */ // 1
// 2
#include <stdio.h> // 3
// 4
main() // 5
{
// 6
printf("This is a C program\n"); // 7
// 8
return 0; // 9
} // 10
编译此程序时,编译器会显示类似于以下内容的消息:
cprog.c(8) : 错误: `;'预计
让我们分段分解此错误消息。 cprog.c 是发现错误的文件的名称。 (8) 是发现错误的行号。错误:`;'预期是错误的描述。
此消息信息量很大,它告诉您在 CPROG.C 的第 8 行,编译器希望找到一个分号,但没有。但是,您知道第 7 行中实际上省略了分号,因此存在差异。
为什么编译器会在第 8 行报告错误,而实际上,第 7 行中省略了分号。答案在于 C 不关心诸如换行之类的事情。属于 printf() 语句之后的分号可以放在下一行,尽管这样做在实践中是不好的编程。
只有在第 8 行遇到下一个命令(return)后,编译器才确定缺少分号。因此,编译器报告错误在第 8 行。
可能存在多种不同类型错误的可能性。让我们讨论链接错误消息。链接器错误比较少见,通常是由于 C 库函数名称拼写错误造成的。在这种情况下,您会收到一条错误:未定义符号:错误消息,后跟拼写错误的名称。更正拼写后,问题就会消失。
打印数字
让我们看下面的例子:
// 如何打印数字 //
#include<stdio.h>
void main()
{
int num = 10;
printf(“ The Number Is %d”, num);
}
程序的输出将在屏幕上显示如下:
数字是 10
% 符号用于表示许多不同类型变量的输出。 % 符号后面的字符是 d,它指示输出例程获取十进制值并将其输出。
使用变量
在 C 中,必须先声明变量,然后才能使用它。变量可以在任何代码块的开头声明,但大多数都在每个函数的开头。大多数局部变量是在调用函数时创建的,并在从该函数返回时销毁。
要在 C 程序中使用变量,在 C 中为变量命名时必须了解以下规则:
- 名称可以包含字母、数字和下划线字符 (_)。
- 名称的第一个字符必须是字母。下划线也是合法的第一个字符,但不建议使用。
- C 区分大小写,因此变量名 num 与 Num 不同。
- C 关键字不能用作变量名。关键字是 C 语言的一部分。
以下列表包含一些合法和非法 C 变量名称的示例:
| Variable Name |
Legal or Not |
| Num |
Legal |
| Ttpt2_t2p |
Legal |
| Tt pt |
Illegal: Space is not allowed |
| _1990_tax |
Legal but not advised |
| Jack_phone# |
Illegal: Contains the illegal character # |
| Case |
Illegal: Is a C keyword |
| 1book |
Illegal: First character is a digit |
第一个突出的新东西是main()主体的第一行:
整数 = 10;
这一行定义了一个名为 'num' 的 int 类型的变量,并用值 10 对其进行初始化。这也可以写成:
int num; /* define uninitialized variable 'num' */
/* and after all variable definitions: */
num = 10; /* assigns value 10 to variable 'num' */
变量可以定义在块的开头(大括号 {和} 之间),通常是在函数体的开头,但也可以在另一种类型的块的开头。
在块开头定义的变量默认为“自动”状态。这意味着它们仅在块执行期间存在。当函数开始执行时,变量将被创建,但它们的内容将是未定义的。当函数返回时,变量将被销毁。定义也可以写成:
auto int num = 10;
由于带或不带 auto 关键字的定义是完全等价的,所以 auto 关键字显然是相当多余的。
但是,有时这不是您想要的。假设您想要一个函数来计算它被调用的次数。如果每次函数返回时变量都会被销毁,这是不可能的。
因此,可以为变量赋予所谓的静态持续时间,这意味着它将在程序的整个执行过程中保持不变。例如:
static int num = 10;
这将在程序执行开始时将变量 num 初始化为 10。从那时起,价值将保持不变;如果函数被多次调用,变量将不会被重新初始化。
有时仅从一个函数访问变量是不够的,或者通过参数将值传递给所有其他需要它的函数可能不方便。
但是,如果您需要从整个源文件中的所有函数访问变量,也可以使用 static 关键字来完成,但将定义放在所有函数之外。例如:
#include <stdio.h>
static int num = 10; /* will be accessible from entire source file */
int main(void)
{
printf("The Number Is: %d\n", num);
return 0;
}
在某些情况下,需要从整个程序访问变量,这可能由多个源文件组成。这称为全局变量,在不需要时应避免使用。
这也可以通过将定义放在所有函数之外来完成,但不使用 static 关键字:
#include <stdio.h>
int num = 10; /* will be accessible from entire program! */
int main(void)
{
printf("The Number Is: %d\n", num);
return 0;
}
还有 extern 关键字,用于访问其他模块中的全局变量。您还可以将一些限定符添加到变量定义中。其中最重要的是 const。不能修改定义为 const 的变量。
还有两个不太常用的修饰符。 volatile 和 register 修饰符。 volatile 修饰符要求编译器在每次读取时实际访问该变量。它可能不会通过将变量放在寄存器中来优化变量。这主要用于多线程和中断处理等目的。
register 修饰符请求编译器将变量优化为寄存器。这仅适用于自动变量,并且在许多情况下编译器可以更好地选择要优化到寄存器中的变量,因此该关键字已过时。制作变量寄存器的唯一直接后果是无法获取其地址。
下页给出的变量表描述了五种存储类的存储类。
在表格中,我们看到关键字 extern 被放置在两行中。 extern 关键字在函数中用于声明在别处定义的静态外部变量。
数值变量类型
C 提供了几种不同类型的数值变量,因为不同的数值具有不同的内存存储要求。这些数字类型的不同之处在于对它们执行某些数学运算的难易程度。
小整数需要较少的内存来存储,并且您的计算机可以非常快速地执行此类数字的数学运算。大整数和浮点值需要更多的存储空间和更多的数学运算时间。通过使用适当的变量类型,您可以确保您的程序尽可能高效地运行。
C 的数值变量分为以下两大类:
在这些类别中的每一个中都有两个或更多特定的变量类型。下面给出的表格显示了保存每种类型的单个变量所需的内存量(以字节为单位)。
char 类型可能等同于 signed char 或 unsigned char,但它始终是与这两种类型中的任何一种不同的类型。
在 C 中,将字符或其对应的数值存储在变量中没有区别,因此也不需要函数在字符与其数值之间进行转换,反之亦然。对于其他整数类型,如果您省略有符号或无符号,则默认值将是有符号的,例如int 和signed int 是等价的。
int类型必须大于等于short类型,小于等于long类型。如果您只需要存储一些不是很大的值,那么使用 int 类型通常是个好主意;它通常是处理器最容易处理的大小,因此也是最快的。
对于几个编译器来说,double 和 long double 是等价的。再加上大多数标准数学函数都使用 double 类型这一事实,如果您必须使用小数,则始终使用 double 类型是一个很好的理由。
下表是为了更好地描述变量类型:

常用的特殊用途类型:
| Variable Type |
Description |
| size_t |
unsigned type used for storing the sizes of objects in bytes |
| time_t |
used to store results of the time() function |
| clock_t |
used to store results of the clock() function |
| FILE |
used for accessing a stream (usually a file or device) |
| ptrdiff_t |
signed type of the difference between 2 pointers |
| div_t |
used to store results of the div() function |
| ldiv_t |
used to store results of ldiv() function |
| fpos_t |
used to hold file position information |
| va_list |
used in variable argument handling |
| wchar_t |
wide character type (used for extended character sets) |
| sig_atomic_t |
used in signal handlers |
| Jmp_buf |
used for non-local jumps |
为了更好地理解这些变量,让我们举个例子:
/* 程序告诉 C 变量的范围和大小(以字节为单位)*/
#include <stdio.h>
int main()
{
int a; /* simple integer type */
long int b; /* long integer type */
short int c; /* short integer type */
unsigned int d; /* unsigned integer type */
char e; /* character type */
float f; /* floating point type */
double g; /* double precision floating point */
a = 1023;
b = 2222;
c = 123;
d = 1234;
e = 'X';
f = 3.14159;
g = 3.1415926535898;
printf( "\nA char is %d bytes", sizeof( char ));
printf( "\nAn int is %d bytes", sizeof( int ));
printf( "\nA short is %d bytes", sizeof( short ));
printf( "\nA long is %d bytes", sizeof( long ));
printf( "\nAn unsigned char is %d bytes",
sizeof( unsigned char ));
printf( "\nAn unsigned int is %d bytes",
sizeof( unsigned int ));
printf( "\nAn unsigned short is %d bytes",
sizeof( unsigned short ));
printf( "\nAn unsigned long is %d bytes",
sizeof( unsigned long ));
printf( "\nA float is %d bytes", sizeof( float ));
printf( "\nA double is %d bytes\n", sizeof( double ));
printf("a = %d\n", a); /* decimal output */
printf("a = %o\n", a); /* octal output */
printf("a = %x\n", a); /* hexadecimal output */
printf("b = %ld\n", b); /* decimal long output */
printf("c = %d\n", c); /* decimal short output */
printf("d = %u\n", d); /* unsigned output */
printf("e = %c\n", e); /* character output */
printf("f = %f\n", f); /* floating output */
printf("g = %f\n", g); /* double float output */
printf("\n");
printf("a = %d\n", a); /* simple int output */
printf("a = %7d\n", a); /* use a field width of 7 */
printf("a = %-7d\n", a); /* left justify in
field of 7 */
c = 5;
d = 8;
printf("a = %*d\n", c, a); /* use a field width of 5*/
printf("a = %*d\n", d, a); /* use a field width of 8 */
printf("\n");
printf("f = %f\n", f); /* simple float output */
printf("f = %12f\n", f); /* use field width of 12 */
printf("f = %12.3f\n", f); /* use 3 decimal places */
printf("f = %12.5f\n", f); /* use 5 decimal places */
printf("f = %-12.5f\n", f); /* left justify in field */
return 0;
}
程序执行后的结果将显示为:
A char is 1 bytes
An int is 2 bytes
A short is 2 bytes
A long is 4 bytes
An unsigned char is 1 bytes
An unsigned int is 2 bytes
An unsigned short is 2 bytes
An unsigned long is 4 bytes
A float is 4 bytes
A double is 8 bytes
a = 1023
a = 1777
a = 3ff
b = 2222
c = 123
d = 1234
e = X
f = 3.141590
g = 3.141593
a = 1023
a = 1023
a = 1023
a = 1023
a = 1023
f = 3.141590
f = 3.141590
f = 3.142
f = 3.14159
f = 3.14159 |
在使用 C 程序中的变量之前,必须先声明它。变量声明告诉编译器变量的名称和类型,并可选择将变量初始化为特定值。
如果您的程序尝试使用尚未声明的变量,编译器会生成错误消息。变量声明的形式如下:
类型名变量名;
typename 指定变量类型,必须是关键字之一。 varname 是变量名。您可以通过用逗号分隔变量名称在一行中声明多个相同类型的变量:
int count, number, start; /* three integer variables */
float percent, total; /* two float variables */
typedef 关键字
typedef 关键字用于为现有数据类型创建新名称。实际上, typedef 创建了一个同义词。例如,声明
typedef int 整数;
在这里我们看到 typedef 创建整数作为 int 的同义词。然后,您可以使用整数来定义 int 类型的变量,如下例所示:
整数个数;
因此 typedef 不会创建新的数据类型,它只允许您为预定义的数据类型使用不同的名称。
初始化数值变量
声明任何变量时,都会指示编译器为变量留出存储空间。但是,存储在该空间中的值,即变量的值,并没有定义。它可能是零,也可能是一些随机的“垃圾”。价值。在使用变量之前,您应该始终将其初始化为已知值。让我们举这个例子:
int count; /* Set aside storage space for count */
count = 0; /* Store 0 in count */
此语句使用等号 (=),它是 C 的赋值运算符。您还可以在声明变量时对其进行初始化。为此,请在声明语句中的变量名称后面加上等号和所需的初始值:
int count = 0;
double rate = 0.01, complexity = 28.5;
注意不要使用超出允许范围的值初始化变量。以下是超出范围初始化的两个示例:
int amount = 100000;
unsigned int length = -2500;
C 编译器不会捕获此类错误。您的程序可能会编译和链接,但您可能会在程序运行时得到意想不到的结果。
让我们以下面的例子来计算一个磁盘中的扇区总数:
// 计算磁盘扇区的模型程序 //
#include<stdio.h>
#define SECTOR_PER_SIDE 63
#define SIDE_PER_CYLINDER 254
void main()
{
int cylinder=0;
clrscr();
printf("Enter The No. of Cylinders in the Disk \n\n\t");
scanf("%d",&cylinder); // Get the value from the user //
printf("\n\n\t Total Number of Sectors in the disk = %ld", (long)SECTOR_PER_SIDE*SIDE_PER_CYLINDER* cylinder);
getch();
}
程序的输出如下:
输入磁盘中的圆柱数
1024
磁盘中的扇区总数 = 16386048
在这个例子中,我们看到了三个需要学习的新东西。 #define 用于在程序中使用符号常量,或者在某些情况下通过将长字定义为小符号来节省时间。
这里我们将每边 63 的扇区数定义为 SECTOR_PER_SIDE 以使程序易于理解。 #define SIDE_PER_CYLINDER 254 也是如此。scanf() 用于获取用户的输入。
这里我们将气缸数作为用户的输入。 * 用于将两个或多个值相乘,如示例所示。
getch() 函数基本上从键盘获取单个字符输入。通过键入 getch();在这里,我们停止屏幕,直到从键盘按下任何键。
运算符
运算符是指示 C 对一个或多个操作数执行某些操作或动作的符号。操作数是操作员作用的东西。在 C 中,所有操作数都是表达式。 C 运算符有以下四类:
赋值运算符
赋值运算符是等号 (=)。等号在编程中的使用不同于它在常规数学代数关系中的使用。如果你写
x = y;
在 C 程序中,它并不意味着“x 等于 y”。相反,它的意思是“将 y 的值分配给 x”。在 C 赋值语句中,右侧可以是任意表达式,左侧必须是变量名。因此,形式如下:
变量 = 表达式;
在执行期间,计算表达式,并将结果值分配给变量。
数学运算符
C 的数学运算符执行数学运算,例如加法和减法。 C 有两个一元数学运算符和五个二元数学运算符。一元数学运算符之所以如此命名,是因为它们采用单个操作数。 C 有两个一元数学运算符。
递增和递减运算符只能用于变量,不能用于常量。执行的操作是将操作数加一或减一。换句话说,语句 ++x;和--y;是这些语句的等价物:
x = x + 1;
y = y - 1;
二元数学运算符有两个操作数。前四个二元运算符,包括计算器上常见的数学运算(+、-、*、/),你很熟悉。当第一个操作数除以第二个操作数时,第五个运算符 Modulus 返回余数。例如,11 模数 4 等于 3(11 除以 4,乘以 2,剩下 3)。
关系运算符
C 的关系运算符用于比较表达式。包含关系运算符的表达式的计算结果为真 (1) 或假 (0)。 C 有六个关系运算符。
逻辑运算符
C 的逻辑运算符允许您将两个或多个关系表达式组合成一个表达式,该表达式的计算结果为真或假。逻辑运算符的计算结果为真或假,具体取决于其操作数的真假值。
如果 x 是整数变量,则使用逻辑运算符的表达式可以写成以下方式:
(x > 1) && (x < 5)
(x >= 2) && (x <= 4)
| Operator |
Symbol |
Description |
Example |
| Assignment operators |
| equal |
= |
assign the value of y to x |
x = y |
| Mathematical operators |
| Increment |
++ |
Increments the operand by one |
++x, x++ |
| Decrement |
-- |
Decrements the operand by one |
--x, x-- |
| Addition |
+ |
Adds two operands |
x + y |
| Subtraction |
- |
Subtracts the second operand from the first |
x - y |
| Multiplication |
* |
Multiplies two operands |
x * y |
| Division |
/ |
Divides the first operand by the second operand |
x / y |
| Modulus |
% |
Gives the remainder when the first operand is divided by the second operand |
x % y |
| Relational operators |
| Equal |
= = |
Equality |
x = = y |
| Greater than |
> |
Greater than |
x > y |
| Less than |
< |
Less than |
x < y |
| Greater than or equal to |
>= |
Greater than or equal to |
x >= y |
| Less than or equal to |
<= |
Less than or equal to |
x <= y |
| Not equal |
!= |
Not equal to |
x != y |
| Logical operators |
| AND |
&& |
True (1) only if both exp1 and exp2 are true; false (0) otherwise |
exp1 && exp2 |
| OR |
|| |
True (1) if either exp1 or exp2 is true; false (0) only if both are false |
exp1 || exp2 |
| NOT |
! |
False (0) if exp1 is true; true (1) if exp1 is false |
!exp1 |
关于逻辑表达式要记住的事情
| x * = y |
is same as |
x = x * y |
| y - = z + 1 |
is same as |
y = y - z + 1 |
| a / = b |
is same as |
a = a / b |
| x + = y / 8 |
is same as |
x = x + y / 8 |
| y % = 3 |
is same as |
y = y % 3 |
逗号运算符
逗号在 C 中经常用作简单的标点符号,用于分隔变量声明、函数参数等。在某些情况下,逗号充当运算符。
您可以通过用逗号分隔两个子表达式来形成一个表达式。结果如下:
- 计算两个表达式,首先计算左边的表达式。
- 整个表达式的计算结果为正确表达式的值。
例如, 以下语句将 b 的值分配给 x,然后递增 a,然后递增 b:
x = (a++, b++);
C 运算符优先级(C 运算符摘要)
| Rank and Associativity |
Operators |
| 1(left to right) |
() [] -> . |
| 2(right to left) |
! ~ ++ -- * (indirection) & (address-of) (type)
sizeof + (unary) - (unary) |
| 3(left to right) |
* (multiplication) / % |
| 4(left to right) |
+ - |
| 5(left to right) |
<< >> |
| 6(left to right) |
< <= > >= |
| 7(left to right) |
= = != |
| 8(left to right) |
& (bitwise AND) |
| 9(left to right) |
^ |
| 10(left to right) |
| |
| 11(left to right) |
&& |
| 12(left to right) |
|| |
| 13(right to left) |
?: |
| 14(right to left) |
= += -= *= /= %= &= ^= |= <<= >>= |
| 15(left to right) |
, |
| () is the function operator; [] is the array operator. |
|
让我们以运算符的使用为例:
/* 运算符的使用 */
int main()
{
int x = 0, y = 2, z = 1025;
float a = 0.0, b = 3.14159, c = -37.234;
/* incrementing */
x = x + 1; /* This increments x */
x++; /* This increments x */
++x; /* This increments x */
z = y++; /* z = 2, y = 3 */
z = ++y; /* z = 4, y = 4 */
/* decrementing */
y = y - 1; /* This decrements y */
y--; /* This decrements y */
--y; /* This decrements y */
y = 3;
z = y--; /* z = 3, y = 2 */
z = --y; /* z = 1, y = 1 */
/* arithmetic op */
a = a + 12; /* This adds 12 to a */
a += 12; /* This adds 12 more to a */
a *= 3.2; /* This multiplies a by 3.2 */
a -= b; /* This subtracts b from a */
a /= 10.0; /* This divides a by 10.0 */
/* conditional expression */
a = (b >= 3.0 ? 2.0 : 10.5 ); /* This expression */
if (b >= 3.0) /* And this expression */
a = 2.0; /* are identical, both */
else /* will cause the same */
a = 10.5; /* result. */
c = (a > b ? a : b); /* c will have the max of a or b */
c = (a > b ? b : a); /* c will have the min of a or b */
printf("x=%d, y=%d, z= %d\n", x, y, z);
printf("a=%f, b=%f, c= %f", a, b, c);
return 0;
}
该程序的结果将在屏幕上显示为:
x=3, y=1, z=1
a=2.000000, b=3.141590, c=2.000000
关于 printf() 和 Scanf() 的更多信息
考虑以下两个 printf 语句
printf(“\t %d\n”, num);
printf(“%5.2f”, 分数);
在第一个 printf 语句中 \t 请求屏幕上的制表符位移,参数 %d 告诉编译器 num 的值应该打印为十进制整数。 \n 导致新输出从新行开始。
在第二个 printf 语句中,%5.2f 告诉编译器输出必须是浮点数,总共有 5 位,小数点右边有 2 位。下表显示了有关反斜杠字符的更多信息:
| Constant |
Meaning |
| ‘\a’ |
Audible alert (bell) |
| ‘\b’ |
Backspace |
| ‘\f’ |
Form feed |
| ‘\n’ |
New line |
| ‘\r’ |
Carriage return |
| ‘\t’ |
Horizontal tab |
| ‘\v’ |
Vertical tab |
| ‘\’’ |
Single quote |
| ‘\”’ |
Double quote |
| ‘\?’ |
Question mark |
| ‘\\’ |
Backslash |
| ‘\0’ |
Null |
让我们考虑下面的 scanf 语句
scanf(“%d”, &num);
来自键盘的数据由scanf函数接收。在上述格式中,&每个变量名前的(和)符号是一个运算符,指定变量名的地址。
通过这样做,执行停止并等待输入变量 num 的值。当输入整数值并按下返回键时,计算机继续执行下一条语句。 scanf 和 printf 格式代码如下表所示:
| Code |
Reads... |
| %c |
Single character |
| %d |
Decimal integer |
| %e |
Floating point value |
| %f |
Floating point value |
| %g |
Floating point value |
| %h |
Short integer |
| %i |
Decimal, hexadecimal or octal integer |
| %o |
Octal integer |
| %s |
String |
| %u |
Unsigned decimal integer |
| %x |
Hexadecimal integer |
控制声明
一个程序由许多语句组成,这些语句通常按顺序执行。如果我们可以控制语句的运行顺序,程序会更加强大。
语句分为三种一般类型:
- 赋值,其中值(通常是计算结果)存储在变量中。
- 输入/输出,数据被读入或打印出来。
- 控制,程序决定下一步做什么。
本节将讨论 C 中控制语句的使用。我们将展示如何使用它们来编写功能强大的程序;
- 重复节目的重要部分。
- 在程序的可选部分之间进行选择。
if else 语句
这用于决定是在特殊点做某事,还是在两个行动方案之间做出决定。
以下测试决定学生是否通过考试,及格分数为 45
if (result >= 45)
printf("Pass\n");
else
printf("Fail\n");
It is possible to use the if part without the else.
if (temperature < 0)
print("Frozen\n");
每个版本都包含一个测试,位于 if 后面的括号语句中。如果测试为真,则遵循下一条语句。如果它是假的,那么如果存在,则遵循 else 之后的语句。在此之后,程序的其余部分将照常进行。
如果我们希望在 if 或 else 之后有多个语句,它们应该放在大括号之间。这样的分组称为复合语句或块。
if (result >= 45)
{ printf("Passed\n");
printf("Congratulations\n");
}
else
{ printf("Failed\n");
printf("Better Luck Next Time\n");
}
有时我们希望根据几个条件做出多方面的决定。最通用的方法是在 if 语句中使用 else if 变体。
这是通过级联几个比较来实现的。一旦其中一个给出了真实的结果,就会执行下面的语句或块,并且不会执行进一步的比较。在以下示例中,我们根据考试结果授予成绩。
if (result <=100 && result >= 75)
printf("Passed: Grade A\n");
else if (result >= 60)
printf("Passed: Grade B\n");
else if (result >= 45)
printf("Passed: Grade C\n");
else
printf("Failed\n");
在此示例中,所有比较都测试一个名为 result 的变量。在其他情况下,每个测试可能涉及不同的变量或某些测试组合。相同的模式可以与更多或更少的 else if 一起使用,并且最后一个 else 可能会被省略。
由程序员为每个编程问题设计正确的结构。为了更好地理解 if else 的用法,让我们看一下示例
#include <stdio.h>
int main()
{
int num;
for(num = 0 ; num < 10 ; num = num + 1)
{
if (num == 2)
printf("num is now equal to %d\n", num);
if (num < 5)
printf("num is now %d, which is less than 5\n", num);
else
printf("num is now %d, which is greater than 4\n", num);
} /* end of for loop */
return 0;
}
程序的结果
num is now 0, which is less than 5
num is now 1, which is less than 5
num is now equal to 2
num is now 2, which is less than 5
num is now 3, which is less than 5
num is now 4, which is less than 5
num is now 5, which is greater than 4
num is now 6, which is greater than 4
num is now 7, which is greater than 4
num is now 8, which is greater than 4
num is now 9, which is greater than 4
switch 语句
这是多路决策的另一种形式。它结构良好,但只能在某些情况下使用:
- 只测试一个变量,所有分支都必须依赖于该变量的值。变量必须是整数类型。 (int、long、short 或 char)。
- 变量的每个可能值都可以控制一个分支。一个最终的、包罗万象的、默认的分支可以选择性地用于捕获所有未指定的情况。
下面给出的示例将澄清事情。这是一个将整数转换为模糊描述的函数。当我们只关心测量非常小的数量时,它很有用。
estimate(number)
int number;
/* Estimate a number as none, one, two, several, many */
{ switch(number) {
case 0 :
printf("None\n");
break;
case 1 :
printf("One\n");
break;
case 2 :
printf("Two\n");
break;
case 3 :
case 4 :
case 5 :
printf("Several\n");
break;
default :
printf("Many\n");
break;
}
}
每个有趣的案例都列出了相应的操作。 break 语句通过离开 switch 来防止任何进一步的语句被执行。由于案例 3 和案例 4 没有后续中断,因此它们继续允许对多个数字值执行相同的操作。
if 和 switch 构造都允许程序员从许多可能的操作中进行选择。让我们看一个例子:
#include <stdio.h>
int main()
{
int num;
for (num = 3 ; num < 13 ; num = num + 1)
{
switch (num)
{
case 3 :
printf("The value is three\n");
break;
case 4 :
printf("The value is four\n");
break;
case 5 :
case 6 :
case 7 :
case 8 :
printf("The value is between 5 and 8\n");
break;
case 11 :
printf("The value is eleven\n");
break;
default :
printf("It is one of the undefined values\n");
break;
} /* end of switch */
} /* end of for loop */
return 0;
}
该程序的输出将是
The value is three
The value is four
The value is between 5 and 8
The value is between 5 and 8
The value is between 5 and 8
The value is between 5 and 8
It is one of the undefined values
It is one of the undefined values
The value is eleven
It is one of the undefined values
休息声明
我们在switch语句的讨论中已经遇到过break。它用于退出循环或开关,将控制权传递给循环或开关之外的第一条语句。
对于循环,break 可用于强制提前退出循环,或实现一个带有测试的循环,以便在循环体的中间退出。循环中的中断应始终在提供测试以控制退出条件的 if 语句中受到保护。
continue 语句
这与 break 类似,但遇到的频率较低。它只在循环中起作用,其效果是强制立即跳转到循环控制语句。
- 在 while 循环中,跳转到测试语句。
- 在 do while 循环中,跳转到测试语句。
- 在 for 循环中,跳转到测试并执行迭代。
和 break 一样,continue 应该受到 if 语句的保护。您不太可能经常使用它。为了更好地理解 break 的使用并继续,让我们检查以下程序:
#include <stdio.h>
int main()
{
int value;
for(value = 5 ; value < 15 ; value = value + 1)
{
if (value == 8)
break;
printf("In the break loop, value is now %d\n", value);
}
for(value = 5 ; value < 15 ; value = value + 1)
{
if (value == 8)
continue;
printf("In the continue loop, value is now %d\n", value);
}
return 0;
}
程序的输出如下:
In the break loop, value is now 5
In the break loop, value is now 6
In the break loop, value is now 7
In the continue loop, value is now 5
In the continue loop, value is now 6
In the continue loop, value is now 7
In the continue loop, value is now 9
In the continue loop, value is now 10
In the continue loop, value is now 11
In the continue loop, value is now 12
In the continue loop, value is now 13
In the continue loop, value is now 14
循环
另一种主要类型的控制语句是循环。循环允许重复语句或语句块。计算机非常擅长多次重复简单的任务。循环是 C 实现这一点的方式。
C 为您提供了三种循环类型的选择,while、do-while 和 for。
- while 循环不断重复一个动作,直到相关的测试返回 false。这在程序员事先不知道循环将被遍历多少次的情况下很有用。
- do while 循环类似,但测试发生在循环体执行之后。这可确保循环体至少运行一次。
- for 循环经常使用,通常循环会被遍历固定次数。它非常灵活,新手程序员应该注意不要滥用它提供的功能。
while 循环
while 循环重复一个语句,直到顶部的测试证明是错误的。例如,这是一个返回字符串长度的函数。请记住,字符串表示为以空字符“\0”结尾的字符数组。
int string_length(char string[])
{ int i = 0;
while (string[i] != '\0')
i++;
return(i);
}
字符串作为参数传递给函数。未指定数组的大小,该函数适用于任意大小的字符串。
while 循环用于一次查看字符串中的字符,直到找到空字符。然后退出循环,返回null的索引。
当字符不为空时,索引会增加并重复测试。稍后我们将深入探讨数组。让我们看一个while循环的例子:
#include <stdio.h>
int main()
{
int count;
count = 0;
while (count < 6)
{
printf("The value of count is %d\n", count);
count = count + 1;
}
return 0;
}
结果显示如下:
The value of count is 0
The value of count is 1
The value of count is 2
The value of count is 3
The value of count is 4
The value of count is 5
do while 循环
这与 while 循环非常相似,只是测试发生在循环体的末尾。这保证循环在继续之前至少执行一次。
这种设置经常用于要读取数据的地方。然后测试验证数据,如果不可接受,则循环返回以再次读取。
do
{
printf("Enter 1 for yes, 0 for no :");
scanf("%d", &input_value);
} while (input_value != 1 && input_value != 0)
To better understand the do while loop let us see the following example:
#include <stdio.h>
int main()
{
int i;
i = 0;
do
{
printf("The value of i is now %d\n", i);
i = i + 1;
} while (i < 5);
return 0;
}
程序的结果显示如下:
The value of i is now 0
The value of i is now 1
The value of i is now 2
The value of i is now 3
The value of i is now 4
for 循环
在进入循环之前知道循环的迭代次数的情况下,for 循环运行良好。循环的头部由分号分隔的三部分组成。
- 第一个在循环进入之前运行。这通常是循环变量的初始化。
- 第二个是测试,返回 false 时退出循环。
- 第三个是每次循环体完成时要运行的语句。这通常是循环计数器的增量。
该示例是一个计算存储在数组中的数字的平均值的函数。该函数将数组和元素的数量作为参数。
float average(float array[], int count)
{
float total = 0.0;
int i;
for(i = 0; i < count; i++)
total += array[i];
return(total / count);
}
for 循环确保在计算平均值之前将正确数量的数组元素相加。
for 循环头部的三个语句通常每个只做一件事,但是它们中的任何一个都可以留空。空白的第一个或最后一个语句将意味着没有初始化或运行增量。空白比较语句将始终被视为真。这将导致循环无限期地运行,除非被其他方式中断。这可能是 return 或 break 语句。
也可以将多个语句挤到第一个或第三个位置,用逗号分隔它们。这允许具有多个控制变量的循环。下面的例子说明了这样一个循环的定义,变量 hi 和 lo 分别从 100 和 0 开始并收敛。
for 循环提供了多种可以在其中使用的速记。注意下面的表达式,在这个表达式中,单个循环包含两个 for 循环。这里 hi-- 与 hi = hi - 1 相同,lo++ 与 lo = lo + 1 相同,
for(hi = 100, lo = 0; hi >= lo; hi--, lo++)
for 循环非常灵活,允许简单快速地指定多种类型的程序行为。让我们看一个for循环的例子
#include <stdio.h>
int main()
{
int index;
for(index = 0 ; index < 6 ; index = index + 1)
printf("The value of the index is %d\n", index);
return 0;
}
程序结果显示如下:
The value of the index is 0
The value of the index is 1
The value of the index is 2
The value of the index is 3
The value of the index is 4
The value of the index is 5
goto 语句
C 有一个 goto 语句,允许进行非结构化跳转。要使用 goto 语句,您只需使用保留字 goto 后跟要跳转到的符号名称。然后将该名称放在程序中的任何位置,后跟一个冒号。您几乎可以在函数内的任意位置跳转,但不允许跳入循环,但允许跳出循环。
这个特殊的程序确实是一团糟,但它很好地说明了为什么软件编写者试图尽可能地消除 goto 语句的使用。在这个程序中唯一合理使用 goto 的地方是,程序一次跳出三个嵌套循环的地方。在这种情况下,设置一个变量并连续跳出三个嵌套循环中的每一个会相当麻烦,但是一个 goto 语句可以非常简洁地让您跳出所有三个。
有人说在任何情况下都不应该使用 goto 语句,但这是狭隘的想法。如果在某个地方 goto 显然会比其他构造更简洁地执行控制流,那么请随意使用它,因为它在您的监视器上的程序的其余部分中。让我们看看这个例子:
#include <stdio.h>
int main()
{
int dog, cat, pig;
goto real_start;
some_where:
printf("This is another line of the mess.\n");
goto stop_it;
/* the following section is the only section with a useable goto */
real_start:
for(dog = 1 ; dog < 6 ; dog = dog + 1)
{
for(cat = 1 ; cat < 6 ; cat = cat + 1)
{
for(pig = 1 ; pig < 4 ; pig = pig + 1)
{
printf("Dog = %d Cat = %d Pig = %d\n", dog, cat, pig);
if ((dog + cat + pig) > 8 ) goto enough;
}
}
}
enough: printf("Those are enough animals for now.\n");
/* this is the end of the section with a useable goto statement */
printf("\nThis is the first line of the code.\n");
goto there;
where:
printf("This is the third line of the code.\n");
goto some_where;
there:
printf("This is the second line of the code.\n");
goto where;
stop_it:
printf("This is the last line of this mess.\n");
return 0;
}
让我们看看显示的结果
Dog = 1 Cat = 1 Pig = 1
Dog = 1 Cat = 1 Pig = 2
Dog = 1 Cat = 1 Pig = 3
Dog = 1 Cat = 2 Pig = 1
Dog = 1 Cat = 2 Pig = 2
Dog = 1 Cat = 2 Pig = 3
Dog = 1 Cat = 3 Pig = 1
Dog = 1 Cat = 3 Pig = 2
Dog = 1 Cat = 3 Pig = 3
Dog = 1 Cat = 4 Pig = 1
Dog = 1 Cat = 4 Pig = 2
Dog = 1 Cat = 4 Pig = 3
Dog = 1 Cat = 5 Pig = 1
Dog = 1 Cat = 5 Pig = 2
Dog = 1 Cat = 5 Pig = 3
Those are enough animals for now.
This is the first line of the code.
This is the second line of the code.
This is the third line of the code.
This is another line of the mess.
This is the last line of this mess.
指针
有时我们想知道变量在内存中的位置。 指针包含具有特定值的变量的地址。 声明指针时,在指针名称之前放置一个星号.
存储变量的内存位置的地址可以通过在变量名前面放置一个&符号来找到。
int num; /* Normal integer variable */
int *numPtr; /* Pointer to an integer variable */
下面的示例打印变量值和该变量在内存中的地址。
printf("The value %d is stored at address %X\n", num, &num);
要将变量 num 的地址分配给指针 numPtr,请分配变量 num 的地址,如下面的示例所示:
numPtr = #
要找出 numPtr 指向的地址存储的内容,需要取消引用该变量。取消引用是通过声明指针的星号实现的。
printf("值%d存储在地址%X\n", *numPtr, numPtr);
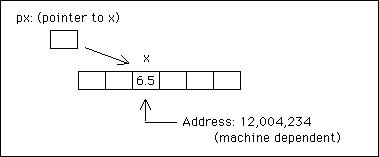
程序中的所有变量都驻留在内存中。下面给出的语句要求编译器在 32 位计算机上为浮点变量 x 保留 4 个字节的内存,然后将值 6.5 放入其中。
float x;
x = 6.5;
由于任何变量在内存中的地址位置都是通过放置运算符 &因此 &x 在它的名字之前是 x 的地址。 C 允许我们更进一步并定义一个变量,称为指针,其中包含其他变量的地址。相反,我们可以说指针指向其他变量。例如:
float x;
float* px;
x = 6.5;
px = &x;
将 px 定义为指向 float 类型对象的指针,并将其设置为等于 x 的地址。因此,*px 指的是 x 的值:
让我们检查以下陈述:
int var_x;
int* ptrX;
var_x = 6;
ptrX = &var_x;
*ptrX = 12;
printf("value of x : %d", var_x);
第一行使编译器在内存中为整数保留一个空间。第二行告诉编译器保留空间来存储指针。
指针是地址的存储位置。第三行应该提醒您 scanf 语句。地址“&”运算符告诉编译器去它存储var_x的地方,然后把存储位置的地址给ptrX。
变量前面的星号 * 告诉编译器取消引用指针,并进入内存。然后,您可以对存储在该位置的变量进行分配。您可以引用变量并通过指针访问其数据。让我们看一个指针的例子:
/* 指针使用说明 */
#include <stdio.h>
int main()
{
int index, *pt1, *pt2;
index = 39; /* any numerical value */
pt1 = &index; /* the address of index */
pt2 = pt1;
printf("The value is %d %d %d\n", index, *pt1, *pt2);
*pt1 = 13; /* this changes the value of index */
printf("The value is %d %d %d\n", index, *pt1, *pt2);
return 0;
}
程序的输出将显示如下:
The value is 39 39 39
The value is 13 13 13
让我们看另一个例子来更好地理解指针的使用:
#include <stdio.h>
#include <string.h>
int main()
{
char strg[40], *there, one, two;
int *pt, list[100], index;
strcpy(strg, "This is a character string.");
/* the function strcpy() is to copy one string to another. we’ll read about strcpy() function in String Section later */
one = strg[0]; /* one and two are identical */
two = *strg;
printf("The first output is %c %c\n", one, two);
one = strg[8]; /* one and two are identical */
two = *(strg+8);
printf("The second output is %c %c\n", one, two);
there = strg+10; /* strg+10 is identical to &strg[10] */
printf("The third output is %c\n", strg[10]);
printf("The fourth output is %c\n", *there);
for (index = 0 ; index < 100 ; index++)
list[index] = index + 100;
pt = list + 27;
printf("The fifth output is %d\n", list[27]);
printf("The sixth output is %d\n", *pt);
return 0;
}
程序的输出将是这样的:
The first output is T T
The second output is a a
The third output is c
The fourth output is c
The fifth output is 127
The sixth output is 127
数组
数组是相同类型变量的集合。 单个数组元素由整数索引标识。在 C 中,索引从零开始,并且总是写在方括号内。
我们已经遇到过这样声明的单维数组
int 结果[20];
数组可以有更多的维度,在这种情况下它们可能被声明为
int results_2d[20][5];
int results_3d[20][5][3];
每个索引都有自己的一组方括号。在 main 函数中声明了一个数组,通常包含维度的详细信息。可以使用另一种称为指针的类型来代替数组。这意味着尺寸不会立即固定,但可以根据需要分配空间。这是一种高级技术,仅在某些专业程序中需要。
举个例子,这里有一个简单的函数,可以将所有整数加起来为一维数组。
int add_array(int array[], int size)
{
int i;
int total = 0;
for(i = 0; i < size; i++)
total += array[i];
return(total);
}
接下来给出的程序将创建一个字符串,访问其中的一些数据,然后将其打印出来。使用指针再次访问它,然后将字符串打印出来。它应该打印“嗨!”和“012345678”在不同的行。让我们看一下程序的编码:
#include <stdio.h>
#define STR_LENGTH 10
void main()
{
char Str[STR_LENGTH];
char* pStr;
int i;
Str[0] = 'H';
Str[1] = 'i';
Str[2] = '!';
Str[3] = '\0'; // special end string character NULL
printf("The string in Str is : %s\n", Str);
pStr = &Str[0];
for (i = 0; i < STR_LENGTH; i++)
{
*pStr = '0'+i;
pStr++;
}
Str[STR_LENGTH-1] = '\0';
printf("The string in Str is : %s\n", Str);
}
[](方括号)用于声明数组。程序的行 char Str[STR_LENGTH];声明一个十个字符的数组。这是十个单独的字符,它们在记忆中都放在同一个地方。它们都可以通过我们的变量名 Str 以及 [n] 访问,其中 n 是元素编号。
在谈论数组时应始终牢记,当 C 声明一个 10 人的数组时,您可以访问的元素编号为 0 到 9。访问第一个元素对应于访问第 0 个元素。所以在数组的情况下,总是从 0 计数到数组的大小 - 1。
接下来注意我们把字母“Hi!”到数组中,但随后我们输入了一个 '\0' 你可能想知道这是什么。 “\0”代表NULL,代表字符串的结束。所有字符串都需要以这个特殊字符 '\0' 结尾。如果他们不这样做,然后有人在字符串上调用 printf,那么 printf 将从您的字符串的内存位置开始,并继续打印告诉它遇到 '\0',因此您最终会得到一堆垃圾你的字符串。因此,请确保正确终止您的字符串。
字符数组
字符串常量,如
“我是一个字符串”
是一个字符数组。它在 C 内部由字符串中的 ASCII 字符表示,即“I”、空白、“a”、“m”……或上述字符串,并以特殊的空字符“\0”终止,因此程序可以找到字符串的结尾。
字符串常量通常用于使用 printf 使代码输出易于理解:
printf("Hello, world\n");
printf("The value of a is: %f\n", a);
字符串常量可以与变量相关联。 C 提供了字符类型变量,一次可以包含一个字符(1 个字节)。字符串存储在字符类型数组中,每个位置一个 ASCII 字符。
永远不要忘记,由于字符串通常以空字符“\0”结尾,因此我们需要在数组中增加一个存储位置。
C 不提供任何一次操作整个字符串的运算符。字符串可以通过指针或标准字符串库 string.h 中可用的特殊例程进行操作。
使用字符指针相对容易,因为数组的名称只是指向其第一个元素的指针。考虑接下来给出的程序:
#include<stdio.h>
void main()
{
char text_1[100], text_2[100], text_3[100];
char *ta, *tb;
int i;
/* set message to be an arrray */
/* of characters; initialize it */
/* to the constant string "..." */
/* let the compiler decide on */
/* its size by using [] */
char message[] = "Hello, I am a string; what are
you?";
printf("Original message: %s\n", message);
/* copy the message to text_1 */
i=0;
while ( (text_1[i] = message[i]) != '\0' )
i++;
printf("Text_1: %s\n", text_1);
/* use explicit pointer arithmetic */
ta=message;
tb=text_2;
while ( ( *tb++ = *ta++ ) != '\0' )
;
printf("Text_2: %s\n", text_2);
}
程序的输出如下:
Original message: Hello, I am a string; what are you?
Text_1: Hello, I am a string; what are you?
Text_2: Hello, I am a string; what are you?
标准的“字符串”库包含许多有用的函数来操作字符串,我们将在后面的字符串部分学习。
访问元素
要访问数组中的单个元素,索引号跟在方括号中的变量名之后。然后可以像对待 C 中的任何其他变量一样对待该变量。以下示例将值分配给数组中的第一个元素。
x[0] = 16;
下面的示例打印数组中第三个元素的值。
printf("%d\n", x[2]);
下面的示例使用 scanf 函数将一个值从键盘读取到包含十个元素的数组的最后一个元素中。
scanf("%d", &x[9]);
初始化数组元素
数组可以像任何其他变量一样通过赋值来初始化。由于数组包含多个值,因此各个值放在大括号中,并用逗号分隔。下面的例子用三倍表的前十个值初始化一个十维数组。
int x[10] = {3, 6, 9, 12, 15, 18, 21, 24, 27, 30};
这样可以保存单独分配值,如下例所示。
int x[10];
x[0] = 3;
x[1] = 6;
x[2] = 9;
x[3] = 12;
x[4] = 15;
x[5] = 18;
x[6] = 21;
x[7] = 24;
x[8] = 27;
x[9] = 30;
遍历数组
由于数组是按顺序索引的,我们可以使用 for 循环来显示数组的所有值。以下示例显示数组的所有值:
#include <stdio.h>
int main()
{
int x[10];
int counter;
/* Randomise the random number generator */
srand((unsigned)time(NULL));
/* Assign random values to the variable */
for (counter=0; counter<10; counter++)
x[counter] = rand();
/* Display the contents of the array */
for (counter=0; counter<10; counter++)
printf("element %d has the value %d\n", counter, x[counter]);
return 0;
}
虽然输出每次都会打印不同的值,但结果将显示如下:
element 0 has the value 17132
element 1 has the value 24904
element 2 has the value 13466
element 3 has the value 3147
element 4 has the value 22006
element 5 has the value 10397
element 6 has the value 28114
element 7 has the value 19817
element 8 has the value 27430
element 9 has the value 22136
多维数组
一个数组可以有多个维度。通过允许数组具有多于一维提供了更大的灵活性。例如,电子表格建立在二维数组之上;行的数组,列的数组。
下面的例子使用了一个有两行的二维数组,每行包含五列:
#include <stdio.h>
int main()
{
/* Declare a 2 x 5 multidimensional array */
int x[2][5] = { {1, 2, 3, 4, 5},
{2, 4, 6, 8, 10} };
int row, column;
/* Display the rows */
for (row=0; row<2; row++)
{
/* Display the columns */
for (column=0; column<5; column++)
printf("%d\t", x[row][column]);
putchar('\n');
}
return 0;
}
该程序的输出将显示如下:
1 2 3 4 5
2 4 6 8 10
字符串
字符串是一组字符,通常是字母表中的字母,为了使您的打印显示格式看起来不错,具有有意义的名称和标题,并且在美学上让您和使用程序的输出。
事实上,您已经在前面主题的示例中使用了字符串。但这并不是字符串的完整介绍。编程中有很多可能的情况,格式化字符串的使用帮助程序员避免了程序中太多的复杂性,当然也避免了太多的bug。
字符串的完整定义是一系列以空字符('\0')结尾的字符类型数据。
当 C 打算以某种方式使用一个数据字符串时,将其与另一个字符串进行比较、输出、复制到另一个字符串或其他任何方式,这些函数被设置为执行它们被调用的操作直到检测到空值。
C 中没有字符串的基本数据类型,而是; C 中的字符串被实现为字符数组。例如,要存储名称,您可以声明一个足够大的字符数组来存储名称,然后使用适当的库函数来操作名称。
以下示例在屏幕上显示用户输入的字符串:
#include <stdio.h>
int main()
{
char name[80]; /* Create a character array
called name */
printf("Enter your name: ");
gets(name);
printf("The name you entered was %s\n", name);
return 0;
}
程序的执行将是:
输入您的姓名:Tarun Tyagi
您输入的名字是 Tarun Tyagi
一些常用的字符串函数
标准的 string.h 库包含许多有用的函数来操作字符串。此处举例说明了一些最有用的功能。
strlen 函数
strlen 函数用于确定字符串的长度。让我们通过示例学习 strlen 的使用:
#include <stdio.h>
#include <string.h>
int main()
{
char name[80];
int length;
printf("Enter your name: ");
gets(name);
length = strlen(name);
printf("Your name has %d characters\n", length);
return 0;
}
程序的执行如下:
Enter your name: Tarun Subhash Tyagi
Your name has 19 characters
Enter your name: Preeti Tarun
Your name has 12 characters
strcpy 函数
strcpy 函数用于将一个字符串复制到另一个字符串。让我们通过例子来学习这个函数的使用:
#include <stdio.h>
#include <string.h>
int main()
{
char first[80];
char second[80];
printf("Enter first string: ");
gets(first);
printf("Enter second string: ");
gets(second);
printf("first: %s, and second: %s Before strcpy()\n "
, first, second);
strcpy(second, first);
printf("first: %s, and second: %s After strcpy()\n",
first, second);
return 0;
}
程序的输出将是:
Enter first string: Tarun
Enter second string: Tyagi
first: Tarun, and second: Tyagi Before strcpy()
first: Tarun, and second: Tarun After strcpy()
strcmp 函数
strcmp 函数用于比较两个字符串。数组的变量名指向该数组的基地址。因此,如果我们尝试使用以下方式比较两个字符串,我们将比较两个地址,这显然永远不会相同,因为不可能将两个值存储在同一位置。
if (first == second) /* 永远无法比较字符串 */
以下示例使用 strcmp 函数比较两个字符串:
#include <string.h>
int main()
{
char first[80], second[80];
int t;
for(t=1;t<=2;t++)
{
printf("\nEnter a string: ");
gets(first);
printf("Enter another string: ");
gets(second);
if (strcmp(first, second) == 0)
puts("The two strings are equal");
else
puts("The two strings are not equal");
}
return 0;
}
程序的执行如下:
Enter a string: Tarun
Enter another string: tarun
The two strings are not equal
Enter a string: Tarun
Enter another string: Tarun
The two strings are equal
strcat 函数
strcat 函数用于将一个字符串连接到另一个字符串。让我们看看如何?借助示例:
#include <string.h>
int main()
{
char first[80], second[80];
printf("Enter a string: ");
gets(first);
printf("Enter another string: ");
gets(second);
strcat(first, second);
printf("The two strings joined together: %s\n",
first);
return 0;
}
程序的执行如下:
Enter a string: Data
Enter another string: Recovery
The two strings joined together: DataRecovery
strtok 函数
strtok 函数用于查找字符串中的下一个标记。标记由可能的分隔符列表指定。
以下示例从文件中读取一行文本,并使用分隔符、空格、制表符和换行符确定单词。然后每个单词显示在单独的行上:
#include <stdio.h>
#include <string.h>
int main()
{
FILE *in;
char line[80];
char *delimiters = " \t\n";
char *token;
if ((in = fopen("C:\\text.txt", "r")) == NULL)
{
puts("Unable to open the input file");
return 0;
}
/* Read each line one at a time */
while(!feof(in))
{
/* Get one line */
fgets(line, 80, in);
if (!feof(in))
{
/* Break the line up into words */
token = strtok(line, delimiters);
while (token != NULL)
{
puts(token);
/* Get the next word */
token = strtok(NULL, delimiters);
}
}
}
fclose(in);
return 0;
}
在上面的程序中,in = fopen("C:\\text.txt", "r"),打开现有文件 C:\\text.txt。如果指定路径中不存在或由于任何原因,文件无法打开,屏幕上会显示错误消息。
考虑以下示例,它使用了其中一些函数:
#include <stdio.h>
#include <string.h>
void main()
{
char line[100], *sub_text;
/* initialize string */
strcpy(line,"hello, I am a string;");
printf("Line: %s\n", line);
/* add to end of string */
strcat(line," what are you?");
printf("Line: %s\n", line);
/* find length of string */
/* strlen brings back */
/* length as type size_t */
printf("Length of line: %d\n", (int)strlen(line));
/* find occurence of substrings */
if ( (sub_text = strchr ( line, 'W' ) )!= NULL )
printf("String starting with \"W\" ->%s\n",
sub_text);
if ( ( sub_text = strchr ( line, 'w' ) )!= NULL )
printf("String starting with \"w\" ->%s\n",
sub_text);
if ( ( sub_text = strchr ( sub_text, 'u' ) )!= NULL )
printf("String starting with \"w\" ->%s\n",
sub_text);
}
程序的输出将显示如下:
Line: hello, I am a string;
Line: hello, I am a string; what are you?
Length of line: 35
String starting with "w" ->what are you?
String starting with "w" ->u?
函数
开发和维护大型程序的最佳方式是从更易于管理的较小部分构建它(这种技术有时称为分而治之)。函数允许程序员将程序模块化。
函数允许将复杂的程序打包成小块,每个小块都更易于编写、阅读和维护。我们已经遇到过 main 函数并使用了标准库中的 printf。我们当然可以制作自己的函数和头文件。函数具有以下布局:
return-type function-name ( argument list if necessary )
{
local-declarations;
statements ;
return return-value;
}
如果省略返回类型,C 默认为 int。返回值必须是声明的类型。在函数中声明的所有变量都称为局部变量,因为它们仅在定义它们的函数中是已知的。
一些函数有一个参数列表,提供函数和调用函数的模块之间的通信方法。参数也是局部变量,因为它们在函数之外不可用。到目前为止所涉及的程序都有main,这是一个函数。
一个函数可以简单地执行一项任务而不返回任何值,在这种情况下,它具有以下布局:
void function-name ( argument list if necessary )
{
local-declarations ;
statements;
}
在 C 函数调用中,参数总是按值传递。这意味着参数值的本地副本被传递给例程。对函数内部参数所做的任何更改仅对参数的本地副本进行。
为了更改或定义参数列表中的参数,该参数必须作为地址传递。如果函数不更改这些参数的值,则使用常规变量。如果函数更改这些参数的值,您必须使用指针。
让我们通过例子来学习:
#include <stdio.h>
void exchange ( int *a, int *b )
{
int temp;
temp = *a;
*a = *b;
*b = temp;
printf(" From function exchange: ");
printf("a = %d, b = %d\n", *a, *b);
}
void main()
{
int a, b;
a = 5;
b = 7;
printf("From main: a = %d, b = %d\n", a, b);
exchange(&a, &b);
printf("Back in main: ");
printf("a = %d, b = %d\n", a, b);
}
该程序的输出将显示如下:
From main: a = 5, b = 7
From function exchange: a = 7, b = 5
Back in main: a = 7, b = 5
让我们看另一个例子。下面的示例使用一个名为 square 的函数,它写入 1 到 10 之间数字的平方。
#include <stdio.h>
int square(int x); /* Function prototype */
int main()
{
int counter;
for (counter=1; counter<=10; counter++)
printf("Square of %d is %d\n", counter, square(counter));
return 0;
}
/* Define the function 'square' */
int square(int x)
{
return x * x;
}
该程序的输出将显示如下:
Square of 1 is 1
Square of 2 is 4
Square of 3 is 9
Square of 4 is 16
Square of 5 is 25
Square of 6 is 36
Square of 7 is 49
Square of 8 is 64
Square of 9 is 81
Square of 10 is 100
函数原型 square 声明了一个接受整数参数并返回整数的函数。当编译器在主程序中到达 square 的函数调用时,它能够根据函数的定义检查函数调用。
当程序到达调用函数 square 的行时,程序跳转到该函数并执行该函数,然后再继续通过主程序的路径。没有返回类型的程序应该使用 void 声明。因此,函数的参数可以是按值传递或按引用传递。
递归函数是调用自身的函数。而这个过程称为递归。
按值传递函数
上例中 square 函数的参数是按值传递的。这意味着只有变量的副本已传递给函数。对值的任何更改都不会反映回调用函数。
下面的例子使用了传值,改变了传入参数的值,对调用函数没有影响。由于没有返回类型,函数 count_down 已被声明为 void。
#include <stdio.h>
void count_down(int x);
int main()
{
int counter;
for (counter=1; counter<=10; counter++)
count_down(counter);
return 0;
}
void count_down(int x)
{
int counter;
for (counter = x; counter > 0; counter--)
{
printf("%d ", x);
x--;
}
putchar('\n');
}
程序的输出将显示如下:
1
2 1
3 2 1
4 3 2 1
5 4 3 2 1
6 5 4 3 2 1
7 6 5 4 3 2 1
8 7 6 5 4 3 2 1
9 8 7 6 5 4 3 2 1
10 9 8 7 6 5 4 3 2 1
让我们看另一个 C Pass By Value Example 以更好地理解它。以下示例将用户键入的介于 1 和 30,000 之间的数字转换为单词。
#include <stdio.h>
void do_units(int num);
void do_tens(int num);
void do_teens(int num);
int main()
{
int num, residue;
do
{
printf("Enter a number between 1 and 30,000: ");
scanf("%d", &num);
} while (num < 1 || num > 30000);
residue = num;
printf("%d in words = ", num);
do_tens(residue/1000);
if (num >= 1000)
printf("thousand ");
residue %= 1000;
do_units(residue/100);
if (residue >= 100)
{
printf("hundred ");
}
if (num > 100 && num%100 > 0)
printf("and ");
residue %=100;
do_tens(residue);
putchar('\n');
return 0;
}
void do_units(int num)
{
switch(num)
{
case 1:
printf("one ");
break;
case 2:
printf("two ");
break;
case 3:
printf("three ");
break;
case 4:
printf("four ");
break;
case 5:
printf("five ");
break;
case 6:
printf("six ");
break;
case 7:
printf("seven ");
break;
case 8:
printf("eight ");
break;
case 9:
printf("nine ");
}
}
void do_tens(int num)
{
switch(num/10)
{
case 1:
do_teens(num);
break;
case 2:
printf("twenty ");
break;
case 3:
printf("thirty ");
break;
case 4:
printf("forty ");
break;
case 5:
printf("fifty ");
break;
case 6:
printf("sixty ");
break;
case 7:
printf("seventy ");
break;
case 8:
printf("eighty ");
break;
case 9:
printf("ninety ");
}
if (num/10 != 1)
do_units(num%10);
}
void do_teens(int num)
{
switch(num)
{
case 10:
printf("ten ");
break;
case 11:
printf("eleven ");
break;
case 12:
printf("twelve ");
break;
case 13:
printf("thirteen ");
break;
case 14:
printf("fourteen ");
break;
case 15:
printf("fifteen ");
break;
case 16:
printf("sixteen ");
break;
case 17:
printf("seventeen ");
break;
case 18:
printf("eighteen ");
break;
case 19:
printf("nineteen ");
}
}
程序的输出如下:
Enter a number between 1 and 30,000: 12345
12345 in words = twelve thousand three hundred and forty five
引用调用
要通过引用调用函数,而不是传递变量本身,而是传递变量的地址。变量的地址可以使用 &操作员。下面调用一个交换函数,传递变量的地址而不是实际值。
swap(&x, &y);
取消引用
我们现在遇到的问题是函数 swap 传递的是地址而不是变量,所以我们需要取消引用变量,以便我们查看实际值而不是变量的地址以便交换他们。
在 C 中通过使用指针 (*) 表示法来实现解引用。简单来说,这意味着在使用每个变量之前在每个变量之前放置一个 *,以便它引用变量的值而不是其地址。下面的程序说明了通过引用传递交换两个值。
#include <stdio.h>
void swap(int *x, int *y);
int main()
{
int x=6, y=10;
printf("Before the function swap, x = %d and y =
%d\n\n", x, y);
swap(&x, &y);
printf("After the function swap, x = %d and y =
%d\n\n", x, y);
return 0;
}
void swap(int *x, int *y)
{
int temp = *x;
*x = *y;
*y = temp;
}
让我们看看程序的输出:
Before the function swap, x = 6 and y = 10
After the function swap, x = 10 and y = 6
函数可能是递归的,即函数可以调用自身。对自身的每次调用都要求将函数的当前状态压入堆栈。记住这一点很重要,因为很容易造成堆栈溢出,即堆栈已用完空间来放置更多数据。
以下示例使用递归计算数字的阶乘。阶乘是一个数字乘以它自身以下的所有其他整数,直到 1。例如,数字 6 的阶乘是:
阶乘 6 = 6 * 5 * 4 * 3 * 2 * 1
所以 6 的阶乘是 720。从上面的例子可以看出阶乘 6 = 6 * 阶乘 5。同理,阶乘 5 = 5 * 阶乘 4,以此类推。
以下是计算阶乘数的一般规则。
阶乘(n) = n * 阶乘(n-1)
上面的规则在 n = 1 时终止,因为 1 的阶乘是 1。让我们通过示例来更好地理解它:
#include <stdio.h>
long int factorial(int num);
int main()
{
int num;
long int f;
printf("Enter a number: ");
scanf("%d", &num);
f = factorial(num);
printf("factorial of %d is %ld\n", num, f);
return 0;
}
long int factorial(int num)
{
if (num == 1)
return 1;
else
return num * factorial(num-1);
}
让我们看看这个程序的执行输出:
Enter a number: 7
factorial of 7 is 5040
C中的内存分配
C 编译器有一个内存分配库,在 malloc.h 中定义。使用 malloc 函数保留内存,并返回指向地址的指针。它有一个参数,需要的内存大小,以字节为单位。
以下示例为字符串“hello world”分配空间。
ptr = (char *)malloc(strlen("Hello world") + 1);
额外的一个字节需要考虑到字符串终止字符'\0'。 (char *) 称为强制转换,并强制返回类型为 char *。
由于数据类型具有不同的大小,并且 malloc 以字节为单位返回空间,因此在指定要分配的大小时使用 sizeof 运算符是一种很好的做法。
以下示例将字符串读入字符数组缓冲区,然后分配所需的确切内存量并将其复制到名为“ptr”的变量中。
#include <string.h>
#include <malloc.h>
int main()
{
char *ptr, buffer[80];
printf("Enter a string: ");
gets(buffer);
ptr = (char *)malloc((strlen(buffer) + 1) *
sizeof(char));
strcpy(ptr, buffer);
printf("You entered: %s\n", ptr);
return 0;
}
程序的输出如下:
Enter a string: India is the best
You entered: India is the best
重新分配内存
在您进行编程时,您可能多次想要重新分配内存。这是通过 realloc 函数完成的。 realloc 函数有两个参数,你想要调整大小的内存的基地址,以及你想要保留的空间量,并返回一个指向基地址的指针。
假设我们为一个名为 msg 的指针保留了空间,并且我们想将空间重新分配为它已经占用的空间量,再加上另一个字符串的长度,那么我们可以使用以下内容。
msg = (char *)realloc(msg, (strlen(msg) + strlen(buffer) + 1)*sizeof(char));
以下程序说明了 malloc、realloc 和 free 的使用。用户输入一系列连接在一起的字符串。当输入一个空字符串时,程序停止读取字符串。
#include <string.h>
#include <malloc.h>
int main()
{
char buffer[80], *msg;
int firstTime=0;
do
{
printf("\nEnter a sentence: ");
gets(buffer);
if (!firstTime)
{
msg = (char *)malloc((strlen(buffer) + 1) *
sizeof(char));
strcpy(msg, buffer);
firstTime = 1;
}
else
{
msg = (char *)realloc(msg, (strlen(msg) +
strlen(buffer) + 1) * sizeof(char));
strcat(msg, buffer);
}
puts(msg);
} while(strcmp(buffer, ""));
free(msg);
return 0;
}
程序的输出如下:
Enter a sentence: Once upon a time
Once upon a time
Enter a sentence: there was a king
Once upon a timethere was a king
Enter a sentence: the king was
Once upon a timethere was a kingthe king was
Enter a sentence:
Once upon a timethere was a kingthe king was
释放内存
分配完内存后,千万不要忘记释放内存,因为它会释放资源并提高速度。要释放分配的内存,请使用 free 函数。
免费(ptr);
结构
除了基本数据类型外,C 还具有一种结构机制,允许您将彼此相关的数据项分组到一个通用名称下。这通常称为用户定义类型。
关键字 struct 开始结构定义,标签赋予结构唯一的名称。添加到结构中的数据类型和变量名称是结构的成员。结果是可以用作类型说明符的结构模板。以下是带有月份标签的结构。
struct month
{
char name[10];
char abbrev[4];
int days;
};
结构类型通常使用 typedef 语句在文件开头附近定义。 typedef 定义并命名一个新类型,允许在整个程序中使用它。 typedef 通常出现在文件中的 #define 和 #include 语句之后。
typedef 关键字可以用来定义一个词来引用结构,而不是用结构名称来指定 struct 关键字。通常以大写字母命名 typedef。以下是结构定义的示例。
typedef struct {
char name[64];
char course[128];
int age;
int year;
} student; 这定义了一个新类型的student变量,student类型的变量可以声明如下。
student st_rec;
请注意这与声明 int 或 float 有多么相似。变量名称是 st_rec,它有名为 name、course、age 和 year 的成员。相似地,
typedef struct element
{
char data;
struct element *next;
} STACKELEMENT;
A variable of the user defined type struct element may now be declared as follows.
STACKELEMENT *stack;
考虑以下结构:
struct student
{
char *name;
int grade;
};
指向 struct student 的指针可以定义如下。
struct student *hnc;
When accessing a pointer to a structure, the member pointer operator, -> is used instead of the dot operator. To add a grade to a structure,
s.grade = 50;
您可以按如下方式为结构分配等级。
s->grade = 50;
与基本数据类型一样,如果您希望函数中对传递参数所做的更改是持久的,则必须通过引用传递(传递地址)。该机制与基本数据类型完全相同。传递地址,并使用指针表示法引用变量。
定义结构后,您可以声明它的一个实例并使用点符号为成员分配值。以下示例说明了月份结构的使用。
#include <stdio.h>
#include <string.h>
struct month
{
char name[10];
char abbreviation[4];
int days;
};
int main()
{
struct month m;
strcpy(m.name, "January");
strcpy(m.abbreviation, "Jan");
m.days = 31;
printf("%s is abbreviated as %s and has %d days\n", m.name, m.abbreviation, m.days);
return 0;
}
程序的输出如下:
一月简写为一月,有31天
所有 ANSI C 编译器都允许您将一个结构分配给另一个结构,执行逐个成员的复制。如果我们有称为 m1 和 m2 的月份结构,那么我们可以将 m1 的值分配给 m2,如下所示:
- 带有指针成员的结构。
- 结构初始化。
- 将结构传递给函数。
- 指针和结构。
C语言中带有指针成员的结构
在固定大小的数组中保存字符串是对内存的低效使用。更有效的方法是使用指针。指针在结构中的使用方式与它们在普通指针定义中的使用方式完全相同。让我们看一个例子:
#include <string.h>
#include <malloc.h>
struct month
{
char *name;
char *abbreviation;
int days;
};
int main()
{
struct month m;
m.name = (char *)malloc((strlen("January")+1) *
sizeof(char));
strcpy(m.name, "January");
m.abbreviation = (char *)malloc((strlen("Jan")+1) *
sizeof(char));
strcpy(m.abbreviation, "Jan");
m.days = 31;
printf("%s is abbreviated as %s and has %d days\n",
m.name, m.abbreviation, m.days);
return 0;
}
程序的输出如下:
一月缩写为一月,有31天
C中的结构初始化器
要为结构提供一组初始值,可以将 Initialisers 添加到声明语句中。由于月份从 1 开始,但 C 中的数组从零开始,因此在以下示例中使用了位于零位置的额外元素,称为垃圾。
#include <stdio.h>
#include <string.h>
struct month
{
char *name;
char *abbreviation;
int days;
} month_details[] =
{
"Junk", "Junk", 0,
"January", "Jan", 31,
"February", "Feb", 28,
"March", "Mar", 31,
"April", "Apr", 30,
"May", "May", 31,
"June", "Jun", 30,
"July", "Jul", 31,
"August", "Aug", 31,
"September", "Sep", 30,
"October", "Oct", 31,
"November", "Nov", 30,
"December", "Dec", 31
};
int main()
{
int counter;
for (counter=1; counter<=12; counter++)
printf("%s is abbreviated as %s and has %d days\n",
month_details[counter].name,
month_details[counter].abbreviation,
month_details[counter].days);
return 0;
}
输出将显示如下:
January is abbreviated as Jan and has 31 days
February is abbreviated as Feb and has 28 days
March is abbreviated as Mar and has 31 days
April is abbreviated as Apr and has 30 days
May is abbreviated as May and has 31 days
June is abbreviated as Jun and has 30 days
July is abbreviated as Jul and has 31 days
August is abbreviated as Aug and has 31 days
September is abbreviated as Sep and has 30 days
October is abbreviated as Oct and has 31 days
November is abbreviated as Nov and has 30 days
December is abbreviated as Dec and has 31 days
将结构传递给 C 中的函数
结构可以作为参数传递给函数,就像任何基本数据类型一样。以下示例使用了一个名为 date 的结构,该结构已传递给 isLeapYear 函数来确定年份是否为闰年。
通常您只会传递日期值,但传递整个结构是为了说明将结构传递给函数。
#include <stdio.h>
#include <string.h>
struct month
{
char *name;
char *abbreviation;
int days;
} month_details[] =
{
"Junk", "Junk", 0,
"January", "Jan", 31,
"February", "Feb", 28,
"March", "Mar", 31,
"April", "Apr", 30,
"May", "May", 31,
"June", "Jun", 30,
"July", "Jul", 31,
"August", "Aug", 31,
"September", "Sep", 30,
"October", "Oct", 31,
"November", "Nov", 30,
"December", "Dec", 31
};
struct date
{
int day;
int month;
int year;
};
int isLeapYear(struct date d);
int main()
{
struct date d;
printf("Enter the date (eg: 11/11/1980): ");
scanf("%d/%d/%d", &d.day, &d.month, &d.year);
printf("The date %d %s %d is ", d.day,
month_details[d.month].name, d.year);
if (isLeapYear(d) == 0)
printf("not ");
puts("a leap year");
return 0;
}
int isLeapYear(struct date d)
{
if ((d.year % 4 == 0 && d.year % 100 != 0) ||
d.year % 400 == 0)
return 1;
return 0;
}
程序的执行如下:
Enter the date (eg: 11/11/1980): 9/12/1980
1980 年 12 月 9 日是闰年
以下示例动态分配结构数组来存储学生姓名和成绩。然后以升序将成绩显示回给用户。
#include <string.h>
#include <malloc.h>
struct student
{
char *name;
int grade;
};
void swap(struct student *x, struct student *y);
int main()
{
struct student *group;
char buffer[80];
int spurious;
int inner, outer;
int counter, numStudents;
printf("How many students are there in the group: ");
scanf("%d", &numStudents);
group = (struct student *)malloc(numStudents *
sizeof(struct student));
for (counter=0; counter<numStudents; counter++)
{
spurious = getchar();
printf("Enter the name of the student: ");
gets(buffer);
group[counter].name = (char *)malloc((strlen(buffer)+1) * sizeof(char));
strcpy(group[counter].name, buffer);
printf("Enter grade: ");
scanf("%d", &group[counter].grade);
}
for (outer=0; outer<numStudents; outer++)
for (inner=0; inner<outer; inner++)
if (group[outer].grade <
group[inner].grade)
swap(&group[outer], &group[inner]);
puts("The group in ascending order of grades ...");
for (counter=0; counter<numStudents; counter++)
printf("%s achieved Grade %d \n”,
group[counter].name,
group[counter].grade);
return 0;
}
void swap(struct student *x, struct student *y)
{
struct student temp;
temp.name = (char *)malloc((strlen(x->name)+1) *
sizeof(char));
strcpy(temp.name, x->name);
temp.grade = x->grade;
x->grade = y->grade;
x->name = (char *)malloc((strlen(y->name)+1) *
sizeof(char));
strcpy(x->name, y->name);
y->grade = temp.grade;
y->name = (char *)malloc((strlen(temp.name)+1) *
sizeof(char));
strcpy(y->name, temp.name);
}
输出的执行将如下:
How many students are there in the group: 4
Enter the name of the student: Anuraaj
Enter grade: 7
Enter the name of the student: Honey
Enter grade: 2
Enter the name of the student: Meetushi
Enter grade: 1
Enter the name of the student: Deepti
Enter grade: 4
The group in ascending order of grades ...
Meetushi achieved Grade 1
Honey achieved Grade 2
Deepti achieved Grade 4
Anuraaj achieved Grade 7
联合
联合允许您查看具有不同类型的相同数据,或使用具有不同名称的相同数据。联合类似于结构。联合的声明和使用方式与结构相同。
联合与结构的不同之处在于,一次只能使用一个成员。这样做的原因是简单的。一个联合的所有成员都占用相同的内存区域。它们相互叠放。
联合的定义和声明方式与结构相同。声明中的唯一区别是使用关键字 union 而不是 struct。要定义一个 char 变量和一个整数变量的简单联合,您可以编写以下代码:
union shared {
char c;
int i;
};
这个联合,共享,可用于创建联合的实例,该联合实例可以保存字符值 c 或整数值 i。这是一个 OR 条件。与同时保存两个值的结构不同,联合一次只能保存一个值。
一个联合可以在它的声明中被初始化。因为一次只能使用一个成员,并且只能初始化一个。为避免混淆,只能初始化联合的第一个成员。以下代码显示了正在声明和初始化的共享联合的实例:
union shared generic_variable = {`@'};
请注意,generic_variable 联合的初始化就像初始化结构的第一个成员一样。
单个联合成员的使用方式与使用成员运算符 (.) 使用结构成员的方式相同。但是,访问工会成员有一个重要的区别。
一次只能访问一个联合成员。由于联合将其成员存储在彼此之上,因此一次只能访问一个成员很重要。
联合关键字
union tag {
union_member(s);
/* additional statements may go here */
}instance;
union 关键字用于声明联合。联合是一个或多个变量 (union_members) 的集合,这些变量已分组在一个名称下。此外,这些联合成员中的每一个都占用相同的内存区域。
关键字 union 标识联合定义的开始。其后跟一个标签,该标签是赋予联合体的名称。标签后面是大括号中的联合成员。
一个实例,一个联合的实际声明,也可以被定义。如果您在没有实例的情况下定义结构,它只是一个模板,稍后可以在程序中用于声明结构。以下是模板的格式:
union tag {
union_member(s);
/* additional statements may go here */
};
要使用模板,您将使用以下格式:
联合标签实例;
要使用这种格式,您必须事先声明一个带有给定标签的联合。
/* 声明一个名为 tag 的联合模板 */
union tag {
int num;
char alps;
}
/* Use the union template */
union tag mixed_variable;
/* Declare a union and instance together */
union generic_type_tag {
char c;
int i;
float f;
double d;
} generic;
/* Initialize a union. */
union date_tag {
char full_date[9];
struct part_date_tag {
char month[2];
char break_value1;
char day[2];
char break_value2;
char year[2];
} part_date;
}date = {"09/12/80"};
让我们借助示例更好地理解它:
#include <stdio.h>
int main()
{
union
{
int value; /* This is the first part of the union */
struct
{
char first; /* These two values are the second part of it */
char second;
} half;
} number;
long index;
for (index = 12 ; index < 300000L ; index += 35231L)
{
number.value = index;
printf("%8x %6x %6x\n", number.value,
number.half.first,
number.half.second);
}
return 0;
}
程序的输出将显示如下:
c c 0
89ab ffab ff89
134a 4a 13
9ce9 ffe9 ff9c
2688 ff88 26
b027 27 ffb0
39c6 ffc6 39
c365 65 ffc3
4d04 4 4d
联合在数据恢复中的实际应用
现在让我们看看联合的一个实际用途是数据恢复编程。让我们举个小例子。以下程序是用于软盘驱动器(a:)的坏扇区扫描程序的小模型,但它不是坏扇区扫描软件的完整模型。
让我们检查一下程序:
#include<dos.h>
#include<conio.h>
int main()
{
int rp, head, track, sector, status;
char *buf;
union REGS in, out;
struct SREGS s;
clrscr();
/* Reset the disk system to initialize to disk */
printf("\n Resetting the disk system....");
for(rp=0;rp<=2;rp++)
{
in.h.ah = 0;
in.h.dl = 0x00;
int86(0x13,&in,&out);
}
printf("\n\n\n Now Testing the Disk for Bad Sectors....");
/* scan for bad sectors */
for(track=0;track<=79;track++)
{
for(head=0;head<=1;head++)
{
for(sector=1;sector<=18;sector++)
{
in.h.ah = 0x04;
in.h.al = 1;
in.h.dl = 0x00;
in.h.ch = track;
in.h.dh = head;
in.h.cl = sector;
in.x.bx = FP_OFF(buf);
s.es = FP_SEG(buf);
int86x(0x13,&in,&out,&s);
if(out.x.cflag)
{
status=out.h.ah;
printf("\n track:%d Head:%d Sector:%d Status ==0x%X",track,head,sector,status);
}
}
}
}
printf("\n\n\nDone");
return 0;
}
现在让我们看看如果软盘中有坏扇区,它的输出会是什么样子:
正在重置磁盘系统....
现在测试磁盘是否有坏扇区....
track:0 Head:0 Sector:4 Status ==0xA
track:0 Head:0 Sector:5 Status ==0xA
track:1 Head:0 Sector:4 Status ==0xA
track:1 Head:0 Sector:5 Status ==0xA
track:1 Head:0 Sector:6 Status ==0xA
track:1 Head:0 Sector:7 Status ==0xA
track:1 Head:0 Sector:8 Status ==0xA
track:1 Head:0 Sector:11 Status ==0xA
track:1 Head:0 Sector:12 Status ==0xA
track:1 Head:0 Sector:13 Status ==0xA
track:1 Head:0 Sector:14 Status ==0xA
track:1 Head:0 Sector:15 Status ==0xA
track:1 Head:0 Sector:16 Status ==0xA
track:1 Head:0 Sector:17 Status ==0xA
track:1 Head:0 Sector:18 Status ==0xA
track:1 Head:1 Sector:5 Status ==0xA
track:1 Head:1 Sector:6 Status ==0xA
track:1 Head:1 Sector:7 Status ==0xA
track:1 Head:1 Sector:8 Status ==0xA
track:1 Head:1 Sector:9 Status ==0xA
track:1 Head:1 Sector:10 Status ==0xA
track:1 Head:1 Sector:11 Status ==0xA
track:1 Head:1 Sector:12 Status ==0xA
track:1 Head:1 Sector:13 Status ==0xA
track:1 Head:1 Sector:14 Status ==0xA
track:1 Head:1 Sector:15 Status ==0xA
track:1 Head:1 Sector:16 Status ==0xA
track:1 Head:1 Sector:17 Status ==0xA
track:1 Head:1 Sector:18 Status ==0xA
track:2 Head:0 Sector:4 Status ==0xA
track:2 Head:0 Sector:5 Status ==0xA
track:14 Head:0 Sector:6 Status ==0xA
Done
可能有点难以理解这个程序中使用的函数和中断来验证磁盘的坏扇区和重置磁盘系统等,但你不用担心,我们将在 BIOS 和中断编程中学习所有这些东西在接下来的章节中稍后部分。
C中的文件处理
C 中的文件访问是通过将流与文件相关联来实现的。 C 使用称为文件指针的新数据类型与文件通信。此类型在 stdio.h 中定义,并写为 FILE *。名为 output_file 的文件指针在如下语句中声明
FILE *output_file;
fopen函数的文件模式
您的程序必须先打开一个文件才能访问它。这是使用 fopen 函数完成的,该函数返回所需的文件指针。如果由于任何原因无法打开文件,则将返回 NULL 值。您通常会按如下方式使用 fopen
if ((output_file = fopen("output_file", "w")) == NULL)
fprintf(stderr, "Cannot open %s\n",
"output_file");
fopen 接受两个参数,都是字符串,第一个是要打开的文件的名称,第二个是访问字符,通常是 r、a 或 w 等。文件可以以多种模式打开,如下表所示。
| File Modes |
| r |
Open a text file for reading. |
| w |
Create a text file for writing. If the file exists, it is overwritten. |
| a |
Open a text file in append mode. Text is added to the end of the file. |
| rb |
Open a binary file for reading. |
| wb |
Create a binary file for writing. If the file exists, it is overwritten. |
| ab |
Open a binary file in append mode. Data is added to the end of the file. |
| r+ |
Open a text file for reading and writing. |
| w+ |
Create a text file for reading and writing. If the file exists, it is overwritten. |
| a+ |
Open a text file for reading and writing at the end. |
| r+b or rb+ |
Open binary file for reading and writing. |
| w+b or wb+ |
Create a binary file for reading and writing. If the file exists, it is overwritten. |
| a+b or ab+ |
Open a text file for reading and writing at the end. |
更新模式与 fseek、fsetpos 和 rewind 函数一起使用。 fopen 函数返回一个文件指针,如果发生错误则返回 NULL。
以下示例以只读模式打开文件 tarun.txt。测试文件是否存在是一种很好的编程习惯。
if ((in = fopen("tarun.txt", "r")) == NULL)
{
puts("Unable to open the file");
return 0;
}
关闭文件
使用 fclose 函数关闭文件。语法如下:
fclose(in);
读取文件
feof 函数用于测试文件是否结束。 fgetc、fscanf 和 fgets 函数用于从文件中读取数据。
以下示例在屏幕上列出文件的内容,使用 fgetc 一次读取文件一个字符。
#include <stdio.h>
int main()
{
FILE *in;
int key;
if ((in = fopen("tarun.txt", "r")) == NULL)
{
puts("Unable to open the file");
return 0;
}
while (!feof(in))
{
key = fgetc(in);
/* The last character read is the end of file marker so don't print it */
if (!feof(in))
putchar(key);
}
fclose(in);
return 0;
}
fscanf 函数可用于从文件中读取不同的数据类型,如下例所示,前提是文件中的数据采用 fscanf 使用的格式字符串的格式。
fscanf(in, "%d/%d/%d", &day, &month, &year);
fgets 函数用于从文件中读取多个字符。 stdin 是标准输入文件流,可以使用 fgets 函数来控制输入。
写入文件
可以使用 fputc 和 fprintf 将数据写入文件。以下示例使用 fgetc 和 fputc 函数来制作文本文件的副本。
#include <stdio.h>
int main()
{
FILE *in, *out;
int key;
if ((in = fopen("tarun.txt", "r")) == NULL)
{
puts("Unable to open the file");
return 0;
}
out = fopen("copy.txt", "w");
while (!feof(in))
{
key = fgetc(in);
if (!feof(in))
fputc(key, out);
}
fclose(in);
fclose(out);
return 0;
}
fprintf 函数可用于将格式化数据写入文件。
fprintf(out, "Date: %02d/%02d/%02d\n",
day, month, year);
使用 C 的命令行参数
用于声明 main( ) 函数的 ANSI C 定义是:
int main() or int main(int argc, char **argv)
第二个版本允许从命令行传递参数。参数 argc 是一个参数计数器,包含从命令行传递的参数数量。参数 argv 是参数向量,它是一个指向字符串的指针数组,表示传递的实际参数。
以下示例允许从命令行传递任意数量的参数并将它们打印出来。 argv[0] 是实际程序。该程序必须从命令提示符运行。
#include <stdio.h>
int main(int argc, char **argv)
{
int counter;
puts("The arguments to the program are:");
for (counter=0; counter<argc; counter++)
puts(argv[counter]);
return 0;
}
If the program name was count.c, it could be called as follows from the command line.
count 3
or
count 7
or
count 192 etc.
下一个示例使用文件处理例程将文本文件复制到新文件。例如,命令行参数可以调用为:
txtcpy one.txt two.txt
#include <stdio.h>
int main(int argc, char **argv)
{
FILE *in, *out;
int key;
if (argc < 3)
{
puts("Usage: txtcpy source destination\n");
puts("The source must be an existing file");
puts("If the destination file exists, it will be
overwritten");
return 0;
}
if ((in = fopen(argv[1], "r")) == NULL)
{
puts("Unable to open the file to be copied");
return 0;
}
if ((out = fopen(argv[2], "w")) == NULL)
{
puts("Unable to open the output file");
return 0;
}
while (!feof(in))
{
key = fgetc(in);
if (!feof(in))
fputc(key, out);
}
fclose(in);
fclose(out);
return 0;
}
位操作符
在硬件级别,数据表示为二进制数。数字 59 的二进制表示为 111011。第 0 位是最低有效位,在这种情况下第 5 位是最高有效位。
每个位集的计算为 2 的位集的幂。位运算符允许您在位级别操作整数变量。下面显示了数字 59 的二进制表示。
| binary representation of the number 59 |
| bit 5 4 3 2 1 0 |
| 2 power n 32 16 8 4 2 1 |
| set 1 1 1 0 1 1 |
用三位可以表示数字 0 到 7。下表显示了数字 0 到 7 的二进制形式。
| Binary Digits |
| 000 |
0 |
| 001 |
1 |
| 010 |
2 |
| 011 |
3 |
| 100 |
4 |
| 101 |
5 |
| 110 |
6 |
| 111 |
7 |
下表列出了可用于操作二进制数的位运算符。
| Binary Digits |
| & |
Bitwise AND |
| | |
Bitwise OR |
| ^ |
Bitwise Exclusive OR |
| ~ |
Bitwise Complement |
| << |
Bitwise Shift Left |
| >> |
Bitwise Shift Right |
按位与
仅当两个位都设置时,按位与为真。以下示例显示了数字 23 和 12 的按位与结果。
| 10111 (23)
01100 (12) AND
____________________
00100 (result = 4) |
您可以使用掩码值来检查是否已设置某些位。如果我们想检查第 1 位和第 3 位是否已设置,我们可以用 10(位 1 和 3 的值)屏蔽该数字,并根据掩码测试结果。
#include <stdio.h>
int main()
{
int num, mask = 10;
printf("Enter a number: ");
scanf("%d", &num);
if ((num & mask) == mask)
puts("Bits 1 and 3 are set");
else
puts("Bits 1 and 3 are not set");
return 0;
}
按位或
如果设置了任一位,则按位或为真。下面显示了对数字 23 和 12 进行按位或运算的结果。
| 10111 (23)
01100 (12) OR
______________________
11111 (result = 31) |
您可以使用掩码来确保已设置一个或多个位。以下示例确保设置了位 2。
#include <stdio.h>
int main()
{
int num, mask = 4;
printf("Enter a number: ");
scanf("%d", &num);
num |= mask;
printf("After ensuring bit 2 is set: %d\n", num);
return 0;
}
按位异或
如果设置了任一位,则按位异或为 True,但不能同时设置。下面显示了对数字 23 和 12 进行按位异或的结果。
| 10111 (23)
01100 (12) Exclusive OR (XOR)
_____________________________
11011 (result = 27) |
异或有一些有趣的特性。如果你对一个数字进行异或运算,它会将自身设置为零,因为零将保持为零,而不能同时设置为零。
因此,如果您将一个数字与另一个数字进行异或,然后再次将结果与另一个数字异或,结果就是原始数字。您可以使用上面示例中使用的数字进行尝试。
23 XOR 12 = 27
27 XOR 12 = 23
27 XOR 23 = 12
此功能可用于加密。下面的程序使用 23 的加密密钥来说明用户输入的数字的属性。
#include <stdio.h>
int main()
{
int num, key = 23;
printf("Enter a number: ");
scanf("%d", &num);
num ^= key;
printf("Exclusive OR with %d gives %d\n", key, num);
num ^= key;
printf("Exclusive OR with %d gives %d\n", key, num);
return 0;
}
按位恭维
按位 Compliment 是一个补语运算符,用于打开或关闭位。如果为 1,则设置为 0,如果为 0,则设置为 1。
#include <stdio.h>
int main()
{
int num = 0xFFFF;
printf("The compliment of %X is %X\n", num, ~num);
return 0;
}
按位左移
Bitwise Shift Left 运算符将数字左移。随着数字向左移动,最高有效位丢失,空出的最低有效位为零。下面是43的二进制表示。
0101011(十进制 43)
通过将位向左移动,我们丢失了最高有效位(在本例中为零),并且该数字在最低有效位处用零填充。以下是结果数字。
1010110(十进制 86)
按位右移
按位右移运算符将数字右移。将零引入空出的最高有效位,并且空出的最低有效位丢失。下面是数字 43 的二进制表示。
0101011(十进制 43)
通过将位向右移动,我们丢失了最低有效位(在本例中为 1),并且该数字在最高有效位用零填充。以下是结果数字。
0010101(十进制 21)
以下程序使用按位右移和按位与将数字显示为 16 位二进制数。该数字从 16 连续右移到 0,并与 1 进行按位与运算,以查看该位是否已设置。另一种方法是使用带有按位或运算符的连续掩码。
#include <stdio.h>
int main()
{
int counter, num;
printf("Enter a number: ");
scanf("%d", &num);
printf("%d is binary: ", num);
for (counter=15; counter>=0; counter--)
printf("%d", (num >> counter) & 1);
putchar('\n');
return 0;
}
二进制 - 十进制转换函数
下面给出的两个函数用于二进制到十进制和十进制到二进制的转换。下面给出的将十进制数转换为相应二进制数的函数最多支持 32 位二进制数。您可以根据您的要求使用这个或之前给出的程序进行转换。
十进制到二进制转换的功能:
void Decimal_to_Binary(void)
{
int input =0;
int i;
int count = 0;
int binary [32]; /* 32 Bit, MAXIMUM 32 elements */
printf ("Enter Decimal number to convert into
Binary :");
scanf ("%d", &input);
do
{
i = input%2; /* MOD 2 to get 1 or a 0*/
binary[count] = i; /* Load Elements into the Binary Array */
input = input/2; /* Divide input by 2 to decrement via binary */
count++; /* Count how many elements are needed*/
}while (input > 0);
/* Reverse and output binary digits */
printf ("Binary representation is: ");
do
{
printf ("%d", binary[count - 1]);
count--;
} while (count > 0);
printf ("\n");
}
二进制转十进制函数:
下面的函数是将任意二进制数转换为其对应的十进制数:
void Binary_to_Decimal(void)
{
char binaryhold[512];
char *binary;
int i=0;
int dec = 0;
int z;
printf ("Please enter the Binary Digits.\n");
printf ("Binary digits are either 0 or 1 Only ");
printf ("Binary Entry : ");
binary = gets(binaryhold);
i=strlen(binary);
for (z=0; z<i; ++z)
{
dec=dec*2+(binary[z]=='1'? 1:0); /* if Binary[z] is
equal to 1,
then 1 else 0 */
}
printf ("\n");
printf ("Decimal value of %s is %d",
binary, dec);
printf ("\n");
}
调试和测试
语法错误
句法是指语句中元素的语法、结构和顺序。当我们违反规则时会发生语法错误,例如忘记用分号结束语句。当你编译程序时,编译器会生成一个它可能遇到的任何语法错误的列表。
一个好的编译器会输出带有错误描述的列表,并可能提供一个可能的解决方案。修复错误可能会导致重新编译时显示更多错误。原因是之前的错误改变了程序的结构,这意味着在最初的编译过程中进一步的错误被抑制了。
同样,一个错误可能会导致多个错误。尝试将分号放在可以正确编译和运行的程序的 main 函数的末尾。当你重新编译它时,你会得到一个巨大的错误列表,但它只是一个放错位置的分号。
除了语法错误,编译器也可能发出警告。警告不是错误,但可能会在程序执行期间引起问题。例如,将双精度浮点数分配给单精度浮点数可能会导致精度损失。这不是语法错误,但可能会导致问题。在这个特定示例中,您可以通过将变量转换为适当的数据类型来显示意图。
考虑以下示例,其中 x 是单精度浮点数,y 是双精度浮点数。 y 在赋值期间被显式转换为浮点数,这将消除任何编译器警告。
x = (float)y;
逻辑错误
逻辑错误时会发生逻辑错误。例如,您可以测试一个数字是否小于 4 和大于 8。这不可能是真的,但如果语法正确,程序将成功编译。考虑以下示例:
if (x < 4 && x > 8)
puts("Will never happen!");
语法是正确的,所以程序会编译,但是 puts 语句永远不会被打印出来,因为 x 的值不可能同时小于 4 和大于 8。
大多数逻辑错误是通过程序的初始测试发现的。当它的行为与您的预期不同时,您可以更仔细地检查逻辑语句并更正它们。这仅适用于明显的逻辑错误。程序越大,通过它的路径就越多,验证程序是否按预期运行就变得越困难。
测试
在软件开发过程中,可以在开发的任何阶段注入错误。这是因为软件开发早期阶段的验证方法是手动的。因此,除了在编码活动期间引入的错误外,在编码活动期间开发的代码可能还存在一些需求错误和设计错误。在测试期间,要测试的程序与一组测试用例一起执行,并评估测试用例的程序输出以确定程序是否正在执行。
因此,测试是分析软件项以检测现有条件和所需条件(即错误)之间的差异并评估软件项功能的过程。因此,测试是分析程序以发现错误的过程。
一些测试原则
- 测试不能显示没有缺陷,只能显示它们的存在。
- 越早犯错,代价越高。
- 越晚发现错误,代价越高。
现在让我们讨论一些测试技术:
白盒测试
白盒测试是一种技术,通过该技术,通过程序的所有路径都使用每个可能的值进行测试。这种方法需要一些关于程序应该如何运行的知识。例如,如果您的程序接受 1 到 50 之间的整数值,则白盒测试将使用所有 50 个值测试程序,以确保每个值都正确,然后测试整数可能取的所有其他可能值并测试它的行为符合预期。考虑到一个典型程序可能拥有的数据项的数量,可能的排列使得大型程序的白盒测试极其困难。
白盒测试可应用于大型程序的安全关键功能,其余大部分使用黑盒测试进行测试,如下所述。由于排列的数量,白盒测试通常使用测试工具执行,其中值范围通过特殊程序快速馈送到程序,记录预期行为的异常。白盒测试有时被称为结构测试、清晰测试或开箱测试。
黑盒测试
黑盒测试类似于白盒测试,除了不是测试每个可能的值,而是测试选定的值。在这种类型的测试中,测试人员知道输入和预期的结果应该是什么,但不一定知道程序是如何达到这些结果的。黑盒测试有时也称为功能测试。
黑盒测试的测试用例通常在程序规范完成后立即设计。测试用例基于等价类。
等价类
对于每个输入,一个等价类标识有效和无效状态。在定义等价类时,通常需要规划三种方案。
如果输入指定范围或特定值,则将有一个有效状态,并定义两个无效状态。例如,如果一个数字必须在 1 到 20 之间,则有效状态在 1 到 20 之间,小于 1 为无效状态,大于 20 为无效状态。
如果输入不包括范围或特定值,则将有两种有效状态和一种无效状态定义。例如,如果一个数字不能介于 1 和 20 之间,则有效状态为小于 1 且大于 20,无效状态为 1 和 20 之间。
如果输入指定一个布尔值,则只有两种状态,一种有效,一种无效。
边界值分析
边界值分析仅考虑输入边界处的值。例如,在数字介于 1 和 20 之间的情况下,测试用例可能是 1、20、0 和 21。其背后的想法是,如果程序使用这些值按预期工作,其他值也会按预期工作。
下表概述了您可能想要识别的典型边界。
| Testing Ranges |
| Input type |
Test Values |
| Range |
- x[lower_bound]-1
- x[lower_bound]
- x[upper_bound]
- x[upper_bound]+1
|
| Boolean |
|
制定测试计划
确定等价类,并为每个类确定边界。确定类的边界后,在边界上写下有效和无效值的列表,以及预期的行为应该是什么。然后测试人员可以使用边界值运行程序,并指出当根据所需结果测试边界值时发生了什么。
以下可能是一个典型的测试计划,用于检查输入的年龄,其中可接受的值在 10 到 110 的范围内.
| Equivalence Class |
| Valid |
Invalid |
| Between 10 and 110 |
> 110 |
|
< 10 |
在定义了我们的等价类之后,我们现在可以为年龄设计一个测试计划。
| Test Plan |
| Value |
State |
Expected Result |
Actual Result |
| 10 |
Valid |
Continue execution to get name |
|
| 110 |
Valid |
Continue execution to get name |
|
| 9 |
Invalid |
Ask for age again |
|
| 111 |
Invalid |
Ask for age again |
|
“实际结果”列留空,因为它将在测试时完成。如果结果符合预期,该列将被打勾。如果不是,则应输入说明所发生情况的注释。

 Home
Home